This is part 29 of Categories for Programmers. Previously: Enriched Categories. See the Table of Contents.
I realize that we might be getting away from programming and diving into hard-core math. But you never know what the next big revolution in programming might bring and what kind of math might be necessary to understand it. There are some very interesting ideas going around, like functional reactive programming with its continuous time, the extention of Haskell’s type system with dependent types, or the exploration on homotopy type theory in programming.
So far I’ve been casually identifying types with sets of values. This is not strictly correct, because such approach doesn’t take into account the fact that, in programming, we compute values, and the computation is a process that takes time and, in extreme cases, might not terminate. Divergent computations are part of every Turing-complete language.
There are also foundational reasons why set theory might not be the best fit as the basis for computer science or even math itself. A good analogy is that of set theory being the assembly language that is tied to a particular architecture. If you want to run your math on different architectures, you have to use more general tools.
One possibility is to use spaces in place of sets. Spaces come with more structure, and may be defined without recourse to sets. One thing usually associated with spaces is topology, which is necessary to define things like continuity. And the conventional approach to topology is, you guessed it, through set theory. In particular, the notion of a subset is central to topology. Not surprisingly, category theorists generalized this idea to categories other than Set. The type of category that has just the right properties to serve as a replacement for set theory is called a topos (plural: topoi), and it provides, among other things, a generalized notion of a subset.
Subobject Classifier
Let’s start by trying to express the idea of a subset using functions rather than elements. Any function f from some set a to b defines a subset of b–that of the image of a under f. But there are many functions that define the same subset. We need to be more specific. To begin with, we might focus on functions that are injective — ones that don’t smush multiple elements into one. Injective functions “inject” one set into another. For finite sets, you may visualize injective functions as parallel arrows connecting elements of one set to elements of another. Of course, the first set cannot be larger than the second set, or the arrows would necessarily converge. There is still some ambiguity left: there may be another set a' and another injective function f' from that set to b that picks the same subset. But you can easily convince yourself that such a set would have to be isomorphic to a. We can use this fact to define a subset as a family of injective functions that are related by isomorphisms of their domains. More precisely, we say that two injective functions:
f :: a -> b
f':: a'-> b
are equivalent if there is an isomorphism:
h :: a -> a'
such that:
f = f' . h
Such a family of equivalent injections defines a subset of b.

This definition can be lifted to an arbitrary category if we replace injective functions with monomorphism. Just to remind you, a monomorphism m from a to b is defined by its universal property. For any object c and any pair of morphisms:
g :: c -> a
g':: c -> a
such that:
m . g = m . g'
it must be that g = g'.

On sets, this definition is easier to understand if we consider what it would mean for a function m not to be a monomorphism. It would map two different elements of a to a single element of b. We could then find two functions g and g' that differ only at those two elements. The postcomposition with m would then mask this difference.

There is another way of defining a subset: using a single function called the characteristic function. It’s a function χ from the set b to a two-element set Ω. One element of this set is designated as “true” and the other as “false.” This function assigns “true” to those elements of b that are members of the subset, and “false” to those that aren’t.
It remains to specify what it means to designate an element of Ω as “true.” We can use the standard trick: use a function from a singleton set to Ω. We’ll call this function true:
true :: 1 -> Ω

These definitions can be combined in such a way that they not only define what a subobject is, but also define the special object Ω without talking about elements. The idea is that we want the morphism true to represent a “generic” subobject. In Set, it picks a single-element subset from a two-element set Ω. This is as generic as it gets. It’s clearly a proper subset, because Ω has one more element that’s not in that subset.
