Introduction
Neural networks are an example of composable systems, so it’s no surprise that they can be modeled in category theory, which is the ultimate science of composition. Moreover, the categorical ideas behind neural networks can be immediately implemented and tested in a programming language. In this post I will present the Haskell implementation of parametric lenses, generalize them to pre-lenses and introduce their profunctor representation. Using the profunctor representation I will build a working multi-layer perceptron.
In the second part of this post I will introduce the bicategory 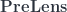 of pre-lenses and the bicategory of triple Tambara profunctors and show how they related to pre-lenses.
of pre-lenses and the bicategory of triple Tambara profunctors and show how they related to pre-lenses.
Complete Haskell implementation is available on gitHub, where you can also find the PDF version of this post, complete with the categorical picture.
Haskell Implementation
Every component of a neural network can be thought of as a system that transform input to output, and whose action depends on some parameters. In the language of neural networsks, this is called the forward pass. It takes a bunch of parameters p, combines it with the input s, and produces the output a. It can be described by a Haskell function:
fwd :: (p, s) -> a
But the real power of neural networks is in their ability to learn from mistakes. If we don’t like the output of the network, we can nudge it towards a better solution. If we want to nudge the output by some da, what change dp to the parameters should we make? The backward pass partitions the blame for the perceived error in direct proportion to the impact each parameter had on the result.
Because neural networks are composed of layers of neurons, each with their own sets or parameters, we might also ask the question: What change ds to this layer’s inputs (which are the outputs of the previous layer) should we make to improve the result? We could then back-propagate this information to the previous layer and let it adjust its own parameters. The backward pass can be described by another Haskell function:
bwd :: (p, s, da) -> (dp, ds)
The combination of these two functions forms a parametric lens:
data PLens a da p dp s ds =
PLens { fwd :: (p, s) -> a
, bwd :: (p, s, da) -> (dp, ds) }
In this representation it’s not immediately obvious how to compose parametric lenses, so I’m going to present a variety of other representations that may be more convenient in some applications.
Existential Parametric Lens
Notice that the backward pass re-uses the arguments (p, s) of the forward pass. Although some information from the forward pass is needed for the backward pass, it’s not always clear that all of it is required. It makes more sense for the forward pass to produce some kind of a care package to be delivered to the backward pass. In the simplest case, this package would just be the pair (p, s). But from the perspective of the user of the lens, the exact type of this package is an internal implementation detail, so we might as well hide it as an existential type m. We thus arrive at a more symmetric representation:
data ExLens a da p dp s ds =
forall m . ExLens ((p, s) -> (m, a))
((m, da) -> (dp, ds))
The type m is often called the residue of the lens.
These existential lenses can be composed in series. The result of the composition is parameterized by the product (a tuple) of the original parameters. We’ll see it more clearly in the next section.
But since the product of types is associative only up to isomorphism, the composition of parametric lenses is associative only up to isomorphism.
There is also an identity lens:
identityLens :: ExLens a da () () a da
identityLens = ExLens id id
but, again, the categorical identity laws are satisfied only up to isomorphism. This is why parametric lenses cannot be interpreted as hom-sets in a traditional category. Instead they are part of a bicategory that arises from the 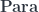 construction.
construction.
Pre-Lenses
Notice that there is still an asymmetry in the treatment of the parameters and the residues. The parameters are accumulated (tupled) during composition, while the residues are traced over (categorically, an existential type is described by a coend, which is a generalized trace). There is no reason why we shouldn’t accumulate the residues during composition and postpone the taking of the trace untill the very end.
We thus arrive at a fully symmetrical definition of a pre-lens:
data PreLens a da m dm p dp s ds =
PreLens ((p, s) -> (m, a))
((dm, da) -> (dp, ds))
We now have two separate types: m describing the residue, and dm describing the change of the residue.

If all we need at the end is to trace over the residues, we’ll identify the two types.
Notice that the role of parameters and residues is reversed between the forward and the backward pass. The forward pass, given the parameters and the input, produces the output plus the residue. The backward pass answers the question: How should we nudge the parameters and the inputs (dp, ds) if we want the residues and the outputs to change by (dm, da). In neural networks this will be calculated using gradient descent.
The composition of pre-lenses accumulates both the parameters and the residues into tuples:
preCompose ::
PreLens a' da' m dm p dp s ds ->
PreLens a da n dn q dq a' da' ->
PreLens a da (m, n) (dm, dn) (q, p) (dq, dp) s ds
preCompose (PreLens f1 g1) (PreLens f2 g2) = PreLens f3 g3
where
f3 = unAssoc . second f2 . assoc . first sym .
unAssoc . second f1 . assoc
g3 = unAssoc . second g1 . assoc . first sym .
unAssoc . second g2 . assoc
We use associators and symmetrizers to rearrange various tuples. Notice the separation of forward and backward passes. In particular, the backward pass of the composite lens depends only on backward passes of the composed lenses.
There is also an identity pre-lens:
idPreLens :: PreLens a da () () () () a da
idPreLens = PreLens id id
Pre-lenses thus form a bicategory that combines the and the 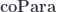 constructions in one.
constructions in one.
