There is an engineer and a mathematician in each of us. My blog posts, for instance, alternate between discussing write ordering in the x86 processor, and explaining abstract ideas from category theory. I might be a bit extreme in this respect, but even in everyday programming we often switch between the focused, low-level, practical thinking of an engineer and the holistic, global, abstract thinking of a mathematician. Sometimes we write a for loop; sometimes we holistically apply std::transform to a vector. Sometimes we write imperative step-by-step programs; and sometimes we write declarative ones, letting the compiler figure out the steps.
What I find fascinating is that these two approaches also manifest themselves in mathematics. There are constructive proofs that resemble the work of an engineer; and there are proofs of existence, that resemble the work of a philosopher. An entity may be defined by showing how to construct it, or it might be defined by its universal property — by being the most general or the most specific among its peers. A universal description is favored by category theorists, especially if it reduces their dependency on Set Theory. It’s not that category theorists hate set theory, but they definitely like to limit their reliance on it.
In this post I’ll show you the two ways of defining a free monoid. If the term monoid is not familiar to you, don’t despair; it’s a very simple construct, and you’ve seen it and used it many times. The classic example of a monoid is the set of strings with string concatenation. Another is the set of natural numbers with addition (or multiplication — either will work).
Free Monoid
A monoid is a set with a binary operation — let’s just call it multiplication and denote it by the infix * (you’ll also see it called, in Haskell, mappend, ++, <>…). This binary operation must obey certain laws. The first law is that there is a special element called unit, e, with the property that for any a:
a * e = e * a = a
(You’ll also see it called mempty.) The second law is that of associativity:
a * (b * c) = (a * b) * c
There are many examples of monoids, but there is a special class of them called free monoids. The easiest way to understand what a free monoid is, is to construct one. Just pick a set, any set, and call it the set of generators. Then define multiplication in the laziest, dumbest possible way. First, add one more element to the set and call it a unit. Define multiplication by unit to always return the other multiplicand. Then, for every pair of generators create a new element and call it their product. Define products of products the same way — every time you need to multiply two existing elements, create a new one, call it their product, and add it to the growing set. The only tricky part is to make sure that thusly defined product is associative. So for every triple of elements, a, b, and c, you have to identify a * (b * c) with (a * b) * c.
Here’s a little mnemonic trick that may help you keeping track of associativity. Assign letters of the alphabet to your generators. Say, you have less than 26 generators and you call them a, b, c, etc. Reserve letter z for your unit element. When asked for the product of, say, a and t, call it at. The product of c and at will be cat, and so on. This way, you’ll automatically call the product of ca with t, cat, as you should.
As you can see a free monoid generated by an alphabet is equivalent to the set of strings, with product defined as string concatenation.
What happens when your original set has just one element, say a? The free monoid based on this set would contain the unit z and all the powers of a of the form aaa.... Writing long strings of as is boring, so instead let’s just length-encode them: a as 1, aa as 2, and so on. It’s natural to assign zero to z. We have just reinvented natural numbers with “product” being the addition.
Lists are free monoids too. Take any finite or infinite set and create ordered lists of its elements. Your unit element is the empty list, and “multiplication” is the concatenation of lists. Strings are just a special type of lists based on a finite set of generators. But you can have lists of integers, 3-D points, or even lists of lists.
Not all monoids are free, though. Take for instance addition modulo 4. You start with four elements: 0, 1, 2, and 3. But the sum of 2 and 3 is 1 (5 mod 4). Were it a free monoid, 2+3 would be a totally new element, but here we identified it with the existing element 1.
The question is, can we obtain any monoid by identifying some elements of the corresponding free monoid? The modulo 4 monoid, for instance, could be obtained by identifying all natural numbers that have the same remainder when divided by 4.
The answer is yes, and it’s an example of a very important notion in category theory called universality. A free monoid is universal. Here’s what it means: I have a set of generators and a free monoid built from it. Give me any monoid and select any elements in it to correspond to the generators of my free monoid. I can show you a unique mapping m of my free monoid to your monoid that not only maps my generators to your selected elements, but also preserves multiplication. In other words, if a * b = c in my monoid, then m(a) * m(b) = m(c) in your monoid.
