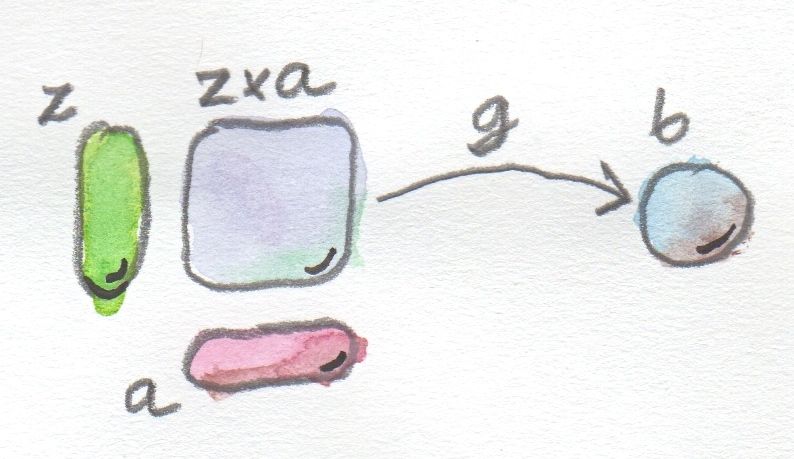I came in contact with Tambara modules when working on a categorical understanding of lenses. They were first mentioned to me by Edward Kmett, who implemented their Haskell version, Data.Profunctor.Tambara. Recently I had a discussion with Russell O’Connor about profunctor lenses. He then had a discussion with James “xplat” Deikun, who again pointed out the importance of Tambara modules. That finally pushed me to study Tambara’s original paper along with Pastro and Street’s generalizations of it. These are not easy papers to read; so, to motivate myself, I started writing this post with the idea of filling in the gaps in my education and providing some background and intuitions I gather in the process. Trying to explain things always helps me understand them better. I will also sketch some of the proofs — for details, see the original papers.
The general idea is that lenses are used to access components of product data types, whereas prisms are used with coproduct (sum) data types. In order to unify lenses and prisms, we need a framework that abstracts over products and coproducts. It so happens that both are examples of a tensor product. Tensors have their roots in vector calculus, so I’ll start with a little refresher on it, to see where the intuitions come from. Tensors may also serve as objects upon which we can represent groups or monoids.
The next step is to define a monoidal category, where the tensor product plays a role analogous to group (actually, monoid) action. Tensor categories are built on top of (or, enriched over) monoidal categories.
We can define monoidal action on tensor categories — analogous to representations of groups on tensor fields. One particular tensor category of interest to us is the category of distributors (profunctors). Distributors equipped with a tensor action are the subject of Tambara’s paper. It turns out that tensor action on distributors is directly related to profunctor strength, which is the basis of the general formulation of Haskell lenses and prisms.
Vectors and Tensors
We all have pretty good idea of what a vector space is. It’s a sets of vectors with vector addition and with multiplication by numbers. The numbers, or scalars, come from some field K (for instance real or complex numbers). These operations must obey some obvious rules. For instance, multiplying any vector by 1 (the multiplicative unit of K) gives back the same vector:
1v = v
Then there are the linearity conditions (α and β are scalars from K, and v and w are vectors):
αv + βv = (α + β)v α(v + w) = αv + αw
which can be used to prove that every vector space has a basis — a minimal set of vectors whose linear combinations generate the whole space.
In other words, any vector v can be written as a combination of base vectors ei:
v = Σ αiei
where Σ represents the sum over all is.
Or we can go the other way: We can start with a set B that we call the base set, define formal addition and multiplication, and then create a free structure containing all formal combinations of base vectors. Our linearity laws are then used to identify equivalent combinations. This is called a free vector space over B. The advantage of this formulation is that it generalizes easily to tensor spaces.
A tensor space is created from two or more vector spaces. The elements of a tensor space are formal combinations of elements from the constituent vector spaces. Those “formal combinations” can be described in terms of a tensor product. A tensor product V ⊗ W of two vector spaces is a mapping of the cartesian product V × W (a set of pairs of vectors) to the free vector space built on top of V and W, with the appropriate identifications:
(v, w) + (v', w) = (v + v', w) (v, w) + (v, w') = (v, w + w') α(v, w) = (αv, w) = (v, αw)
A tensor product can also be defined for mappings between vector spaces. Given four vector spaces, V, W, X, Y, we can consider linear maps between them:
f :: V -> X g :: W -> Y
The tensor product of these maps is a linear mapping between tensor products of the appropriate spaces:
(f ⊗ g) :: V ⊗ W -> X ⊗ Y (f ⊗ g)(v ⊗ w) = (f v) ⊗ (g w)
Vector spaces form a category Vec with linear maps as morphisms. Tensor product can then be defined as a bifunctor from the product category Vec × Vec to Vec (so it also maps pairs of morphisms to morphisms).
Given a vector space V, we can also define a dual space V* of linear functions from V to K (remember, K is the field from which we get our scalars). The action of an element f of V* on a vector v from V is called evaluation (or, in physics, contraction):
eval :: V* ⊗ V -> K eval f v = f v
Given a basis ei in V, the canonical basis in V* is a set of functions e*i such that:
eval e*i ej = δij
where δij is 1 for i=j and 0 otherwise (the Kronecker delta). Seen as a matrix, δ is a unit matrix. It almost looks like the dual space provides the “inverses” of vectors. This is an important intuition.
A general tensor space supports tensor products involving a mixture of vectors and dual vectors (linear maps). In physics, this allows the construction of mixed covariant and contravariant tensors.
The dual to evaluation is called co-evaluation. In finite dimensional vector spaces, it’s a mapping:
coeval :: K -> V ⊗ V* coeval α = Σ α ei ⊗ e*i
It takes a scalar α and creates a tensor using basis vectors and their duals. Tensors can be summed and multiplied by scalars.