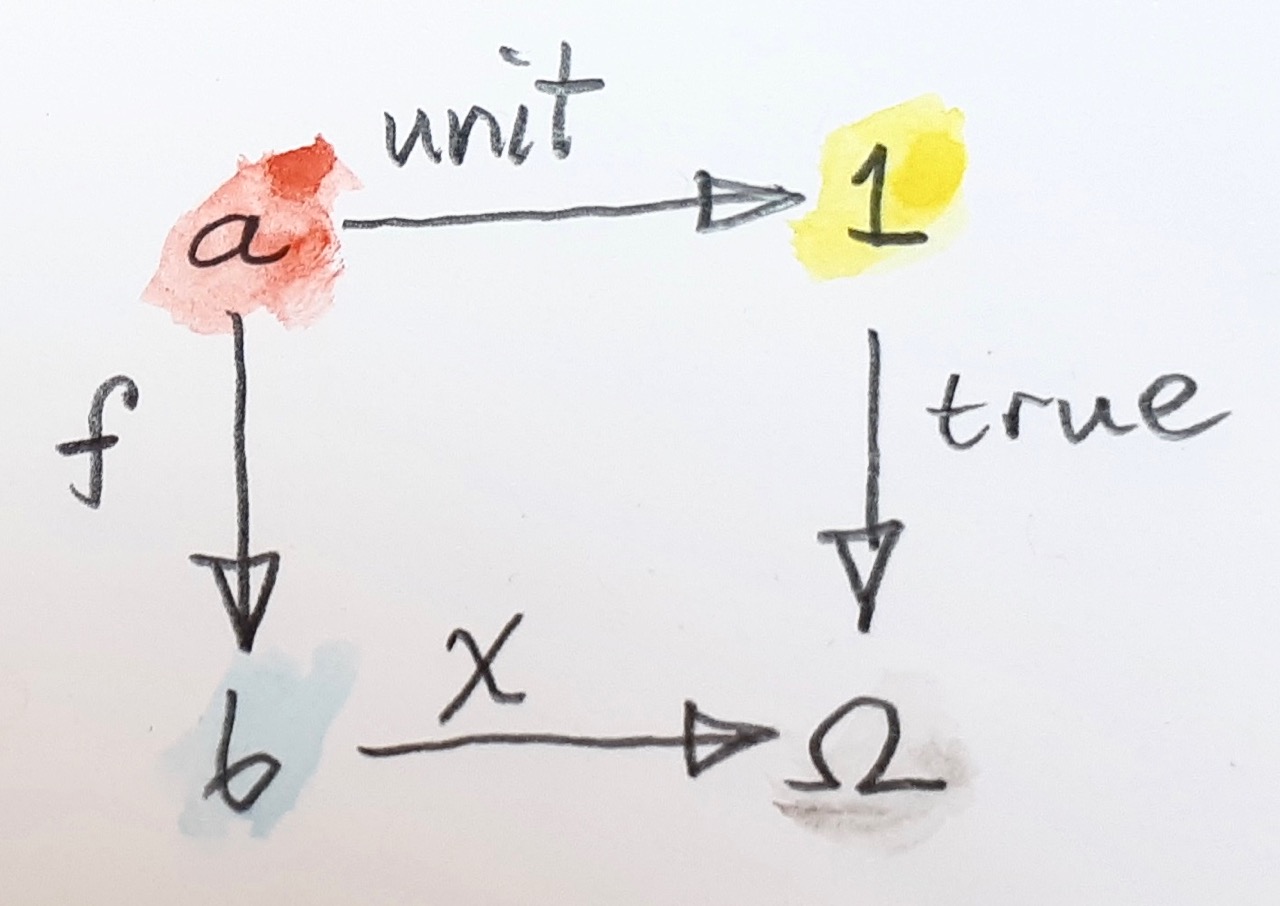
In a more general setting, we define true to be a monomorphism from the terminal object to the classifying object Ω. But we have to define the classifying object. We need a universal property that links this object to the characteristic function. It turns out that, in Set, the pullback of true along the characteristic function χ defines both the subset a and the injective function that embeds it in b. Here’s the pullback diagram:

Let’s analyze this diagram. The pullback equation is:
true . unit = χ . f
The function true . unit maps every element of a to “true.” Therefore f must map all elements of a to those elements of b for which χ is “true.” These are, by definition, the elements of the subset that is specified by the characteristic function χ. So the image of f is indeed the subset in question. The universality of the pullback guarantees that f is injective.
This pullback diagram can be used to define the classifying object in categories other than Set. Such a category must have a terminal object, which will let us define the monomorphism true. It must also have pullbacks — the actual requirement is that it must have all finite limits (a pullback is an example of a finite limit). Under those assumptions, we define the classifying object Ω by the property that, for every monomorphism f there is a unique morphism χ that completes the pullback diagram.