Notice that the mapping might not cover the whole target monoid. It might cover a sub-monoid. But within that sub-monoid, for each element in my monoid there will be a corresponding element in yours. In general, multiple elements in my monoid may be mapped to a single element in yours. This way your monoid has the same structure as mine, except that some elements have been identified.
Any monoid can be obtained from a free monoid by identifying some elements.
Categorical Monoid
You might find the above theorem in a category theory text (see, for instance, Saunders Mac Lane, Categories for the Working Mathematician, Corollary 2 on p. 50) and not recognize it. That’s because category theoreticians don’t like treating monoids as sets of elements. They prefer to see a monoid as a shapeless object whose properties are encoded in morphisms — arrows from a monoid to itself.
How do we reconcile these two views of monoids? On the one hand you have a set of elements with multiplication, on the other hand a monolithic blob with arrows.
Here’s one way: Consider what happens when you pick one element of a monoid and apply it to all elements — say, by left multiplication. You get a function acting on this set (in Haskell we call this function an operator section). That’s your morphism. Notice that you can compose such morphisms just like you compose functions: left multiplication by “a” composed with left multiplication by “b” is the same function as left multiplication by “a * b”. The set of these morphisms/functions — one for each element — together with the usual function composition — tells you everything about the monoid. It gives you the categorical description of it: A monoid is a category with a single object (“mono” means one, single) and a bunch of morphisms acting on it.
There is also a bigger Category of Monoids, where monoids are the objects and morphisms map monoids into monoids preserving their structure (they map products into products). Some of these monoids are free, others are not.
We know how to construct a free monoid starting from a set of generators, but how can we tell which of the abstract blobs with morphisms is free and which isn’t? And how do we even begin talking about generators if we vowed not to view monoids as sets?
Universal Construction
We have to work our way back from abstract monoids to sets. But to do that we need a functor because we’re going between categories. Our source is the category of monoids, and our target is the category of sets, where objects are sets and morphisms are regular functions.
Just a reminder: A functor is a mapping between categories. It maps objects into objects and morphisms into morphisms; but not willy-nilly — it has to preserve composition. So if one morphism is a composition of two others, it’s image under the functor must also be the composition of the two images.
In our case we will be mapping the category of monoids into the category of sets. But once you mapped a monoid into a set (its, so called, underlying set), you have forgotten its structure. You have forgotten that some functions were “special” because they corresponded to the morphisms of the original monoid. All functions are now equal. This kind of functor that forgets structure is aptly called a forgetful functor.
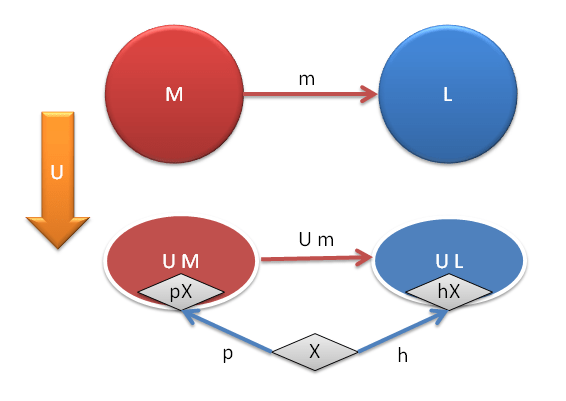
Our goal is to describe a free monoid corresponding to a set of generators X. X is just a regular set, nothing fancy, but we can’t look for it inside a monoid because a monoid is not a set any more. Fortunately we have our forgetful functor U, which maps monoids into sets. So instead of looking for generators inside monoids (which we can’t do), we’ll look for them inside those underlying sets. Given a monoid M, we just pick a function p: X -> U M. The image of X under p will serve as candidate generators.
Now let’s take another monoid L and do the same thing. We map our generators into the set U L (the set obtained from L using the same forgetful functor U). Call this mapping h: X -> U L. Now, U is a functor, so it maps monoids to sets and monoid morphisms to functions. So if there is a morphism m from M to L, there is a corresponding function from U M to U L (we’ll call this function U m). This is just a function mapping the set that’s underlying one monoid into the set that’s underlying another monoid.