One obvious generalization of vector (and tensor) spaces is to replace the field K with a ring. A ring has addition, subtraction, and multiplication, but it doesn’t have division.
Groups and Monoids
Groups were originally introduced in terms of actions on vector spaces. The action of a group element g on a vector v maps it to another vector in the same vector space. This mapping is linear:
g (αv + βw) = α (g v) + β (g w)
Because of linearity, group action is fully determined by the transformation of basis vectors. An element of a group acting on a vector v=Σviei produces a vector w that can be decomposed into components w=Σwiei:
wi = Σ gij vj
The numbers gij form a square matrix. The mapping of group elements to these matrices is called the representation of the group. The group of rotations in two dimensions, for instance, can be represented using 2×2 matrices of the form:
| cos α sin α | | -sin α cos α |
This is an example of a representation of an infinite continuous group called SO(2) (Special Orthogonal group in 2-d).
Applying a group element to a vector produces another vector that can be acted upon by another group element, and so on. You can forget about elements acting on vectors and define group multiplication abstractly. A group is a (potentially infinite) set of elements with a binary operation that is associative, has a neutral (identity) element, and an inverse for every element. It turns out that the same group may have many representations in vector spaces. Associativity and identity in the group happen also to be the basic properties defining a category — invertibility, though, is not. It should come as no surprise that categorists prefer the simpler monoid structure and consider a group a more specialized versions of it.
You get a monoid by abandoning the requirement that all elements of a group have an inverse. Or, even more abstractly, you can define a monoid as a single-object category, where the composition of (endo-) morphisms defines multiplication, and the identity morphism is the neutral element. These two definitions are equivalent because endomorphisms form a set — the hom-set — that can be identified with the set of elements of the monoid. The hom-set has composition of endomorphisms, which can be identified with the binary monoidal operation.
Some groups and monoids are commutative (for instance integer addition); others are not (for instance string concatenation). The commutative subgroup or submonoid is called the center of the group or monoid. Elements of the center must commute with all elements of the group, not only among themselves.
You may also think of representing a group (or a monoid) as acting on itself. There are two ways of doing that: the left action and the right action. The action of a group element g can be represented as transforming the whole group by multiplying each element by g on the left:
Lg h = g * h
or on the right:
Rg h = h * g
Such a transformation results in a reshuffling of the elements of the group. Each g defines a different reshuffling. A reshuffling (for finite sets) is called a permutation, and one of the fundamental theorems in group theory, due to Cayley, says that every group is isomorphic to some permutation group.
Cayley’s theorem can be generalized to monoids. Instead of the reshuffling of elements we then talk about endomorphisms. Every monoid defined as a set M with multiplication and unit can be represented as a submonoid of endomorphisms of that set.
This equivalence is well know to Haskell programmers. Monoid multiplication may be represented as a binary function (multiplication):
mappend :: (M, M) -> M
or, after currying, as a function returning an endomorphism:
mappend :: M -> (M -> M)
The unit element, mempty becomes the identity endomorphism, id.
Monoidal Category
We’ve seen that a monoid can be defined as a set of elements with a binary operation, or as a single-object category. The next step in this ladder of abstractions is to rethink the idea of forming pairs of elements for a binary operation. When dealing with sets, the pairs are just elements of the cartesian product.
In a more general categorical setting, cartesian product may be replaced with categorical product. Multiplication is just a morphism from the product m×m to the object itself m. But how do we select the unit element of m? Categorical objects have no structure. So instead we use a generalized element, which is defined as a morphism from the terminal object (in set, that would be the singleton set) to m.
A monoid can thus be defined as an object m in a category that has products and the terminal object t together with two morphisms:
mult :: m × m -> m unit :: t -> m
But what if the category C in which we are trying to define a monoid doesn’t have a product or the terminal object? No problem! Instead of categorical product we’ll define a bifunctor ⊗:
⊗ :: C × C -> C
It’s a functor from the product category C×C to C. It’s called a tensor product by analogy with the vector space construction we started with. As a functor, it also defines a mapping of morphisms.
Instead of the terminal object, we just pick one special object i and define a generalized unit as a morphism from i to m.
The tensor products must fulfill some obvious conditions like associativity and the unit laws. We could define them by equalities, e.g.,
(a ⊗ b) ⊗ c = a ⊗ (b ⊗ c) i ⊗ a = a = a ⊗ i
The snag is that our prototypical tensor product, the cartesian product, doesn’t satisfy those identities. Consider the Haskell implementation of the cartesian product as a pair type, with the unit element as the unit type (). It’s not exactly true that:
((a, b), c) = (a, (b, c)) ((), a) = a = (a, ())
However, it’s almost true. The types on both sides of the equations are isomorphic, as can be shown by defining polymorphic functions that mediate between those terms. In category theory, those polymorphic functions are replaced by natural transformations.
A category in which associativity and unit laws of the tensor product can be expressed as equalities is called a strict monoidal category. A category in which these laws are imposed only up to natural isomporphisms is called non-strict monoidal category. The three isomorphisms are called the associator α, the left unitor λ, and the right unitor ρ, respectively:
α :: (a ⊗ b) ⊗ c -> a ⊗ (b ⊗ c) λ :: i ⊗ a -> a ρ :: a ⊗ i -> a
(They all must have inverses.)
A useful example of a strict monoidal category is the category of endofunctors of some category C. We use functor composition for tensor product. Composition of two endofunctors F and G is always well defined and it produces another endofunctor G∘F. The unit of this monoidal category is the identity functor Id. Strict associativity and unit laws follow from the definition of functor composition and the definition of the identity functor.