Let’s analyze the last statement. When we construct a pullback, we are given three objects Ω, b and 1; and two morphisms, true and χ. The existence of a pullback means that we can find the best such object a, equipped with two morphisms f and unit (the latter is uniquely determined by the definition of the terminal object), that make the diagram commute.
Here we are solving a different system of equations. We are solving for Ω and true while varying both a and b. For a given a and b there may or may not be a monomorphism f::a->b. But if there is one, we want it to be a pullback of some χ. Moreover, we want this χ to be uniquely determined by f.
We can’t say that there is a one-to-one correspondence between monomorphisms f and characteristic functions χ, because a pullback is only unique up to isomorphism. But remember our earlier definition of a subset as a family of equivalent injections. We can generalize it by defining a subobject of b as a family of equivalent monomorphisms to b. This family of monomorphisms is in one-to-one corrpespondence with the family of equivalent pullbacks of our diagram.
We can thus define a set of subobjects of b, Sub(b), as a family of monomorphisms, and see that it is isomorphic to the set of morphisms from b to Ω:
Sub(b) ≅ C(b, Ω)
This happens to be a natural isomorphism of two functors. In other words, Sub(-) is a representable (contravariant) functor whose representation is the object Ω.
Topos
A topos is a category that:
- Is cartesian closed: It has all products, the terminal object, and exponentials (defined as right adjoints to products),
- Has limits for all finite diagrams,
- Has a subobject classifier
Ω.
This set of properties makes a topos a shoe-in for Set in most applications. It also has additional properties that follow from its definition. For instance, a topos has all finite colimits, including the initial object.
It would be tempting to define the subobject classifier as a coproduct (sum) of two copies of the terminal object –that’s what it is in Set— but we want to be more general than that. Topoi in which this is true are called Boolean.
Topoi and Logic
In set theory, a characteristic function may be interpreted as defining a property of the elements of a set — a predicate that is true for some elements and false for others. The predicate isEven selects a subset of even numbers from the set of natural numbers. In a topos, we can generalize the idea of a predicate to be a morphism from object a to Ω. This is why Ω is sometimes called the truth object.
Predicates are the building blocks of logic. A topos contains all the necessary instrumentation to study logic. It has products that correspond to logical conjunctions (logical and), coproducts for disjunctions (logical or), and exponentials for implications. All standard axioms of logic hold in a topos except for the law of excluded middle (or, equivalently, double negation elimination). That’s why the logic of a topos corresponds to constructive or intuitionistic logic.
Intuitionistic logic has been steadily gaining ground, finding unexpected support from computer science. The classical notion of excluded middle is based on the belief that there is absolute truth: Any statement is either true or false or, as Ancient Romans would say, tertium non datur (there is no third option). But the only way we can know whether something is true or false is if we can prove or disprove it. A proof is a process, a computation — and we know that computations take time and resources. In some cases, they may never terminate. It doesn’t make sense to claim that a statement is true if we cannot prove it in finite amount of time. A topos with its more nuanced truth object provides a more general framework for modeling interesting logics.
Next: Lawvere Theories.
Challenges
- Show that the function
f that is the pullback of true along the characteristic function must be injective.
Abstract: I present a uniform derivation of profunctor optics: isos, lenses, prisms, and grates based on the Yoneda lemma in the (enriched) profunctor category. In particular, lenses and prisms correspond to Tambara modules with the cartesian and cocartesian tensor product.
This blog post is the result of a collaboration between many people. The categorical profunctor picture solidified after long discussions with Edward Kmett. A lot of the theory was developed in exchanges on the Lens IRC channel between Russell O’Connor, Edward Kmett and James Deikun. They came up with the idea to use the Pastro functor to freely generate Tambara modules, which was the missing piece that completed the picture.
My interest in lenses started long time ago when I first made the connection between the universal quantification over functors in the van Laarhoven representation of lenses and the Yoneda lemma. Since I was still learning the basics of category theory, it took me a long time to find the right language to make the formal derivation. Unbeknownst to me Mauro Jaskellioff and Russell O’Connor independently had the same idea and they published a paper about it soon after I published my blog. But even though this solved the problem of lenses, prisms still seemed out of reach of the Yoneda lemma. Prisms require a more general formulation using universal quantification over profunctors. I was able to put a dent in it by deriving Isos from profunctor Yoneda, but then I was stuck again. I shared my ideas with Russell, who reached for help on the IRC channel, and a Haskell proof of concept was quickly established. Two years later, after a brainstorm with Edward, I was finally able to gather all these ideas in one place and give them a little categorical polish.