There is also a monoidal structure in this category induced by parallel composition. In parallel composition we tuple the respective inputs and outputs, as well as the parameters and residues, both in the forward and the backward passes.
The existential lens can be obtained from the pre-lens at any time by tracing over the residues:
data ExLens a da p dp s ds =
forall m. ExLens (PreLens a da m m p dp s ds)
Notice however that the tracing can be performed after we are done with all the (serial and parallel) compositions. In particular, we could dedicate one pipeline to perform forward passes, gathering both parameters and residues, and then send this data over to another pipeline that performs backward passes. The data is produced and consumed in the LIFO order.
Pre-Neuron
As an example, let’s implement the basic building block of neural networks, the neuron. In what follows, we’ll use the following type synonyms:
type D = Double
type V = [D]
A neuron can be decomposed into three mini-layers. The first layer is the linear transformation, which calculates the scalar product of the input vector and the vector of parameters:
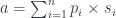
It also produces the residue which, in this case, consists of the tuple (V, V) of inputs and parameters:
fw :: (V, V) -> ((V, V), D)
fw (p, s) = ((s, p), sumN n $ zipWith (*) p s)
The backward pass has the general signature:
bw :: ((dm, da) -> (dp, ds))
Because we’re eventually going to trace over the residues, we’ll use the same type for dm as for m. And because we are going to do arithmetic over the parameters, we reuse the type of p for the delta dp. Thus the signature of the backward pass is:
bw :: ((V, V), D) -> (V, V)
In the backward pass we’ll encode the gradient descent. The steepest gradient direction and slope is given by the partial derivatives:
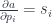

We multiply them by the desired change in the output da:
dp = fmap (da *) s
ds = fmap (da *) p
Here’s the resulting lens:
linearL :: Int -> PreLens D D (V, V) (V, V) V V V V
linearL n = PreLens fw bw
where
fw :: (V, V) -> ((V, V), D)
fw (p, s) = ((s, p), sumN n $ zipWith (*) p s)
bw :: ((V, V), D) -> (V, V)
bw ((s, p), da) = (fmap (da *) s
,fmap (da *) p)
The linear transformation is followed by a bias, which uses a single number as the parameter, and generates no residue:
biasL :: PreLens D D () () D D D D
biasL = PreLens fw bw
where
fw :: (D, D) -> ((), D)
fw (p, s) = ((), p + s)
-- da/dp = 1, da/ds = 1
bw :: ((), D) -> (D, D)
bw (_, da) = (da, da)
Finally, we implement the non-linear activation layer using the tanh function:
activL :: PreLens D D D D () () D D
activL = PreLens fw bw
where
fw (_, s) = (s, tanh s)
-- da/ds = 1 + (tanh s)^2
bw (s, da)= ((), da * (1 - (tanh s)^2))
A neuron with 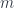 inputs is a composition of the three components, modulo some monoidal rearrangements:
inputs is a composition of the three components, modulo some monoidal rearrangements:
neuronL :: Int ->
PreLens D D ((V, V), D) ((V, V), D) Para Para V V
neuronL mIn = PreLens f' b'
where
PreLens f b =
preCompose (preCompose (linearL mIn) biasL) activL
f' :: (Para, V) -> (((V, V), D), D)
f' (Para bi wt, s) = let (((vv, ()), d), a) =
f (((), (bi, wt)), s)
in ((vv, d), a)
b' :: (((V, V), D), D) -> (Para, V)
b' ((vv, d), da) = let (((), (d', w')), ds) =
b (((vv, ()), d), da)
in (Para d' w', ds)
The parameters for the neuron can be conveniently packaged into one data structure:
data Para = Para { bias :: D
, weight :: V }
mkPara (b, v) = Para b v
unPara p = (bias p, weight p)
Using parallel composition, we can create whole layers of neurons, and then use sequential composition to model multi-layer neural networks. The loss function that compares the actual output with the expected output can also be implemented as a lens. We’ll perform this construction later using the profunctor representation.
Tambara Modules
As a rule, all optics that have an existential representation also have some kind of profunctor representation. The advantage of profunctor representations is that they are functions, and they compose using function composition.
Lenses, in particular, have a representation using a special category of profunctors called Tambara modules. A vanilla Tambara module is a profunctor p equipped with a family of transformations. It can be implemented as a Haskell class:
class Profunctor p => Tambara p where
alpha :: forall a da m. p a da -> p (m, a) (m, da)
The vanilla lens is then represented by the following profunctor-polymorphic function:
type Lens a da s ds = forall p. Tambara p => p a da -> p s ds
A similar representation can be constructed for pre-lenses. A pre-lens, however, has additional dependency on parameters and residues, so the analog of a Tambara module must also be parameterized by those. We need, therefore, a more complex type constructor t that takes six arguments:
t m dm p dp s ds
This is supposed to be a profunctor in three pairs of arguments, s ds, p dp, and dm m. Pro-functoriality in the first two pairs is implemented as two functions, diampS and dimapP. The inverted order in dm m means that t is covariant in m and contravariant in dm, as seen in the unusual type signature of dimapM:
dimapM :: (m -> m') -> (dm' -> dm) ->
t m dm p dp s ds -> t m' dm' p dp s ds
To generalize Tambara modules we first observe that the pre-lens now has two independent residues, m and dm, and the two should transform separately. Also, the composition of pre-lenses accumulates (through tupling) both the residues and the parameters, so it makes sense to use the additional type arguments to TriProFunctor as accumulators. Thus the generalized Tambara module has two methods, one for accumulating residues, and one for accumulating parameters:
class TriProFunctor t => Trimbara t where
alpha :: t m dm p dp s ds ->
t (m1, m) (dm1, dm) p dp (m1, s) (dm1, ds)
beta :: t m dm p dp (p1, s) (dp1, ds) ->
t m dm (p, p1) (dp, dp1) s ds
These generalized Tambara modules satisfy some coherency conditions.