In some categories it’s possible to define an exponential object ab, which represents a set of morphisms from b to a. The standard way of doing it is through the adjunction:
C(a × b, c) ≅ C(b, ca)
Here, C(x, y) represents the hom-set from x to y. The two hom-sets in the adjunction must be naturally isomorphic. In general, an adjunction is between two functors L and R:
C(L b, c) ≅ C(b, R c)
Here the two functors are:
La b = a × b Ra c = ca
This definition of the exponential object can be extended to monoidal categories by replacing categorical product with the tensor product:
C(a ⊗ b, c) ≅ C(b, ca)
In a monoidal category we can also define a left exponential:
C(a ⊗ b, c) ≅ C(a, bc)
(if the tensor product is symmetric, or weakly symmetric — up to a natural isomorphism — these two exponentials coincide).
There is an equivalent definition of an adjunction through unit η and counit ε — two natural transformations. These transformations are between the composition of two adjoint functors and the identity functor:
η :: Id -> R ∘ L ε :: L ∘ R -> Id
This comes even closer to convincing us that exponentiation is the inverse of a product.
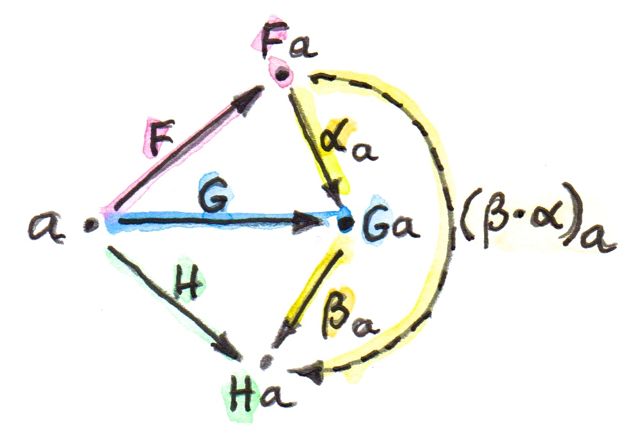
As it often happens, having equivalent definitions of the same thing may lead to different generalizations. We’ve seen that the category of endofunctors in some category C is a (strict) monoidal category. We can pick two endofunctors F and G and define two natural transformations:
ε :: G ∘ F -> Id η :: Id -> F ∘ G
If such transformations exist, the pair F and G form an adjunction, F being left adjoint to G.
This definition can be extended to any monoidal product, not just composition. In a tensor category A, we have the unit object i, and we can try to define two morphisms:
ε :: a ⊗ a' -> i η :: i -> a' ⊗ a
The pair of objects a and a' together with the morphisms ε and η are called a duality. A category is called rigid or autonomous if there is a dual for every object. A duality gives rise to an adjunction:
Hom(ax, y) ≅ Hom(x, a'y)
Comparing this with the exponential adjunction, we see that the dual of a acting on y plays the role of ya. In other words, a' says: raise the object that I’m multiplying to the power of a.
There may be many duals of a, but we can always choose one and denote it as ac. Multiplying it by y, acy is analogous to taking the exponential ya. It also works like a weak inverse of a because of:
ε :: a ac -> i η :: i -> ac a
Notice that the duality functor, the mapping from a to ac, is contravariant in a.
Tambara works with rigid categories, whereas Pastro and Street mostly work with closed categories — with exponentials defined for every pair of objects.
Enriched Categories
In traditional category theory hom-sets are just sets. It’s possible, though, to replace hom-sets with something with more structure. Tambara, for instance, uses vector spaces for his hom-sets. In general, hom-sets may be replaced by objects in some other base category — this results in the notion of an enriched category. This base category must have some additional structure in order to support composition in the enriched category.
Composition of morphisms in a regular category is defined in terms of elements of hom-sets. It’s a mapping from a pair of composable morphisms to a morphism. Objects in an arbitrary category might not support the notion of “elements.” So we have to express composition in terms of entire hom-objects rather than their individual elements. The minimal structure necessary for that is a monoidal category. Instead of pairs of morphisms, we’ll operate on a whole (monoidal) product of two hom-objects. Composition is then a morphism in the base category V:
∘ :: A(b, c) ⊗ A(a, b) -> A(a, c)
Here, A(a, b) is an object in V — the hom-object from a to b. Associativity of composition reflects the associativity of the monoidal product (it may be weak!).
Identity morphisms are then “picked” in any A(a, a) by a morphism in V:
ida :: i -> A(a, a)
where i is the unit object in V. That’s the same trick we used to define generalized elements of objects in a monoidal category. Again, unit laws may be weak.
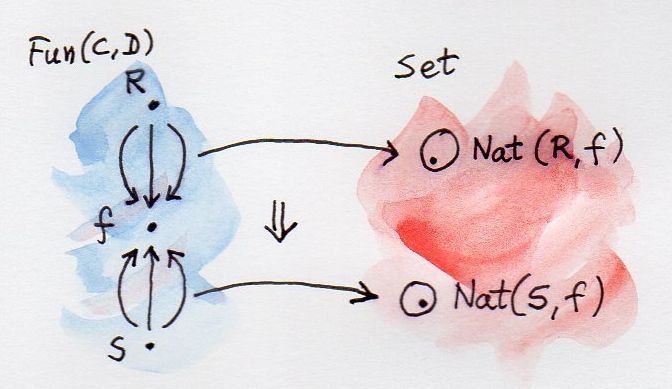
The main purpose of defining categories is to enable the definitions of functors and natural transformations. Functors map objects and morphisms, so in enriched categories, they have to map objects and hom-objects. Therefore it only makes sense to define enriched functors between categories that are enriched over the same base monoidal category, because that’s where the hom-objects live. An enriched functor must preserve composition — which is defined in terms of the monoidal product — and the identity morphism, which is defined in terms of the monoidal unit.
Similarly, it’s possible to define a natural transformation between two enriched functors F and G that go between two V-enriched categories A and B. The naturality square turns into a naturality hexagon that connects the object A(a, a’) to the object B(F a, G a’) in two different ways. Normally, components of a natural transformation are morphisms between F a and G a. In the enriched setting, there is no way to “pick” individual morphisms. Instead we use morphisms from the identity object in V — generalized elements of hom-objects.