Yoneda Lemma
The starting point is the Yoneda lemma, which states that the set of natural transformations between the hom-functor C(a, -) in the category C and an arbitrary functor f from C to Set is (naturally) isomorphic with the set f a:
[C, Set](C(a, -), f) ≅ f a
Here, f is a member of the functor category [C, Set], where natural transformation form hom-sets.
The set of natural transformations may be represented as an end, leading to the following formulation of the Yoneda lemma:
∫x Set(C(a, x), f x) ≅ f a
This notation makes the object x explicit, which is often very convenient. It can be easily translated to Haskell, by replacing the end with the universal quantifier. We get:
forall x. (a -> x) -> f x ≅ f a
A special case of the Yoneda lemma replaces the functor f with a hom-functor in C:
f x = C(b, x)
and we get:
∫x Set(C(a, x), C(b, x)) ≅ C(b, a)
This form of the Yoneda lemma is useful in showing the Yoneda embedding, which states that any category C can be fully and faithfully embedded in the functor category [C, Set]. The embedding is a functor, and the above formula defines its action on morphisms.
We will be interested in using the Yoneda lemma in the functor category. We simply replace C with [C, Set] in the previous formula, and do some renaming of variables:
∫f Set([C, Set](g, f), [C, Set](h, f)) ≅ [C, Set](h, g)
The hom-sets in the functor category are sets of natural transformations, which can be rewritten using ends:
∫f Set(∫x Set(g x, f x), ∫x Set(h x, f x))
≅ ∫x Set(h x, g x)
Adjunctions
This is a short recap of adjunctions. We start with two functors going between two categories C and D:
L :: C -> D
R :: D -> C
We say that L is left adjoint to R iff there is a natural isomorphism between hom-sets:
D(L x, y) ≅ C(x, R y)
In particular, we can define an adjunction in a functor category [C, Set]. We start with two higher order (endo-) functors:
L :: [C, Set] -> [C, Set]
R :: [C, Set] -> [C, Set]
We say that L is left adjoint to R iff there is a natural isomorphism between two sets of natural transformations:
[C, Set](L f, g) ≅ [C, Set](f, R g)
where f and g are functors from C to Set. We can rewrite natural transformations using ends:
∫x Set((L f) x, g x) ≅ ∫x Set(f x, (R g) x)
In Haskell, you may think of f and g as type constructors (with the corresponding Functor instances), in which case L and R are types that are parameterized by these type constructors (similar to how the monad or functor classes are).
Yoneda with Adjunction
Here’s a little trick. Since the fixed objects in the formula for Yoneda embedding are arbitrary, we can pick them to be images of other objects under some functor L that we know is left adjoint to another functor R:
∫x Set(D(L a, x), D(L b, x)) ≅ D(L b, L a)
Using the adjunction, this is isomorphic to:
∫x Set(C(a, R x), C(b, R x)) ≅ C(b, (R ∘ L) a)
Notice that the composition R ∘ L of adjoint functors is a monad in C. Let’s write this monad as Φ.
The interesting case is the adjunction between a forgetful functor U and a free functor F. We get:
∫x Set(C(a, U x), C(b, U x)) ≅ C(b, Φ a)
The end is taken over x in a category D that has some additional structure (we’ll see examples of that later); but the hom-sets are in the underlying simpler category C, which is the target of the forgetful functor U.
The Yoneda-with-adjunction formula generalizes to the category of functors:
∫f Set(∫x Set((L g) x, f x), ∫x Set((L h) x, f x))
≅ ∫x Set((L h) x, (L g) x)
leading to:
∫f Set(∫x Set((g x, (R f) x), ∫x Set(h x, (R f) x))
≅ ∫x Set(h x, (Φ g) x)
Here, Φ is the monad R ∘ L in the category of functors.