One can also define natural transformations that are compatible with the new structures, so that Trimbara modules form a category.
The question arises: can this definition be satisfied by an actual non-trivial TriProFunctor? Fortunately, it turns out that a pre-lens itself is an example of a Trimbara module. Here’s the implementation of alpha for a PreLens:
alpha (PreLens fw bw) = PreLens fw' bw'
where
fw' (p, (n, s)) = let (m, a) = fw (p, s)
in ((n, m), a)
bw' ((dn, dm), da) = let (dp, ds) = bw (dm, da)
in (dp, (dn, ds))
and this is beta:
beta (PreLens fw bw) = PreLens fw' bw'
where
fw' ((p, r), s) = let (m, a) = fw (p, (r, s))
in (m, a)
bw' (dm, da) = let (dp, (dr, ds)) = bw (dm, da)
in ((dp, dr), ds)
This result will become important in the next section.
TriLens
Since Trimbara modules form a category, we can define a polymorphic function type (a categorical end) over Trimbara modules . This gives us the (tri-)profunctor representation for a pre-lens:
type TriLens a da m dm p dp s ds =
forall t. Trimbara t => forall p1 dp1 m1 dm1.
t m1 dm1 p1 dp1 a da ->
t (m, m1) (dm, dm1) (p1, p) (dp1, dp) s ds
Indeed, given a pre-lens we can construct the requisite mapping of Trimbara modules simply by lifting the two functions (the forward and the backward pass) and sandwiching them between the two Tambara structure maps:
toTamb :: PreLens a da m dm p dp s ds ->
TriLens a da m dm p dp s ds
toTamb (PreLens fw bw) = beta . dimapS fw bw . alpha
Conversely, given a mapping between Trimbara modules, we can construct a pre-lens by applying it to the identity pre-lens (modulo some rearrangement of tuples using the monoidal right/left unit laws):
fromTamb :: TriLens a da m dm p dp s ds ->
PreLens a da m dm p dp s ds
fromTamb f = dimapM runit unRunit $
dimapP unLunit lunit $
f idPreLens
The main advantage of the profunctor representation is that we can now compose two lenses using simple function composition; again, modulo some associators:
triCompose ::
TriLens b db m dm p dp s ds ->
TriLens a da n dn q dq b db ->
TriLens a da (m, n) (dm, dn) (q, p) (dq, dp) s ds
triCompose f g = dimapP unAssoc assoc .
dimapM unAssoc assoc .
f . g
Parallel composition of TriLenses is also relatively straightforward, although it involves a lot of bookkeeping (see the gitHub implementation).
Training a Neural Network
As a proof of concept, I have implemented and trained a simple 3-layer perceptron.
The starting point is the conversion of the individual components of the neuron from their pre-lens representation to the profunctor representation using toTamb. For instance:
linearT :: Int -> TriLens D D (V, V) (V, V) V V V V
linearT n = toTamb (linearL n)
We get a profunctor representation of a neuron by composing its three components:
neuronT :: Int ->
TriLens D D ((V, V), D) ((V, V), D) Para Para V V
neuronT mIn =
dimapP (second (unLunit . unPara))
(second (mkPara . lunit)) .
triCompose (dimapM (first runit) (first unRunit) .
triCompose (linearT mIn) biasT) activT
With parallel composition of tri-lenses, we can build a layer of neurons of arbitrary width.
layer :: Int -> Int ->
TriLens V V [((V, V), D)] [((V, V), D)] [Para] [Para] V V
layer mIn nOut =
dimapP (second unRunit) (second runit) .
dimapM (first lunit) (first unLunit) .
triCompose (branch nOut) (vecLens nOut (neuronT mIn))
The result is again a tri-lens, and such tri-lenses can be composed in series to create a multi-layer perceptron.
makeMlp :: Int -> [Int] ->
TriLens V V -- output
[[((V, V), D)]] [[((V, V), D)]] -- residues
[[Para]] [[Para]] -- parameters
V V -- input
Here, the first integer specifies the number of inputs of each neuron in the first layer. The list [Int] specifies the number of neurons in consecutive layers (which is also the number of inputs of each neuron in the following layer).