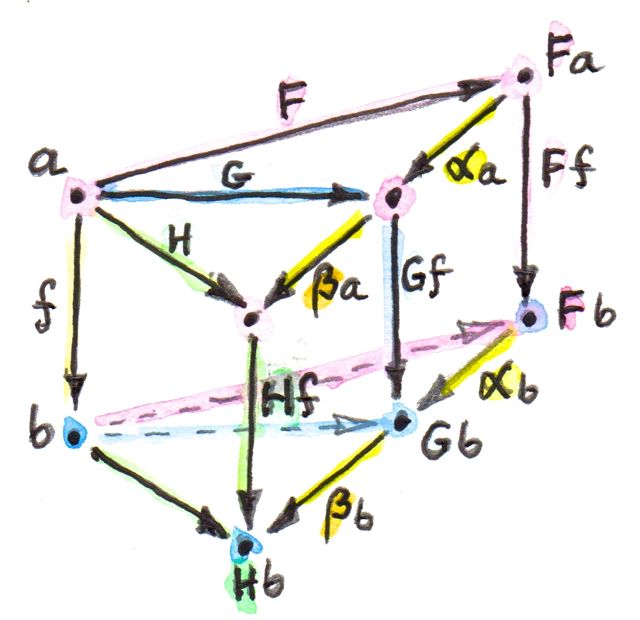
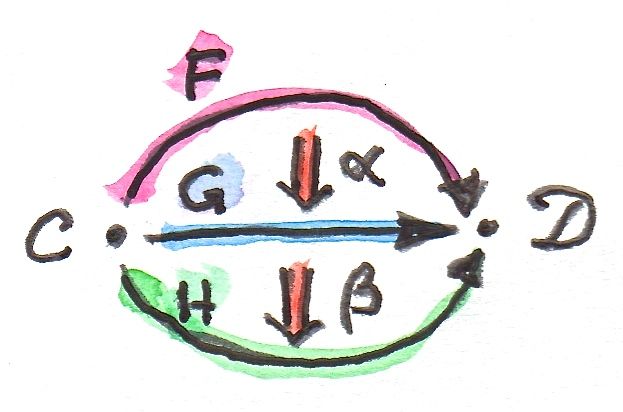
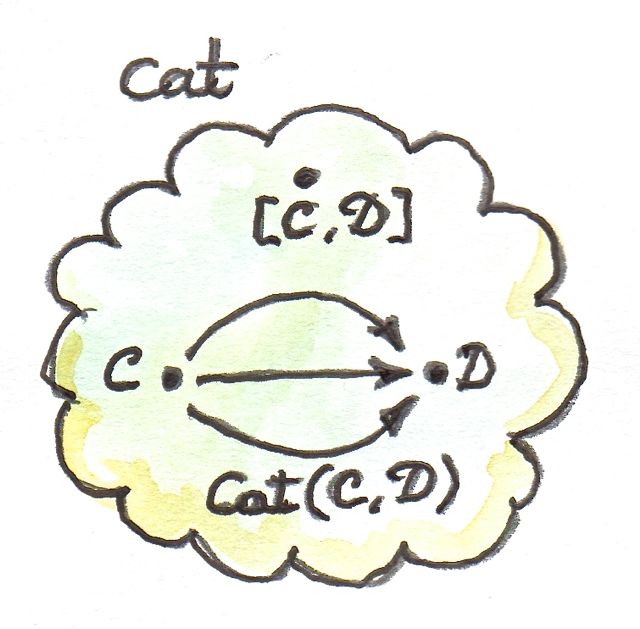
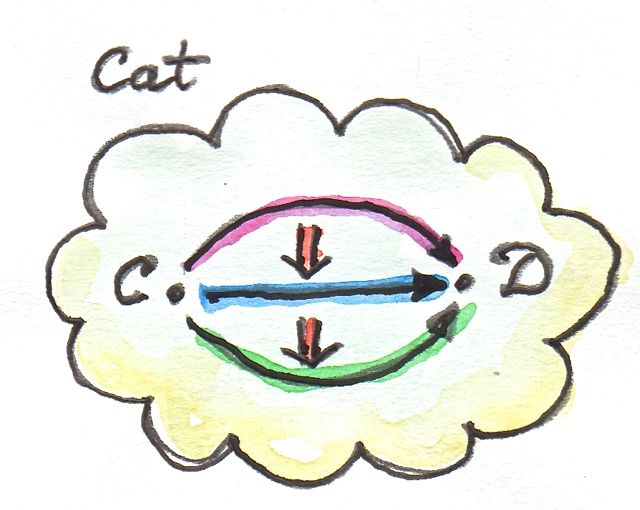
Functors between two given categories A and B (enriched or not) form a category, with natural transformations as morphisms. On the other hand, functors are morphisms in the category Cat of (small) categories. The set of functors between two categories A and B is therefore both a hom-set in Cat and a category. Tambara denotes those hom-categories Hom(A, B). I will use this notation throughout. Otherwise, for hom-sets (and hom-objects in the enriched case) I will use the standard notation C(a, b), where C is the category, and a and b are objects in C.
The starting point of both Tambara and Pastro/Street is a tensor category A. It’s a category enriched over a monoidal category V. There is a separate tensor product defined in A. In Tambara, V is the category of vector spaces with the usual tensor product. In Pastro/Street, V is an arbitrary monoidal category.
Without loss of clarity, the tensor product in A is written without the use of any infix operator. For two objects x and y of A, the product is just xy. A tensor product of two morphisms f::x->x' and g::y->y' is denoted, in Tambara, as fg::xy->x'y' (not to be confused with composition f'∘f). Tambara assumes that associativity and unit laws in A are strict.
Summary
We have the following layers of abstraction:
- V is a monoidal category
- A is a tensor category enriched over V.