The first set, U M, contains the images of our generators under p. Our function U m will map those candidate generators into some set in U L. Now, U L also contains candidate generators — the images of X under h. What are the chances that those two sets are the same? Slim but not zero! If we can pick m so that they overlap, we will have come as close as possible to the idea of the two monoids “sharing the same generators.” (See the following illustration.)

Universal construction of a free monoid generated by X
So given two monoids M and L and a set of generators X we can create candidate sets of generators in U M and U L. If we’re lucky, we can find a monoid morphism m that maps M to L and whose projection using U maps one candidate set of generators into the other.
Now zoom out to the category of monoids and draw an arrow between any M and L whenever such m exists. What you’ll find out, to your great amazement, is that there is one unique monoid (up to an isomorphism) that has all arrows going out and none coming in. This universal monoid is the free monoid constructed from the set of generators X. The two completely different descriptions converge!
Conclusion
How does it work? What’s the intuition behind it?
A lot of mathematicians secretly (or not so secretly) subscribe to Plato’s philosophy. A monoid is a Platonic object that can’t be observed directly, but which can cast a shadow on the wall of the cave we live in. This shadow is the underlying set: the result of a forgetful functor. The morphisms between monoids preserve their nature; theirs shadows, though, are mere functions.
Functions may be invertible, but often they conflate elements together. So if you have a flow of functions from one set to a bunch of others, they will tend to smooth out the differences, collapse multiple elements into one. So if there is one shadow of a monoid that dominates all others that are sharing the same generators — and there always is one — it must be the shadow of the free one. It is the one that has the largest selection of distinct elements, since every multiplication produces a new element (mitigated only by the requirements of associativity and the need for the unit).
Appendix: A Bonus Free Object
Free monoid is an example of a larger class of free objects. Free object is a powerful notion in category theory that generalizes the idea of a basis. Instead of the category of monoids let’s take any category that supports a faithful functor into the category of sets. A faithful functor is a functor that maps distinct morphism into distinct functions — it doesn’t mash them together. This will be our forgetful functor U. It maps an object A from our category to a set U A; and we can inject our basis X into this set, just like we did with generators. Object A is called universal if, for any other object B and any injection of X into U B, there is a unique morphism from A to B that “preserves” the basis. Again, by preserving the basis we mean that the image of our morphism under U maps one injected basis into the other.
In my previous blog posts I described C++ implementations of two basic functional data structures: a persistent list and a persistent red-black tree. I made an argument that persistent data structures are good for concurrency because of their immutability. In this post I will explain in much more detail the role of immutability in concurrent programming and argue that functional data structures make immutability scalable and composable.
Concurrency in 5 Minutes
To understand the role of functional data structures in concurrent programming we first have to understand concurrent programming. Okay, so maybe one blog post is not enough, but I’ll try my best at mercilessly slashing through the complexities and intricacies of concurrency while brutally ignoring all the details and subtleties.
The archetype for all concurrency is message passing. Without some form of message passing you have no communication between processes, threads, tasks, or whatever your units of execution are. The two parts of “message passing” loosely correspond to data (message) and action (passing). So there is the fiddling with data by one thread, some kind of handover between threads, and then the fiddling with data by another thread. The handover process requires synchronization.
There are two fundamental problems with this picture: Fiddling without proper synchronization leads to data races, and too much synchronization leads to deadlocks.
Communicating Processes
Let’s start with a simpler world and assume that our concurrent participants share no memory — in that case they are called processes. And indeed it might be physically impossible to share memory between isolated units because of distances or hardware protection. In that case messages are just pieces of data that are magically transported between processes. You just put them (serialize, marshall) in a special buffer and tell the system to transmit them to someone else, who then picks them up from the system.
So the problem reduces to the proper synchronization protocols. The theory behind such systems is the good old CSP (Communicating Sequential Processes) from the 1970s. It has subsequently been extended to the Actor Model and has been very successful in Erlang. There are no data races in Erlang because of the isolation of processes, and no traditional deadlocks because there are no locks (although you can have distributed deadlocks when processes are blocked on receiving messages from each other).
The fact that Erlang’s concurrency is process-based doesn’t mean that it’s heavy-weight. The Erlang runtime is quite able to spawn thousands of light-weight user-level processes that, at the implementation level, may share the same address space. Isolation is enforced by the language rather than by the operating system. Banning direct sharing of memory is the key to Erlang’s success as the language for concurrent programming.