The training of a neural network is usually done by feeding it a batch of inputs together with a batch of expected outputs. This can be simply done by arranging multiple perceptrons in parallel and accumulating the parameters for the whole batch.
batchN :: (VSpace dp) => Int ->
TriLens a da m dm p dp s ds ->
TriLens [a] [da] [m] [dm] p dp [s] [ds]
To make the accumulation possible, the parameters must form a vector space, hence the constraint VSpace dp.
The whole thing is then capped by a square-distance loss lens that is parameterized by the ground truth values:
lossL :: PreLens D D ([V], [V]) ([V], [V]) [V] [V] [V] [V]
lossL = PreLens fw bw
where
fw (gTruth, s) =
((gTruth, s), sqDist (concat s) (concat gTruth))
bw ((gTruth, s), da) = (fmap (fmap negate) delta', delta')
where
delta' = fmap (fmap (da *)) (zipWith minus s gTruth)
In the next post I will present the categorical version of this construction.













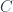
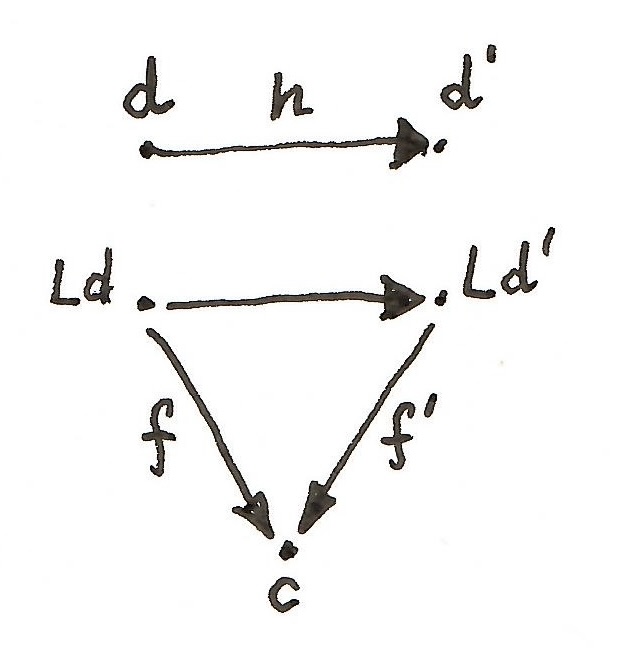























 equipped with two natural transformations:
equipped with two natural transformations:



 also a comonad? Can we implement the two natural transformations for it?
also a comonad? Can we implement the two natural transformations for it?



 , again a comonad? We can easily define a counit:
, again a comonad? We can easily define a counit:

 but it should be
but it should be  . To make it a comonad, we have to be able to push
. To make it a comonad, we have to be able to push  through
through  in the middle. We need
in the middle. We need 



 are in general not equal. All we can get from the original comonad laws is that they are only equal when applied to the result of comultiplication:
are in general not equal. All we can get from the original comonad laws is that they are only equal when applied to the result of comultiplication: .
. we can complete our definition of comultiplication for a composition of two comonads:
we can complete our definition of comultiplication for a composition of two comonads:
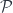 :
:
 is an object of
is an object of 
 .
.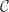 is a category in which we define an action of a monoidal category
is a category in which we define an action of a monoidal category 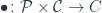
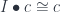
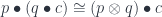
 to
to  as
as 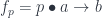 , and the second as
, and the second as  .
.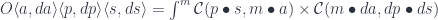
 , and the parameters
, and the parameters 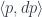 come from another monoidal category
come from another monoidal category 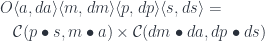
 in
in 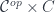 to the pair of objects
to the pair of objects 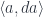 also in
also in  in
in 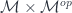 and a pair
and a pair  .
.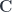 for the category
for the category 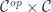 , and bold letters for pairs of objects and (twisted) pairs of morphisms. For instance,
, and bold letters for pairs of objects and (twisted) pairs of morphisms. For instance,  is a member of the hom-set
is a member of the hom-set 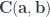 represented by a pair
represented by a pair 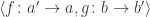 .
.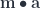 to denote the monoidal action of
to denote the monoidal action of  on
on 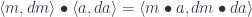
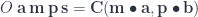

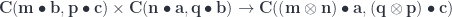
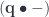 and the second by
and the second by  :
: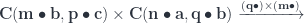
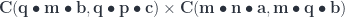

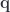 ,
, 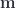 , and
, and  .
.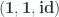
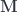 and
and 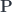 . Associativity and identity laws are satisfied modulo the associators and the unitors.
. Associativity and identity laws are satisfied modulo the associators and the unitors.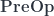 bicategory is also monoidal, with the obvious point-wise parallel composition of pre-optics.
bicategory is also monoidal, with the obvious point-wise parallel composition of pre-optics.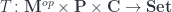
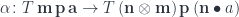
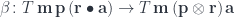
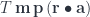 to
to 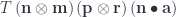 must give the same result.
must give the same result.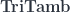 .
. , we get regular Tambara modules.