Modules
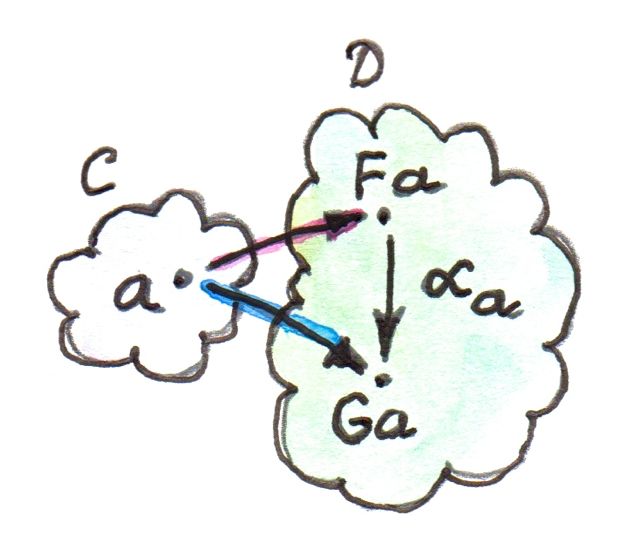
By analogy with groups and vector spaces, we would like to define the action of a tensor category A on some other category X. As before, we have the choice between left and right action (or both). Let’s start with the left action. It’s a bifunctor:
A × X -> X
In components, the notation is simplified to (no infix operator):
<a, x> -> ax
where a is an object in A and x is an object in X
We want this functor to be associative and unital. In particular:
ix = x
where i is the unit in the tensor category A. The category X with these properties is called a left A module.
Similarly, the right B module is equipped with the functor:
X × A -> X
The interesting case is a bimodule with two bifunctors:
A × X -> X X × B -> X
The two tensor categories A and B may potentially be different (although they both must be enriched over the same category V as X).
Notice that A itself is a bimodule with both left and right action of A on A defined by the (tensor) product in A.
The usual thing in category theory is to introduce structure-preserving functors between similar categories.
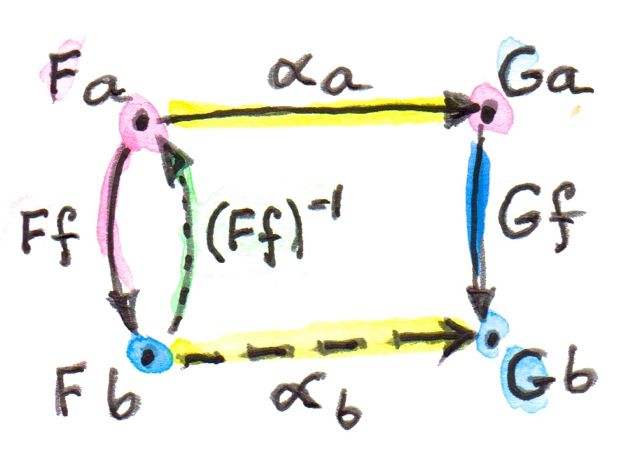
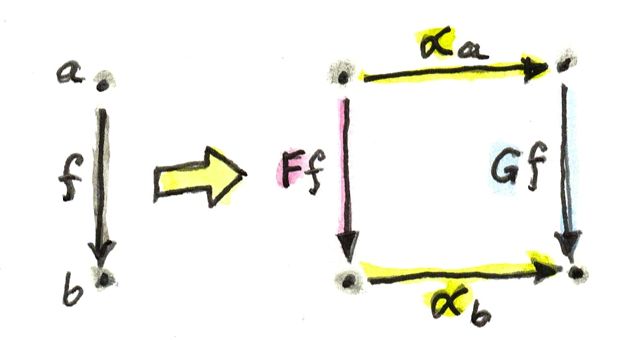
So, if X and Y are two left modules over the same tensor category A, we can define A-linear functors that preserve the action of A. Such functors, in turn, form a category that Tambara calls HomA(X, Y) (notice the subscript A). Linearity in this case means that the left action weakly commutes with the functor. In other words, we have a natural isomorphism (here again, left action is understood without any infix operator):
λa, x :: F (ax) -> a(F x)
This mapping is invertible (it’s an isomorphism).
The same way we can define right- and bi- linear functor categories. In particular an (A, B)-linear functor preserves both the left and the right actions. Tambara calls the category of such functors HomA, B(X, Y). Linearity in this case means that we have two natural isomorphisms:
λa, x :: F (ax) -> a(F x) ρx, b :: F (xb) -> (F x)b
The first result in Tambara’s paper is that, if X is a right A-module, then the category of right linear functors HomA(A, X) from A to X is equivalent to X.
The proof is quite simple. Right to left: Pick an object x in X. We can map it to a functor:
Gx :: A -> X
defined as the right action of a on x:
Gx a = xa
Its linearity is obvious:
ρa, b :: Gx (ab) -> (Gx a)b
Notice also that evaluating Gx on the identity i of A produces x. So, left to right, we can define the inverse mapping from HomA(A, X) to X as the evaluation of the functor at i.
The intuition from group theory is that the (right, in this case) action of the whole group on a fixed x creates an orbit in X. An orbit is the set of points (vectors) that can be reached from x by acting on it with all group elements (imagine a group of rotations around a fixed axis in 3-d — here, orbits are just circles). In our case, we can get an orbit of any x as the image of a linear functor Gx defined above that goes from A (the equivalent of the group) to X (the equivalent of the vector space in which we represent the group). It so happens that the image of any linear functor G from A to X is an orbit. It’s the orbit of the object G i. Any object in the image of G can be reached from G i by the action of some object of A. The image of G consists of objects of the form G a. G a can be rewritten as G (ia) which, by (right) linearity, is the same as (G i)a.