An interesting special case is when we substitute hom-functors for g and h:
g x = C(a, x)
h x = C(s, x)
We get:
∫f Set(∫x Set((C(a, x), (R f) x), ∫x Set(C(s, x), (R f) x))
≅ ∫x Set(C(s, x), (Φ C(a, -)) x)
We can then use the regular Yoneda lemma to “integrate over x” and reduce it down to:
∫f Set((R f) a, (R f) s)) ≅ (Φ C(a, -)) s
Again, we are particularly interested in the forgetful/free adjunction:
∫f Set((U f) a, (U f) s)) ≅ (Φ C(a, -)) s
with the monad:
Φ = U ∘ F
The simplest application of this identity is when the functors in question are identity functors. We get:
∫f Set(f a, f s)) ≅ C(a, s)
In Haskell this becomes:
forall f. Functor f => f a -> f s ≅ a -> s
You may think of this formula as defining the trivial kind of optic that simply turns a to s.
Profunctors
Profunctors are just functors from a product category Cop×D to Set. All the results from the last section can be directly applied to the profunctor category [Cop×D, Set]. Keep in mind that morphisms in this category are natural transformations between profunctors. Here’s the key formula:
∫p Set((U p)<a, b>, (U p)<s, t>)) ≅ (Φ (Cop×D)(<a, b>, -)) <s, t>
I have replaced a with a pair <a, b> and s with a pair <s, t>. The end is taken over all profunctors that exhibit some structure that U forgets, and F freely creates. Φ is the monad U ∘ F. It’s a monad that acts on profunctors to produce other profunctors.
Notice that a hom-set in the category Cop×D is a set of pairs of morphisms:
<f, g> :: (Cop×D)(<a, b>, <s, t>)
f :: s -> a
g :: b -> t
the first one going in the opposite direction.
The simplest application of this identity is when we don’t impose any constraints on the profunctors, in which case Φ is the identity monad. We get:
∫p Set(p <a, b>, p <s, t>) ≅ (Cop×D)(<a, b>, <s, t>)
Haskell translation of this formula gives the well-known representation of Iso:
forall p. Profunctor p => p a b -> p s t ≅ Iso s t a b
where:
data Iso s t a b = Iso (s -> a) (b -> t)
Interesting things happen when we impose more structure on our profunctors.
Enriched Categories
First, let’s generalize profunctors to work on enriched categories. We start with some monoidal category V whose objects serve as hom-objects in an enriched category A. The category V will essentially replace Set in our constructions. For instance, we’ll work with profunctors that are enriched functors from the (enriched) product category to V:
p :: Aop ⊗ A -> V
Notice that we use a tensor product of categories. The objects in such a category are pairs of objects, and the hom-objects are tensor products of individual hom-objects. The definition of composition in a product category requires that the tensor product in V be symmetric (up to isomorphism).
For such profunctors, there is a suitable generalization of the end:
∫x p x x
It’s an object in V together with a V-natural family of projections:
pry :: ∫x p x x -> p y y
We can formulate the Yoneda lemma in an enriched setting by considering enriched functors from A to V. We get the following generalization:
∫x [A(a, x), f x] ≅ f a
Notice that A(a, x) is now an object of V — the hom-object from a to x. The notation [v, w] generalizes the internal hom. It is defined as the right adjoint to the tensor product in V:
V(x ⊗ v, w) ≅ V(x, [v, w])
We are assuming that V is closed, so the internal hom is defined for every pair of objects.
Enriched functors, or V-functors, between two enriched categories C and D form a functor category [C, D] that is itself enriched over V. The hom-object between two functors f and g is given by the end:
[C, D](f, g) = ∫x D(f x, g x)
We can therefore use the Yoneda lemma in a category of enriched functors, or in the category of enriched profunctors. Therefore the result of the previous section holds in the enriched setting as well:
∫p [(U p)<a, b>, (U p)<s, t>] ≅ (Φ (Aop⊗A)(<a, b>, -)) <s, t>
with the understanding that:
(Aop⊗A)(<a, b>, -))
is an enriched hom functor mapping pairs of objects in A to objects in V, plus the appropriate action on hom-objects. This hom-functor is the profunctor on which Φ acts.
Tambara Modules
An enriched category A may have a monoidal structure of its own. We’ll use the same tensor product notation for its structure as we did for the underlying monoidal category V. There is also a tensorial unit object i in A.
A Tambara module is a V-functor p from Aop⊗A to V, which transforms under the tensor action of A according to a family of morphisms, natural in all three arguments:
α a x y :: p x y -> p (a ⊗ x) (a ⊗ y)
Notice that these are morphisms in the underlying category V, which is also the target of the profunctor.