, we get regular Tambara modules. , we can define a mapping
, we can define a mapping 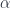 from the triple:
from the triple: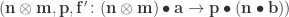
 by
by 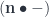 and rearranging the actions using their commutativity.
and rearranging the actions using their commutativity.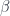 , we map:
, we map: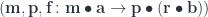
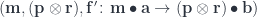
 can be expressed using triple Tambara modules. An optic:
can be expressed using triple Tambara modules. An optic: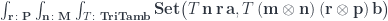
 and get an arbitrary pre-optic.
and get an arbitrary pre-optic.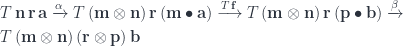
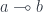 “consumes” its argument exactly once. This is not the whole truth, though, because we also have linear identity
“consumes” its argument exactly once. This is not the whole truth, though, because we also have linear identity  , which ostensibly does not consume
, which ostensibly does not consume ![\mathit{toList} \colon \text{Array} \; a \multimap \text{Ur} \, [a]](https://s0.wp.com/latex.php?latex=%5Cmathit%7BtoList%7D+%5Ccolon+%5Ctext%7BArray%7D+%5C%3B+a+%5Cmultimap+%5Ctext%7BUr%7D+%5C%2C+%5Ba%5D&bg=ffffff&fg=29303b&s=0&c=20201002)
![\mathit{fromList} \colon [a] \to (\text{Array} \; a \multimap \text{Ur} \; b) \multimap \text{Ur} \; b](https://s0.wp.com/latex.php?latex=%5Cmathit%7BfromList%7D+%5Ccolon+%5Ba%5D+%5Cto+%28%5Ctext%7BArray%7D+%5C%3B+a+%5Cmultimap+%5Ctext%7BUr%7D+%5C%3B+b%29+%5Cmultimap+%5Ctext%7BUr%7D+%5C%3B+b+&bg=ffffff&fg=29303b&s=0&c=20201002)
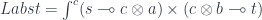
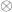 .
. 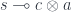 cannot be decomposed into a product of two morphisms
cannot be decomposed into a product of two morphisms 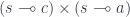 .
. 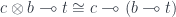
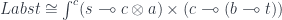
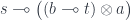
 , but it leaves you with the obligation to consume both the setter
, but it leaves you with the obligation to consume both the setter 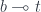 and the focus
and the focus  . It maps pairs of object to sets, and pairs of morphisms to functions. Since we are in a monoidal category, the morphisms are linear functions, but the mappings between sets are regular functions (see Appendix 1). Thus the action of the profunctor
. It maps pairs of object to sets, and pairs of morphisms to functions. Since we are in a monoidal category, the morphisms are linear functions, but the mappings between sets are regular functions (see Appendix 1). Thus the action of the profunctor 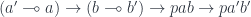
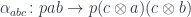
 is itself a Tambara module, for fixed
is itself a Tambara module, for fixed 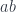 . To show this, let’s construct a mapping:
. To show this, let’s construct a mapping: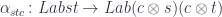
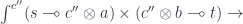
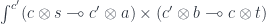
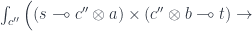
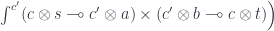
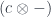 . We get:
. We get:
 .
.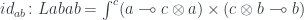
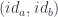 at
at 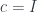 , the monoidal unit.
, the monoidal unit. 
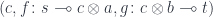 , we construct:
, we construct: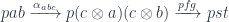
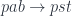 , we can apply it to the identity optic
, we can apply it to the identity optic 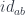 and obtain
and obtain 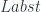 .
.
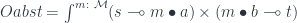
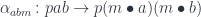
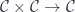 . In Haskell, we identify the tensor product
. In Haskell, we identify the tensor product 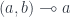 or
or 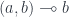 . Consequently, there is no diagonal map
. Consequently, there is no diagonal map 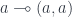 , and the unit object
, and the unit object 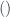 is not terminal: there is no arrow
is not terminal: there is no arrow  .
.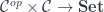 . Here,
. Here, 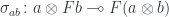
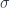 . Thus we have to construct:
. Thus we have to construct:
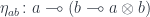
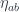 to
to  to arrive at
to arrive at 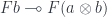 .
.![\int_{F \colon [\mathcal C, \mathcal C]} (a \multimap F b) \to (s \multimap F t)](https://s0.wp.com/latex.php?latex=%5Cint_%7BF+%5Ccolon+%5B%5Cmathcal+C%2C+%5Cmathcal+C%5D%7D+%28a+%5Cmultimap+F+b%29+%5Cto+%28s+%5Cmultimap+F+t%29+&bg=ffffff&fg=29303b&s=0&c=20201002)
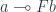 with a set of natural transformations, written as an end over
with a set of natural transformations, written as an end over  :
: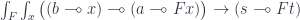
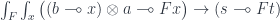
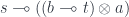
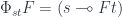 . It can be written as:
. It can be written as: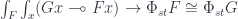

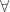 ) and existential quantifiers (there exists,
) and existential quantifiers (there exists, 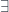 ).
).