Our intuition that there should be more functors from A to X than there are objects in X fails when we impose the linearity constraint. The functors in HomA(A, X) are no longer linearly independent. There is a “basis” in that “space” that is in one-to-one correspondence with the objects of X.
A similar proof works for left modules.
The situation is trickier for bimodules with both left and right action, even if we pick the same tensor category on both sides, that is work with an (A, A)-bimodule.
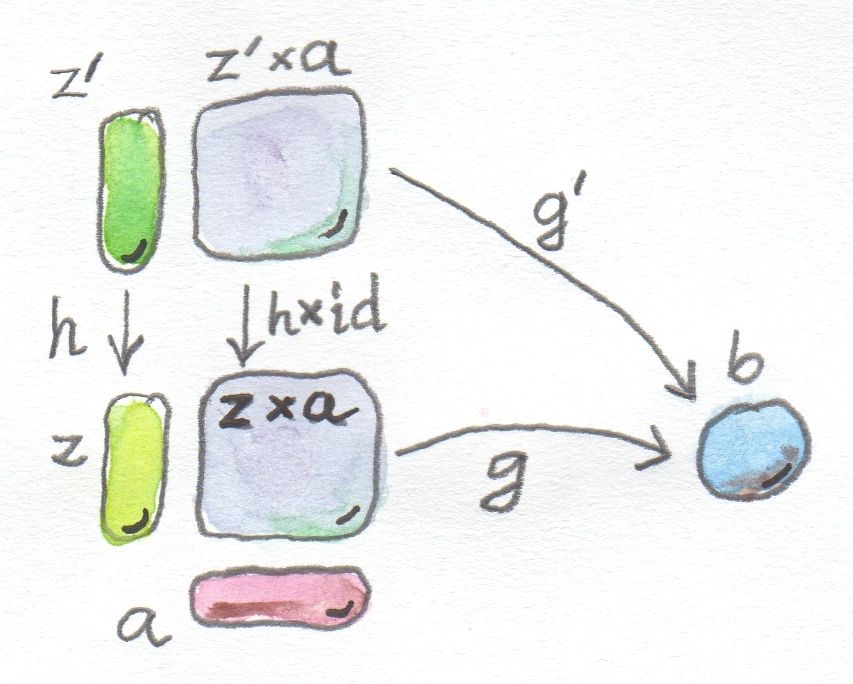
Suppose that we wanted to map X to HomA, A(A, X). We can still define the (orbit of x) functor Gx as xa with the same ρab. But there is a slight problem with defining λba. We want:
λb a :: Gx (ba) -> b(Gx a)
which will work if there is a transformation:
xba -> bxa
We would like x to (weakly) commute with b. By analogy with the center of a group, we can define a centralizer ZA(X) as the category of those objects of X for which there is an isomorphism ωa between ax and xa. The equivalence of categories in this case is:
HomA,A(A, X) ≅ ZA(X)
So, for any object x that’s in the centralizer of X, we can define our Gx as xa. Conversely, for any (A, A)-linear functor, we can evaluate it at i to get an object of X. This object can be shown to be a member of the centralizer because, for any F in HomA, A(A, X):
a(F i) = F (a i) = F (i a) = (F i)a
Summary
We have the following layers of abstraction:
- V is a monoidal category
- A (and B) are tensor categories enriched over V
- X is a category enriched over V
- X is a module, if the action of A is defined over X (left, right, or both)
- Linear functors between X and Y preserve left, right, or bi actions of A (or B).
In particular, bilinear functors from A (with the left and right action of A) to a bimodule X are in one to one correspondence with the centralizer ZA(X) of X under the action of A.
Distributors
To understand distributors, it helps to know a bit about calculus and/or signal processing. In calculus we deal with functions. Functions can be integrated. We can also have functions acting on functions — or functionals. In particular we can have linear functions on functions. It turns out that a lot of such functionals can be defined through integrals. A linear functional can be expressed as integration of test functions with some density. A density may be a function of two arguments, but a general linear functional may require a generalized density. For instance, the famous Dirac delta “function” cannot be represented as a function, although physicists often write:
f(x) = ∫ δ(x - y) f(y) dy
Such generalized functions are called distributions. Direct multiplication of distributions is ill-defined — the annoying infinities that crop up in quantum field theory are the result of attempts to multiply quantum fields, which are distributions.
A better product can be defined through convolution. Convolutions happen to be at the core of signal processing. If you want to soften an image, you convolve it with a Gaussian density. Convolution with a delta function reproduces the original image. Edge enhancement is done with the derivative of a delta function, and so on.
Convolutions can be generalized to functions over groups:
(f ★ g)(x) = ∫ f(y) g(y-1x) dλ(y)
where λ is a suitable group measure.
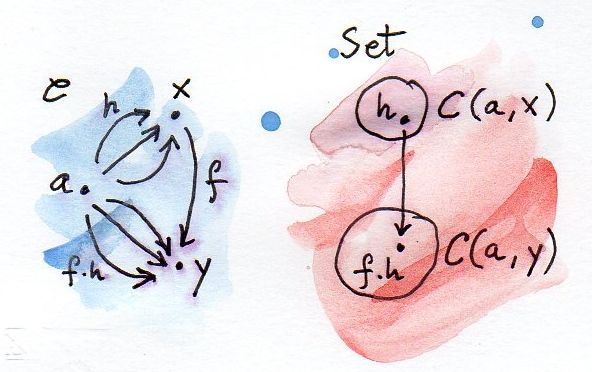
Roughly speaking, distributors are to functors as distributions are to functions. You might know distributors under the name of profunctors. A profunctor is a functor of two arguments, one of them from the opposite category.
p :: Xop × Y -> Set
In a way, a profunctor is a generalization of a bifunctor, at least when acting on objects. When acting on morphisms, a profunctor is contravariant in one argument and covariant in another. In the case of Y being the same as X, this is similar to the hom-functor C(a, b) being contravariant in a and covariant in b. A hom-functor is the simplest example of a profunctor. As we’ll see later, it’s even possible to model the composition of profunctors on composition of hom-functors.