So why don’t we stop right there? Because shared memory is so much faster. It’s not a big deal if your messages are integers, but imagine passing a video buffer from one process to another. If you share the same address space (that is, you are passing data between threads rather than processes) why not just pass a pointer to it?
Shared Memory
Shared memory is like a canvas where threads collaborate in painting images, except that they stand on the opposite sides of the canvas and use guns rather than brushes. The only way they can avoid killing each other is if they shout “duck!” before opening fire. This is why I like to think of shared-memory concurrency as the extension of message passing. Even though the “message” is not physically moved, the right to access it must be passed between threads. The message itself can be of arbitrary complexity: it could be a single word of memory or a hash table with thousands of entries.
It’s very important to realize that this transfer of access rights is necessary at every level, starting with a simple write into a single memory location. The writing thread has to send a message “I have written” and the reading thread has to acknowledge it: “I have read.” In standard portable C++ this message exchange might look something like this:
std::atomic x = false;
// thread one
x.store(true, std::memory_order_release);
// thread two
x.load(std::memory_order_acquire);
You rarely have to deal with such low level code because it’s abstracted into higher order libraries. You would, for instance, use locks for transferring access. A thread that acquires a lock gains unique access to a data structure that’s protected by it. It can freely modify it knowing that nobody else can see it. It’s the release of the lock variable that makes all those modifications visible to other threads. This release (e.g., mutex::unlock) is then matched with the subsequent acquire (e.g., mutex::lock) by another thread. In reality, the locking protocol is more complicated, but it is at its core based on the same principle as message passing, with unlock corresponding to a message send (or, more general, a broadcast), and lock to a message receive.
The point is, there is no sharing of memory without communication.
Immutable Data
The first rule of synchronization is:
The only time you don’t need synchronization is when the shared data is immutable.
We would like to use as much immutability in implementing concurrency as possible. It’s not only because code that doesn’t require synchronization is faster, but it’s also easier to write, maintain, and reason about. The only problem is that:
No object is born immutable.
Immutable objects never change, but all data, immutable or not, must be initialized before being read. And initialization means mutation. Static global data is initialized before entering main, so we don’t have to worry about it, but everything else goes through a construction phase.
First, we have to answer the question: At what point after initialization is data considered immutable?
Here’s what needs to happen: A thread has to somehow construct the data that it destined to be immutable. Depending on the structure of that data, this could be a very simple or a very complex process. Then the state of that data has to be frozen — no more changes are allowed. But still, before the data can be read by another thread, a synchronization event has to take place. Otherwise the other thread might see partially constructed data. This problem has been extensively discussed in articles about the singleton pattern, so I won’t go into more detail here.
One such synchronization event is the creation of the receiving thread. All data that had been frozen before the new thread was created is seen as immutable by that thread. That’s why it’s okay to pass immutable data as an argument to a thread function.
Another such event is message passing. It is always safe to pass a pointer to immutable data to another thread. The handover always involves the release/acquire protocol (as illustrated in the example above).
All memory writes that happened in the first thread before it released the message become visible to the acquiring thread after it received it.
The act of message passing establishes the “happens-before” relationship for all memory writes prior to it, and all memory reads after it. Again, these low-level details are rarely visible to the programmer, since they are hidden in libraries (channels, mailboxes, message queues, etc.). I’m pointing them out only because there is no protection in the language against the user inadvertently taking affairs into their own hands and messing things up. So creating an immutable object and passing a pointer to it to another thread through whatever message passing mechanism is safe. I also like to think of thread creation as a message passing event — the payload being the arguments to the thread function.
The beauty of this protocol is that, once the handover is done, the second (and the third, and the fourth, and so on…) thread can read the whole immutable data structure over and over again without any need for synchronization. The same is not true for shared mutable data structures! For such structures every read has to be synchronized at a non-trivial performance cost.
However, it can’t be stressed enough that this is just a protocol and any deviation from it may be fatal. There is no language mechanism in C++ that may enforce this protocol.