We impose the usual unit law:
α i x y = id
and associativity:
α a⊗b x y = α a b⊗x b⊗y ∘ α b x y
Strictly speaking one can separately define left and right action but, for simplicity, we’ll assume that the product is symmetric (up to isomorphism).
The intuition behind Tambara modules is that some of the profunctor values are not independent of others. Once we have calculated p x y, we can obtain the value of p at any of the points on the path <a⊗x, a⊗y> by applying α.
Tambara modules form a category that’s enriched over V. The construction of this enrichment is non-trivial. The hom-object between two profunctors p and q in a category of profunctors is given by the end:
[Aop⊗A, V](p, q) = ∫<x y> V(p x y, q x y)
This object generalizes the set of natural transformations. Conceptually, not all natural transformation preserve the Tambara structure, so we have to define a subobject of this hom-object that does. The intuition is that the end is a generalized product of its components. It comes equipped with projections. For instance, the projection pr<x,y> picks the component:
V(p x y, q x y)
But there is also a projection pr<a⊗x, a⊗y> that picks:
V(p a⊗x a⊗y, q a⊗x a⊗y)
from the same end. These two objects are not completely independent, because they can both be transformed into the same object. We have:
V(id, αa) :: V(p x y, q x y) -> V(p x y, q a⊗x a⊗y)
V(αa, id) :: V(a⊗x a⊗y, q a⊗x a⊗y) -> V(p x y, q a⊗x a⊗y)
We are using the fact that the mapping:
<v, w> -> V(v, w)
is itself a profunctor Vop×V -> V, so it can be used to lift pairs of morphisms in V.
Now, given any triple a, x, and y, we want the two paths to be equivalent, which means finding the equalizer between each pair of morphisms:
V(id, αa) ∘ pr<x, y>
V(αa, id) ∘ pr<a⊗x, a⊗y>

Since we want our hom-object to satisfy the above condition for any triple, we have to construct it as an intersection of all those equalizers. Here, an intersection means an object of V together with a family of monomorphisms, each embedding it into a particular equalizer.
It’s possible to construct a forgetful functor from the Tambara category to the category of profunctors [Aop⊗A, V]. It forgets the existence of α and it maps hom-objects between the two categories. Composition in the Tambara category is defined is such a way as to be compatible with this forgetful functor.
The fact that Tambara modules form a category is important, because we want to be able to use the Yoneda lemma in that category.
Tambara Optics
The key observation is that the forgetful functor from the Tambara category has a left adjoint, and that their composition forms a monad in the category of profunctors. We’ll plug this monad into our general formula.
The construction of this monad starts with a comonad that is given by the following end:
(Θ p) s t = ∫c p (c⊗s) (c⊗t)
For a given profunctor p, this comonad builds a new profunctor that is essentially a gigantic product of all values of this profunctor “shifted” by tensoring its arguments with all possible objects c.
The monad we are interested in is the left adjoint to this comonad (calculated using a Kan extension):
(Φ p) s t = ∫ c x y A(s, c⊗x) ⊗ A(c⊗y, t) ⊗ p x y
Notice that we have two separate tensor products in this formula: one in V, between the hom-objects and the profunctor, and one in A, under the hom-objects. This monad takes an arbitrary profunctor p and produces a new profunctor Φ p.
We can now use our earlier formula:
∫p [(U p)<a, b>, (U p)<s, t>)] ≅ (Φ (Aop⊗A)(<a, b>, -)) <s, t>
inside the Tambara category. To calculate the right hand side, let’s evaluate the action of Φ on the hom-profunctor:
(Φ (Aop⊗A)(<a, b>, -)) <s, t>
= ∫ c x y A(s, c⊗x) ⊗ A(c⊗y, t) ⊗ (Aop⊗A)(<a, b>, <x, y>)
We can “integrate over” x and y using the Yoneda lemma to get:
∫ c A(s, c⊗a) ⊗ A(c⊗b, t)
We get the following result:
∫p [(U p)<a, b>, (U p)<s, t>)] ≅ ∫ c A(s, c⊗a) ⊗ A(c⊗b, t)
where the end on the left is taken over all Tambara modules, and U is the forgetful functor from the Tambara category to the category of profunctors.