A profunctor acting on two objects produces a set, an object in the Set category (again, generalizing a hom-functor, which is also Set-valued). Acting on a pair of morphisms (which is the same as a single morphism in the product category Xop × Y), a profunctor produces a function.
Distributors can be generalized to categories that are enriched over the same monoidal category V. In that case they are V-valued functors from Xop × Y to V.
Since distributors (profunctors) are functors, they form a functor category denoted by D(X, Y). Objects in a distributor category are (enriched) functors:
Xop × Y -> V
and morphisms are (enriched) natural transformations.
On the other hand, we can treat a distributor as if it were a morphism between categories (it has the right covariance for that). The composition of such morphisms is defined through the coend formula (a coend for profunctors is analogous to a colimit for functors):
(p ∘ q) x y = ∫z (p x z) ⊗ (q z y)
Here, p and q are distributors:
p :: (Xop × Z) -> V q :: (Zop × Y) -> V
The tensor product ⊗ is the product in V (here we explicitly use the infix operator). We “integrate” over the object z in the middle.
This way we can define a bicategory Dist of categories where distributors are morphisms (one-cells) and natural transformations are two-cells. If we also consider regular functors between categories, we get what is called a double category (not to be confused with a 2-category or a bicategory, which are all slightly different).
There is an equivalent way of looking at distributors as a generalization of relations. A relation between two sets is a subset of pairs of elements from those sets. We can model this categorically by treating a set as a discrete category of elements (no morpisms other than identities). The relation between two such sets is a set of formal arrows between their elements — when two elements are related, there is a single arrow between them, otherwise there’s no arrow. Now we can replace sets by categories and define a relation as a bifunctor from those categories to Set. An object from category X is “related” to an object from Y if the bifunctor in question maps them into a non-empty set, otherwise they are unrelated. Since there are many non-empty sets to chose from, there may be many “levels” of relation: ones corresponding to a singleton set, a dubleton, and so on.
We also have to think about the mapping of (pairs of) morphisms from the two categories. Since we would like the opposite relation to be a functor from opposite categories, the symmetric choice is to define a relation as a functor that is contravariant in one argument and covariant in the other — in other words, a profunctor. That way the opposite relation will still be a profunctor, albeit with ops reversed.
One can define the composition of relations. If p relates X to Z and q relates Z to Y then we say that an object x from X is related to an object y from Y if and only if there exists an object z of Z (an object in the middle) such that x is related to z and z is related to y. This existential qualification of z is represented, in category theory, as a coend (an end corresponding to the universal qualifier). Thus, through composition of relations, we recover the formula for the composition of profunctors:
(p ∘ q) x y = ∫z (p x z) ⊗ (q z y)
There is also a tensor structure in the distributor category D(X, Y) defined by Day convolution, which I’ll describe next.
Summary
We have the following layers of abstraction:
- V is a monoidal category
- A (and B) are tensor categories enriched over V
- X, Y, and Z are categories enriched over V
- A distributor is a functor from Xop × Y to V
- Distributors may also be treated as “arrows” between categories and composed using coends.
Day Convolution
By analogy with distributions, distributors also have the equivalent of convolution defined on them. The integral is replaced by coend. The Day convolution of two functors F and G, both from the V-enriched monoidal category A to V, is defined as a (double) coend:
(F ⊗ G) x = ∫a,b A(a ⊗ b, x) ⊗ (F a) ⊗ (G b)
Notice the (here, explicit) use of a tensor product for objects of V (as well as for objects of A and for functors — hopefully this won’t lead to too much confusion). For V equal to Set, this is usually replaced by a cartesian product, but in Haskell this could be a product or a sum. In the formula, we also use the covariant hom-functor that maps an arbitrary object x in A to the hom-set A(a ⊗ b, x). This use of a coend justifies the use of the integral symbol: we are “integrating” over objects a and b in A.
If you squint hard enough you might find similarity between the Day convolution formula and the convolution on a group. Here we don’t have a group, so we have no analog of y-1x. Instead we define an appropriate “measure” using A(a ⊗ b, _). The convolution formula may be “partially integrated” to give the following equivalent definitions:
(F ⊗ G) x = ∫b (F bx) ⊗ (G b) (F ⊗ G) x = ∫a (F a) ⊗ (G xa)
Here you can see the resemblance to group convolution even better — if you remember that exponentiation can be thought of as the “inverse” of the tensor product. The left and right exponentiations are analogous to the left and right inverses.
The partial integration trick is the consequence of the so-called ninja Yoneda lemma, which can be written as:
F x = ∫a A(a, x) ⊗ (F a)
Notice that the hom-functor A(a, x) plays the role of the Dirac delta function.
There is also a unit J of Day convolution:
J x = A(i, x)
where i is the monoidal identity object.
Taken together this shows that Day convolution is a tensor product in the category of enriched functors (hence the use of the tensor symbol ⊗).
It’s interesting to see Day convolution expressed in Haskell. The category of Haskell types (which is approximately Set, modulo termination) can be treated as enriched over itself. The tensor product is just the cartesian product, represented either as a pair or a record with multiple fields. In this setting, a categorical coend becomes an existential quantifier, which is equivalent to a universal quantifier in front of the type constructor.
This is the definition of Day convolution from the Edward Kmett’s Data.Functor.Day
data Day f g a = forall b c. Day (f b) (g c) (b -> c -> a)
Here, f and g are the two functors, and forall plays the role of the existential quantifier (being put in front of the data constructor Day). The original hom-set Set(b⊗c, a), has the tensor product replaced by a pair constructor, and is curried to b->c->a. The data constructor has three fields, corresponding to the tensor (cartesian) product of three terms in the original definition.
Summary
We have the following layers of abstraction:
- V is a monoidal category
- A is a tensor category enriched over V
- Functors from A to V support a tensor product defined by Day convolution.