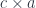
 is written as
is written as 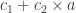 . The resulting optic has two possible residues,
. The resulting optic has two possible residues, 
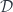 (I’ll use the same notation for both actions). The actions are composed using the tensor product in
(I’ll use the same notation for both actions). The actions are composed using the tensor product in 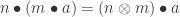
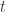 from the action of the same
from the action of the same 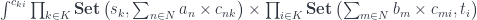
 and
and 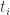 can be treated as fibers over the set
can be treated as fibers over the set 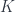 , while the sets
, while the sets 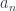 and
and 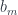 are fibers over a different set
are fibers over a different set 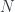 .
. of a discrete category
of a discrete category 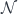 . The products over
. The products over  are fibrated over two different sets. I have previously interpreted them as
are fibrated over two different sets. I have previously interpreted them as 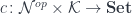
![[\mathcal C, Set ]](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal+C%2C+Set+%5D&bg=ffffff&fg=29303b&s=0&c=20201002) behaves, in many respects, like a vector space. For instance, it has a “basis” consisting of representable functors
behaves, in many respects, like a vector space. For instance, it has a “basis” consisting of representable functors 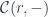 ; in the sense that any co-presheaf is as a colimit of representables. Moreover, colimit-preserving functors between co-presheaf categories are very similar to linear transformations between vector spaces. Of particular interest are functors that are left adjoint to some other functors, since left adjoints preserve colimits.
; in the sense that any co-presheaf is as a colimit of representables. Moreover, colimit-preserving functors between co-presheaf categories are very similar to linear transformations between vector spaces. Of particular interest are functors that are left adjoint to some other functors, since left adjoints preserve colimits.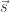 and
and 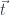 and another with
and another with 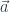 and
and 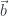 . Rectangular matrices
. Rectangular matrices 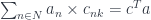
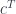 is the transposed matrix. Transposition here serves as an analog of adjunction.
is the transposed matrix. Transposition here serves as an analog of adjunction.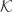 as discrete categories. We have:
as discrete categories. We have:![a, b \colon [\mathcal N, \mathbf{Set}]](https://s0.wp.com/latex.php?latex=a%2C+b+%5Ccolon+%5B%5Cmathcal+N%2C+%5Cmathbf%7BSet%7D%5D+&bg=ffffff&fg=29303b&s=0&c=20201002)
![s, t \colon [\mathcal K, \mathbf{Set}]](https://s0.wp.com/latex.php?latex=s%2C+t+%5Ccolon+%5B%5Cmathcal+K%2C+%5Cmathbf%7BSet%7D%5D+&bg=ffffff&fg=29303b&s=0&c=20201002)
![c \colon [\mathcal N, \mathbf{Set}] \to [\mathcal K, \mathbf{Set}]](https://s0.wp.com/latex.php?latex=c+%5Ccolon+%5B%5Cmathcal+N%2C+%5Cmathbf%7BSet%7D%5D+%5Cto+%5B%5Cmathcal+K%2C+%5Cmathbf%7BSet%7D%5D+&bg=ffffff&fg=29303b&s=0&c=20201002)
 .
.![[\mathcal K, \mathbf{Set}] (c \bullet a, t) \cong [\mathcal N, \mathbf{Set}] (a, c^{\dagger} \bullet t)](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal+K%2C+%5Cmathbf%7BSet%7D%5D+%28c+%5Cbullet+a%2C+t%29+%5Ccong+%5B%5Cmathcal+N%2C+%5Cmathbf%7BSet%7D%5D+%28a%2C+c%5E%7B%5Cdagger%7D+%5Cbullet+t%29+&bg=ffffff&fg=29303b&s=0&c=20201002)
![c^{\dagger} \colon [\mathcal K, \mathbf{Set}] \to [\mathcal N, \mathbf{Set}]](https://s0.wp.com/latex.php?latex=c%5E%7B%5Cdagger%7D+%5Ccolon+%5B%5Cmathcal+K%2C+%5Cmathbf%7BSet%7D%5D+%5Cto+%5B%5Cmathcal+N%2C+%5Cmathbf%7BSet%7D%5D+&bg=ffffff&fg=29303b&s=0&c=20201002)
![\mathcal{O}\langle a, b\rangle \langle s, t \rangle = \int^{c} [\mathcal K, \mathbf{Set}] \left(s, c \bullet a \right) \times [\mathcal K, \mathbf{Set}] \left(c \bullet b, t \right)](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BO%7D%5Clangle+a%2C+b%5Crangle+%5Clangle+s%2C+t+%5Crangle+%3D+%5Cint%5E%7Bc%7D+%5B%5Cmathcal+K%2C+%5Cmathbf%7BSet%7D%5D+%5Cleft%28s%2C++c+%5Cbullet+a+%5Cright%29+%5Ctimes+%5B%5Cmathcal+K%2C+%5Cmathbf%7BSet%7D%5D+%5Cleft%28c+%5Cbullet+b%2C+t+%5Cright%29+&bg=ffffff&fg=29303b&s=0&c=20201002)
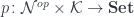
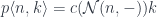
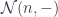 is a representable co-presheaf.