If the category in question is closed, we can use the adjunction:
A(c⊗b, t) ≅ A(c, [b, t])
and “perform the integration” over c to arrive at the set/get formulation:
∫ c A(s, c⊗a) ⊗ A(c, [b, t]) ≅ A(s, [b, t]⊗a)
It corresponds to the familiar Haskell lens type:
(s -> b -> t, s -> a)
(This final trick doesn’t work for prisms, because there is no right adjoint to Either.)
Haskell Translation
A Tambara module is parameterized by the choice of the tensor product ten. We can write a general definition:
class (Profunctor p) => TamModule (ten :: * -> * -> *) p where
leftAction :: p a b -> p (c `ten` a) (c `ten` b)
rightAction :: p a b -> p (a `ten` c) (b `ten` c)
This can be further specialized for two obvious monoidal structures: product and sum:
type TamProd p = TamModule (,) p
type TamSum p = TamModule Either p
The former is equivalent to what it called a Strong (or Cartesian) profunctor in Haskell, the latter is equivalent to a Choice (or Cocartesian) profunctor.
Replacing ends and coends with universal and existential quantifiers in Haskell, our main formula becomes (pseudocode):
forall p. TamModule ten p => p a b -> p s t
≅ exists c. (s -> c `ten` a, c `ten` b -> t)
The two sides of the isomorphism can be defined as the following data structures:
type TamOptic ten s t a b
= forall p. TamModule ten p => p a b -> p s t
data Optic ten s t a b
= forall c. Optic (s -> c `ten` a) (c `ten` b -> t)
Chosing product for the tensor, we recover two equivalent definitions of a lens:
type Lens s t a b = forall p. Strong p => p a b -> p s t
data Lens s t a b = forall c. Lens (s -> (c, a)) ((c, b) -> t)
Chosing the coproduct, we get:
type Prism s t a b = forall p. Choice p => p a b -> p s t
data Prism s t a b = forall c. Prism (s -> Either c a) (Either c b -> t)
These are the well-known existential representations of lenses and prisms.
The monad Φ (or, equivalently, the free functor that generates Tambara modules), is known in Haskell under the name Pastro for product, and Copastro for coproduct:
data Pastro p a b where
Pastro :: ((y, z) -> b) -> p x y -> (a -> (x, z))
-> Pastro p a b
data Copastro p a b where
Copastro :: (Either y z -> b) -> p x y -> (a -> Either x z)
-> Copastro p a b
They are the left adjoints of Tambara and Cotambara, respectively:
newtype Tambara p a b = Tambara forall c. p (a, c) (b, c)
newtype Cotambara p a b = Cotambara forall c. p (Either a c) (Either b c)
which are special cases of the comonad Θ.
Discussion
It’s interesting that the work on Tambara modules has relevance to Haskell optics. It is, however, just one example of an even larger pattern.
The pattern is that we have a family of transformations in some category A. These transformations can be used to select a class of profunctors that have simple transformation laws. Using a tensor product in a monoidal category to transform objects, in essence “multiplying” them, is just one example of such symmetry. A more general pattern involves a family of transformations f that is closed under composition and includes a unit. We specify a transformation law for profunctors:
class Profunctor p => Related p where
α f a b :: forall f. Trans f => p a b -> p (f a) (f b)
This requirement picks a class of profunctors that we call Related.
Why are profunctors relevant as carriers of symmetry? It’s because they generalize a relationship between objects. The profunctor transformation law essentially says that if two objects a and b are related through p then so are the transformed objects; and that there is a function α that relates the proofs of this relationship. This is in the spirit of profunctors as proof-relevant relations.
As an analogy, imagine that we are comparing people, and the transformation we’re interested in is aging. We notice that family relationships remain invariant under aging: if a is a sibling of b, they will remain siblings as they age. This is not true about other relationships, for instance being a boss of another person. But family bonds are not the only ones that survive the test of time. Another such relation is being older or younger than the other person.
Now imagine that you pick four people at random points in time and you find out that any time-invariant relation between two of them, a and b, also holds between s and t. You have to conclude that there is some connection between s and age-adjusted a, and between age-adjusted b and t. In other words there exists a time shift that transforms one pair to another.