Tambara Modules
Modules were defined earlier through the action (left, right, or both) of a tensor category A on some other category X. Tambara modules specialize the category X to the category of distributors D(X, Y). We assume that the categories X and Y are themselves modules over A (that is, they have the action of A defined on them).
We define the left action of A on a distributor (profunctor) L(x, y) as:
a! :: L(x, y) -> L(ax, ay)
Similarly, the right action is given by:
!b :: L(x, y) -> L(xb, yb)
We also assume that the action of the unit object i from A is the identity.
These modules are called, respectively, the left and right Tambara modules. The Tambara (bi-)module supports both left and right actions and is denoted by:
AD(X, Y)B
In principle, A may be different from B.
If we choose the tensor product to be the categorical product and replace all categories with one, Tambara modules AD(A, A)A become Haskell’s strong profunctors:
class Profunctor p => Strong p where first' :: p a b -> p (a, c) (b, c) second' :: p a b -> p (c, a) (c, b)
On the other hand, with the choice of the categorical coproduct as the tensor product, we get choice profunctors:
class Profunctor p => Choice p where left' :: p a b -> p (Either a c) (Either b c) right' :: p a b -> p (Either c a) (Either c b)
We can even parameterize these classes by the type of the tensor product:
class (Profunctor p) => TamModule (ten :: * -> * -> *) p where leftAction :: p a b -> p (c `ten` a) (c `ten` b) rightAction :: p a b -> p (a `ten` c) (b `ten` c)
and specialize it to:
type TamStrong p = TamModule (,) p type TamChoice p = TamModule Either p
We can also define a Tambara module as a profunctor with two polymorphic functions:
data TambaraMod (ten :: * -> * -> *) p a b = TambaraMod
{ runTambaraMod :: (forall c. p (a `ten` c) (b `ten` c),
forall d. p (d `ten` a) (d `ten` b))
}
The Data.Profunctor.Tambara module specializes this definition for product and coproduct tensors. Since both these tensors are symmetric (weakly — up to an isomorphism), they can be constructed with just one polymorphic function each:
newtype Tambara p a b = Tambara {
runTambara :: forall c. p (a, c) (b, c) }
newtype TambaraSum p a b = TambaraSum {
runTambaraSum :: forall c. p (Either a c) (Either b c) }
Summary
We have the following layers of abstraction:
- V is a monoidal category
- A (and B) are tensor categories enriched over V
- X and Y are categories enriched over V
- X is a module if the action of A is defined over X (left, right, or both)
- Linear functors between X and Y preserve left, right, or bi actions of A (or B)
- A distributor is a functor from Xop × Y to V
- Distributors can be composed using coends
- Functors from A to V support a tensor product defined by Day convolution
- Distributors D(X, Y) form a category enriched over V
- Tambara modules are distributors with the action of A (left, right, or bi) defined on them.
Currying Tambara Modules
Let’s look again at the definition of a distributor:
Xop × Y -> V
It’s a functor of two arguments. We know that functions of two arguments can be curried — turned to functions of one argument that return functions. It turns out that a similar thing can be done with distributors. There is an isomorphism between the category of distributors and a category of functors returning functors, which looks very much like currying:
D(X, Y) ≅ Hom(Y, Hom(Xop, V))
According to this isomorphism, a distributor L is mapped to a functor G that takes an object of Y and maps it to another functor that takes an object of X and maps it to an object of V:
L x y = (G y) x
This correspondence may be extended to Tambara modules. Suppose that we have the left action of A defined on X and Y. Then there is an isomorphism of categories:
AD(X, Y) ≅ HomA(Y, Hom(Xop, V))
Remember that the category of left Tambara modules has the left action of A defined by A!. Acting on a distributor L it’s a map:
A! :: L x y -> L (ax) (ay)
On the right hand side of the isomorphism is a category of left-linear functors. An object in this category, K, is left linear:
K (ay) ≅ a(K y)
The target category for this functor is Hom(Xop, V), so K acting on y is another functor that, when acting on an object x of X produces a value in V.
L(x, y) ≅ (K y) x
We have to define the action of A! on the right hand side of this isomorphism. First, we use duality (assuming the category is rigid) — the mapping:
η :: i -> ac a
We get:
(K y) (acax)
Now we would like to use left-linearity of Hom(Xop, V) to move the action of ac out of the functor. Left linear structure on this category is defined by the equation:
(aF) x = F (acx)
where F is a functor from Xop to V.
We get:
(K y) (acax) = ((aK) y) (ax)
Finally, using left-linearity of K, we can turn this to:
(K (ay)) (ax)
which is what L (ax) (ay) is mapped to.
A similar argument may be used to show the general equivalence of Tambara bimodules with bilinear functors:
AD(X, Y)B ≅ HomA, B(Y, Hom(Xop, V))
Tambara Modules and Centralizers
The “currying” equivalence may be specialized to the case where all four tensor categories are the same:
AD(A, A)A ≅ HomA, A(A, Hom(Aop, V))
Earlier we’ve seen the equivalence of a bilinear functor and a centralizer:
HomA,A(A, X) ≅ ZA(X)
The category X here is an arbitrary tensor category over A. In particular, we can chose X to be Hom(Aop, V). This is the main result in Tambara’s paper:
AD(A, A)A ≅ ZA(Hom(Aop, V))
Earlier we’ve seen that distributors and, in particular, Tambara modules are equipped with a tensor product using Day convolution. Tambara also shows that the centralizers are equipped with a tensor product. The equivalence between Tambara modules and centralizers preserves this tensor product.
Acknowledgments
I’m grateful to Russell O’Connor, Edward Kmett, Dan Doel, Gershom Bazerman, and others, for fruitful discussions and useful comments and to André van Meulebrouck for checking the grammar and spelling.
Next: Free Tambara modules.