is a representable co-presheaf.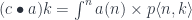
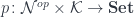 :
:![\int^{p} [\mathcal K, \mathbf{Set}] \left(s, \int^{n} a(n) \times p \langle n, - \rangle \right) \times [\mathcal K, \mathbf{Set}] \left(\int^{n'} b(n') \times p \langle n', - \rangle, t \right)](https://s0.wp.com/latex.php?latex=%5Cint%5E%7Bp%7D+%5B%5Cmathcal+K%2C+%5Cmathbf%7BSet%7D%5D+%5Cleft%28s%2C++%5Cint%5E%7Bn%7D+a%28n%29+%5Ctimes+p+%5Clangle+n%2C+-+%5Crangle+%5Cright%29+%5Ctimes+%5B%5Cmathcal+K%2C+%5Cmathbf%7BSet%7D%5D+%5Cleft%28%5Cint%5E%7Bn%27%7D+b%28n%27%29+%5Ctimes+p+%5Clangle+n%27%2C+-+%5Crangle%2C+t+%5Cright%29+&bg=ffffff&fg=29303b&s=0&c=20201002)
![c \colon [\mathcal N, \mathbf{Set}] \to [\mathcal K, \mathbf{Set}]](https://s0.wp.com/latex.php?latex=c+%5Ccolon++%5B%5Cmathcal+N%2C+%5Cmathbf%7BSet%7D%5D+%5Cto+%5B%5Cmathcal+K%2C+%5Cmathbf%7BSet%7D%5D+&bg=ffffff&fg=29303b&s=0&c=20201002)
![c' \colon [\mathcal K, \mathbf{Set}] \to [\mathcal M, \mathbf{Set}]](https://s0.wp.com/latex.php?latex=c%27+%5Ccolon++%5B%5Cmathcal+K%2C+%5Cmathbf%7BSet%7D%5D+%5Cto+%5B%5Cmathcal+M%2C+%5Cmathbf%7BSet%7D%5D+&bg=ffffff&fg=29303b&s=0&c=20201002)
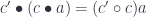
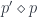 corresponding to
corresponding to 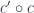 is given by:
is given by: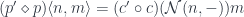
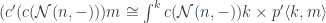
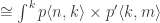
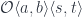 and
and 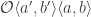 . The first one tells us that there exists a
. The first one tells us that there exists a ![l_c (s, a ) = [\mathcal K, \mathbf{Set}] \left(s, c \bullet a \right)](https://s0.wp.com/latex.php?latex=l_c+%28s%2C++a+%29+%3D+%5B%5Cmathcal+K%2C+%5Cmathbf%7BSet%7D%5D+%5Cleft%28s%2C++c+%5Cbullet+a+%5Cright%29+&bg=ffffff&fg=29303b&s=0&c=20201002)
![r_c (b, t) = [\mathcal K, \mathbf{Set}] \left(c \bullet b, t \right)](https://s0.wp.com/latex.php?latex=r_c+%28b%2C+t%29+%3D+%5B%5Cmathcal+K%2C+%5Cmathbf%7BSet%7D%5D+%5Cleft%28c+%5Cbullet+b%2C+t+%5Cright%29+&bg=ffffff&fg=29303b&s=0&c=20201002)
 and a pair:
and a pair:![l'_{c'} (a, a' ) = [\mathcal K, \mathbf{Set}] \left(a, c' \bullet a' \right)](https://s0.wp.com/latex.php?latex=l%27_%7Bc%27%7D+%28a%2C++a%27+%29+%3D+%5B%5Cmathcal+K%2C+%5Cmathbf%7BSet%7D%5D+%5Cleft%28a%2C++c%27+%5Cbullet+a%27+%5Cright%29+&bg=ffffff&fg=29303b&s=0&c=20201002)
![r'_{c'} (b', b) = [\mathcal K, \mathbf{Set}] \left(c' \bullet b', b \right)](https://s0.wp.com/latex.php?latex=r%27_%7Bc%27%7D+%28b%27%2C+b%29+%3D+%5B%5Cmathcal+K%2C+%5Cmathbf%7BSet%7D%5D+%5Cleft%28c%27+%5Cbullet+b%27%2C+b+%5Cright%29+&bg=ffffff&fg=29303b&s=0&c=20201002)
 . Indeed, we can construct such an optic using the composition
. Indeed, we can construct such an optic using the composition 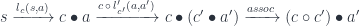
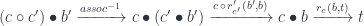
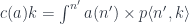
![a \colon [\mathcal N, \mathbf{Set}]](https://s0.wp.com/latex.php?latex=a+%5Ccolon+%5B%5Cmathcal+N%2C+%5Cmathbf%7BSet%7D%5D+&bg=ffffff&fg=29303b&s=0&c=20201002)
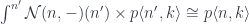
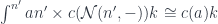
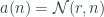

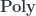 that consists of polynomial functors in which the fibration is done over one fixed set
that consists of polynomial functors in which the fibration is done over one fixed set 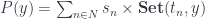
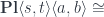
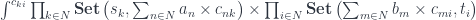
 . In this setting, we’ll write the residues
. In this setting, we’ll write the residues 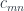 as profunctors:
as profunctors:
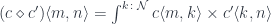
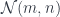 . (Incidentally, a monoid in this category is called a promonad.)
. (Incidentally, a monoid in this category is called a promonad.)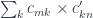
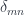 .