Considering all possible relations from the class Related corresponds to taking the end over all profunctors from this class:
type Optic p s t a b = forall p. Related p =>
p a b -> p s t
The end is a generalization of a product, so it’s enough that one of the components is empty for the whole end to be empty. It means that, for a particular choice of the four types a, b, s, and t, we have to be able to construct a whole family of morphisms, one for every p. We have seen that this end exists only if the four types are connected in a very peculiar way — for instance, if a and b are somehow embedded in s and t.
In the simplest case, we may choose the four types to be related by the transformation:
s = f a
t = f b
For these types, we know that the end exists:
forall p. Related p =>
p a b -> p s t
because there is a family of appropriate morphisms: our αf a b. In general, though, we can get away with weaker connection.
Let’s look at an example of a family of transformations generated by pairing with arbitrary type c:
fc a = (c, a)
Profunctors that respect these transformations are Tambara modules over a cartesian product (or, in lens parlance, Strong profunctors). For the choice:
s = (c, a)
t = (c, b)
the end in question trivially exists. As we’ve seen, we can weaken these conditions. It’s enough that one way (lax) transformations exist:
s -> (c, a)
t <- (c, b)
These morphisms assert that s can be split into a pair, and that t can be constructed from a pair (but not the other way around).
Other Optics
With the understanding that optics may be defined using a family of transformations, we can analyze another optic called the Grate. It’s based on the following family:
type Reader e a = e -> a
Notice that, unlike the case of Tambara modules, this family is parameterized by a contravariant parameter e.
We are interested in profunctors that transform under these transformations:
class Profunctor p => Closed p where
closed :: p a b -> p (x -> a) (x -> b)
They let us form the optic:
type Grate s t a b = forall p. Closed p => p a b -> p s t
It turns out that there is a profunctor functor that freely generates Closed profunctors. We have the obvious comonad:
newtype Closure p a b = Closure forall x. p (x -> a) (x -> b)
and its adjoint monad:
data Environment p u v where
Environment :: ((c -> y) -> v) -> p x y -> (u -> (c -> x))
-> Environment p a b
or, in categorical notation:
(Φ p) u v = ∫ c x y A([c, y], v) ⊗ p x y ⊗ A(u, [c, x])
Using our construction, we apply this monad to the hom-profunctor:
(Φ (Aop⊗A)(<a, b>, -)) <s, t>
= ∫ c x y A([c, y], t) ⊗ (Aop⊗A)(<a, b>, <x, y>) ⊗ A(s, [c, x])
≅ ∫ c A([c, b], t) ⊗ A(s, [c, a])
Translating it back to Haskell, we get a representation of Grate as an existential type:
Grate s t a b = forall c. Grate ((c -> b) -> t) (s -> (c -> a))
This is very similar to the existential representation of a lens or a prism. It has the intuitive interpretation that s can be thought of as a container of a‘s indexed by some hidden type c.
We can also “perform the integration” using the Yoneda lemma, internal-hom-adjunction, and the symmetry of the product:
∫ c A([c, b], t) ⊗ A(s, [c, a])
≅ ∫ c A([c, b], t) ⊗ A(s ⊗ c, a)
≅ ∫ c A([c, b], t) ⊗ A(c, [s, a])
≅ A([[s, a], b], t)
to get the more familiar form:
Grate s t a b ≅ ((s -> a) -> b) -> t
Conclusion
I find it fascinating that constructions that were first discovered in Haskell to make Haskell’s optics composable have their categorical counterparts. This was not at all obvious, if only because some of them use parametricity arguments. Parametricity is the property of the language, not easily translatable to category theory. Now we know that the profunctor formulation of isos, lenses, prisms, and grates follows from the Yoneda lemma. The work is not complete yet. I haven’t been able to derive the same formulation for traversals, which combine two different tensor products plus some monoidal constraints.
Bibliography
- Haskell lens library, Edward Kmett
- Distributors on a tensor category, D. Tambara
- Doubles for monoidal categories, Craig Pastro, Ross Street
- Profunctor optics, Modular data accessors,
Matthew Pickering, Jeremy Gibbons, and Nicolas Wu
- CPS based functional references, Twan van Laarhoven
- Isomorphism lenses, Twan van Laarhoven
- Theorem for Second-Order Functionals, Mauro Jaskellioff and Russell O’Connor