Clusters
As I argued before, access rights to shared memory have to be tightly controlled. The problem is that shared memory is not partitioned nicely into separate areas, each with its own army, police, and border controls. Even though we understand that an object is frozen after construction and ready to be examined by other threads without synchronization, we have to ask ourselves the question: Where exactly does this object begin and end in memory? And how do we know that nobody else claims writing privileges to any of its parts? After all, in C++ it’s pointers all the way. This is one of the biggest problems faced by imperative programmers trying to harness concurrency — who’s pointing where?
For instance, what does it mean to get access to an immutable linked list? Obviously, it’s not enough that the head of the list never changes, every single element of the list must be immutable as well. In fact, any memory that can be transitively accessed from the head of the list must be immutable. Only then can you safely forgo synchronization when accessing the list, as you would in a single-threaded program. This transitive closure of memory accessible starting from a given pointer is often called a cluster. So when you’re constructing an immutable object, you have to be able to freeze the whole cluster before you can pass it to other threads.
But that’s not all! You must also guarantee that there are no mutable pointers outside of the cluster pointing to any part of it. Such pointers could be inadvertently used to modify the data other threads believe to be immutable.
That means the construction of an immutable object is a very delicate operation. You not only have to make sure you don’t leak any pointers, but you have to inspect every component you use in building your object for potential leaks — you either have to trust all your subcontractors or inspect their code under the microscope. This clearly is no way to build software! We need something that it scalable and composable. Enter…
Functional Data Structures
Functional data structures let you construct new immutable objects by composing existing immutable objects.
Remember, an immutable object is a complete cluster with no pointers sticking out of it, and no mutable pointers poking into it. A sum of such objects is still an immutable cluster. As long as the constructor of a functional data structure doesn’t violate the immutability of its arguments and does not leak mutable pointers to the memory it is allocating itself, the result will be another immutable object.
Of course, it would be nice if immutability were enforced by the type system, as it is in the D language. In C++ we have to replace the type system with discipline, but still, it helps to know exactly what the terms of the immutability contract are. For instance, make sure you pass only (const) references to other immutable objects to the constructor of an immutable object.
Let’s now review the example of the persistent binary tree from my previous post to see how it follows the principles I described above. In particular, let me show you that every Tree forms an immutable cluster, as long as user data is stored in it by value (or is likewise immutable).
The proof proceeds through structural induction, but it’s easy to understand. An empty tree forms an immutable cluster trivially. A non-empty tree is created by combining two other trees. We can assume by the inductive step that both of them form immutable clusters:
Tree(Tree const & lft, T val, Tree const & rgt)
In particular, there are no external mutating pointers to lft, rgt, or to any of their nodes.
Inside the constructor we allocate a fresh node and pass it the three arguments:
Tree(Tree const & lft, T val, Tree const & rgt)
: _root(std::make_shared<const Node>(lft._root, val, rgt._root))
{}
Here _root is a private member of the Tree:
std::shared_ptr<const Node> _root;
and Node is a private struct defined inside Tree:
struct Node
{
Node(std::shared_ptr<const Node> const & lft
, T val
, std::shared_ptr<const Node> const & rgt)
: _lft(lft), _val(val), _rgt(rgt)
{}
std::shared_ptr<const Node> _lft;
T _val;
std::shared_ptr<const Node> _rgt;
};
Notice that the only reference to the newly allocated Node is stored in _root through a const pointer and is never leaked. Moreover, there are no methods of the tree that either modify or expose any part of the tree to modification. Therefore the newly constructed Tree forms an immutable cluster. (With the usual caveat that you don’t try to bypass the C++ type system or use other dirty tricks).
As I discussed before, there is some bookkeeping related to reference counting in C++, which is however totally transparent to the user of functional data structures.
Conclusion
Immutable data structures play an important role in concurrency but there’s more to them that meets the eye. In this post I tried to demonstrate how to use them safely and productively. In particular, functional data structures provide a scalable and composable framework for working with immutable objects.
Of course not all problems of concurrency can be solved with immutability and not all immutable object can be easily created from other immutable objects. The classic example is a doubly-linked list: you can’t add a new element to it without modifying pointers in it. But there is a surprising variety of composable immutable data structures that can be used in C++ without breaking the rules. I will continue describing them in my future blog posts.