.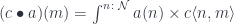
![[\mathcal{N}, \mathbf{Set}]](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BN%7D%2C+%5Cmathbf%7BSet%7D%5D+&bg=ffffff&fg=29303b&s=0&c=20201002) .
.![\mathbf{Pl}\langle s, t\rangle \langle a, b\rangle \cong \int^{c \colon [\mathcal{N}^{op} \times \mathcal{N}, Set]} [\mathcal{N}, \mathbf{Set}] \left(s, c \bullet a\right) \times [\mathcal{N}, \mathbf{Set}] \left(c \bullet b, t\right)](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BPl%7D%5Clangle+s%2C+t%5Crangle+%5Clangle+a%2C+b%5Crangle+%5Ccong+%5Cint%5E%7Bc+%5Ccolon+%5B%5Cmathcal%7BN%7D%5E%7Bop%7D+%5Ctimes+%5Cmathcal%7BN%7D%2C+Set%5D%7D+++%5B%5Cmathcal%7BN%7D%2C+%5Cmathbf%7BSet%7D%5D++%5Cleft%28s%2C+c+%5Cbullet+a%5Cright%29++%5Ctimes++%5B%5Cmathcal%7BN%7D%2C+%5Cmathbf%7BSet%7D%5D++%5Cleft%28c+%5Cbullet+b%2C+t%5Cright%29+&bg=ffffff&fg=29303b&s=0&c=20201002)

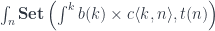
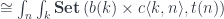
![\cong \int_{n, k} \mathbf{Set}\left(c\langle k, n \rangle , [b(k), t (n)]\right)](https://s0.wp.com/latex.php?latex=%5Ccong+++%5Cint_%7Bn%2C+k%7D+%5Cmathbf%7BSet%7D%5Cleft%28c%5Clangle+k%2C+n+%5Crangle+%2C+%5Bb%28k%29%2C+t+%28n%29%5D%5Cright%29+&bg=ffffff&fg=29303b&s=0&c=20201002)
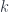 , is:
, is:![\mathbf{Pl}\langle s, t\rangle \langle a, b\rangle \cong \int_m \mathbf{Set}\left(s(m), \int^j a(j) \times [b(j), t(m)] \right)](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BPl%7D%5Clangle+s%2C+t%5Crangle+%5Clangle+a%2C+b%5Crangle+%5Ccong+%5Cint_m+%5Cmathbf%7BSet%7D%5Cleft%28s%28m%29%2C+%5Cint%5Ej+a%28j%29+%5Ctimes+%5Bb%28j%29%2C+t%28m%29%5D+%5Cright%29&bg=ffffff&fg=29303b&s=0&c=20201002)
![[\mathcal{N}, \mathbf{Set}] ( s, [b, t] \bullet a)](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BN%7D%2C+%5Cmathbf%7BSet%7D%5D+%28+s%2C+%5Bb%2C+t%5D+%5Cbullet+a%29&bg=ffffff&fg=29303b&s=0&c=20201002)
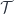 of profunctors of the type:
of profunctors of the type:![P \colon [\mathcal{N}, \mathbf{Set}]^{op} \times [\mathcal{N}, \mathbf{Set}] \to \mathbf{Set}](https://s0.wp.com/latex.php?latex=P+%5Ccolon+%5B%5Cmathcal%7BN%7D%2C+%5Cmathbf%7BSet%7D%5D%5E%7Bop%7D++%5Ctimes+%5B%5Cmathcal%7BN%7D%2C+%5Cmathbf%7BSet%7D%5D+%5Cto+%5Cmathbf%7BSet%7D+&bg=ffffff&fg=29303b&s=0&c=20201002)

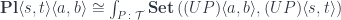
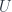 is the obvious forgetful functor from
is the obvious forgetful functor from ![\mathbf{PolyLens}\langle s, t\rangle \langle a, b\rangle = \prod_{k} \mathbf{Set}\left(s_k, \sum_{n} a_n \times [b_n, t_k] \right)](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BPolyLens%7D%5Clangle+s%2C+t%5Crangle+%5Clangle+a%2C+b%5Crangle+%3D+%5Cprod_%7Bk%7D+%5Cmathbf%7BSet%7D%5Cleft%28s_k%2C+%5Csum_%7Bn%7D+a_n+%5Ctimes+%5Bb_n%2C+t_k%5D+%5Cright%29+&bg=ffffff&fg=29303b&s=0&c=20201002)
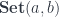 stands for a set of functions from
stands for a set of functions from ![[a, b]](https://s0.wp.com/latex.php?latex=%5Ba%2C+b%5D&bg=ffffff&fg=29303b&s=0&c=20201002) (the internal hom is the same as the external hom in
(the internal hom is the same as the external hom in 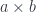 is the type of pairs
is the type of pairs ![\sum_{n} a_n \times [b_n, t_k]](https://s0.wp.com/latex.php?latex=%5Csum_%7Bn%7D+a_n+%5Ctimes+%5Bb_n%2C+t_k%5D+&bg=ffffff&fg=29303b&s=0&c=20201002)
