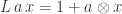This post is based on the talk I gave in Moscow, Russia, in February 2015 to an audience of C++ programmers.
Let’s agree on some preliminaries.
C++ is a low level programming language. It’s very close to the machine. C++ is engineering at its grittiest.
Category theory is the most abstract branch of mathematics. It’s very very high in the layers of abstraction. Category theory is mathematics at its highest.
So why have I decided to speak about category theory to C++ programmers? There are many reasons.
The main reason is that category theory captures the essence of programming. We can program at many levels, and if I ask somebody “What is programming?” most C++ programmers will probably say that it’s about telling the computer what to do. How to move bytes from memory to the processor, how to manipulate them, and so on.
But there is another view of programming and it’s related to the human side of programming. We are humans writing programs. We decide what to tell the computer to do.
We are solving problems. We are finding solutions to problems and translating them in the language that is understandable to the computer.
But what is problem solving? How do we, humans, approach problem solving? It was only a recent development in our evolution that we have acquired these fantastic brains of ours. For hundreds of millions of years not much was happening under the hood, and suddenly we got this brain, and we used this brain to help us chase animals, shoot arrows, find mates, organize hunting parties, and so on. It’s been going on for a few hundred thousand years. And suddenly the same brain is supposed to solve problems in software engineering.
So how do we approach problem solving? There is one general approach that we humans have developed for problem solving. We had to develop it because of the limitations of our brain, not because of the limitations of computers or our tools. Our brains have this relatively small cache memory, so when we’re dealing with a huge problem, we have to split it into smaller parts. We have to decompose bigger problems into smaller problems. And this is very human. This is what we do. We decompose, and then we attack each problem separately, find the solution; and once we have solutions to all the smaller problems, we recompose them.
So the essence of programming is composition.
If we want to be good programmers, we have to understand composition. And who knows more about composing than musicians? They are the original composers!
So let me show you an example. This is a piece by Johann Sebastian Bach. I’ll show you two versions of this composition. One is low level, and one is high level.
The low level is just sampled sound. These are bytes that approximate the waveform of the sound.

And this is the same piece in typical music notation.

Which one is easier to manipulate? Which one is easier to reason about? Obviously, the high level one!
Notice that, in the high level language, we use a lot of different abstractions that can be processed separately. We split the problem into smaller parts. We know that there are things called notes, and they can be reproduced, in this particular case, using violins. There are also some letters like E, A, B7: these are chords. They describe harmony. There is melody, there is harmony, there is the bass line.
Musicians, when they compose music, use higher level abstractions. These higher level abstractions are easier to manipulate, reason about, and modify when necessary.
And this is probably what Bach was hearing in his head.
And he chose to represent it using the high level language of musical notation.
Now, if you’re a rap musician, you work with samples, and you learn how to manipulate the low level description of music. It’s a very different process. It’s much closer to low-level C++ programming. We often do copy and paste, just like rap musicians. There’s nothing wrong with that, but sometimes we would like to be more like Bach.
So how do we approach this problem as programmers and not as musicians. We cannot use musical notation to lift ourselves to higher levels of abstraction. We have to use mathematics. And there is one particular branch of mathematics, category theory, that is exactly about composition. If programming is about composition, then this is what we should be looking at.
Category theory, in general, is not easy to learn, but the basic concepts of category theory are embarrassingly simple. So I will talk about some of those embarrassingly simple concepts from category theory, and then explain how to use them in programming in some weird ways that would probably not have occurred to you when you’re programming.
Categories
So what is this concept of a category? Two things: object and arrows between objects.
In category theory you don’t ask what these objects are. You call them objects, you give them names like A, B, C, D, etc., but you don’t ask what they are or what’s inside them. And then you have arrows that connect objects. Every arrow starts at some object and ends at some object. You can have many arrows going between two objects, or none whatsoever. Again, you don’t ask what these arrows are. You just give them names like f, g, h, etc.
And that’s it—that’s how you visualize a category: a bunch of objects and a bunch of arrows between them.
There are some operations on arrows and some laws that they have to obey, and they are also very simple.
Since composition is the essence of category theory (and of programming), we have to define composition in a category.

Whenever you have an arrow f going from object A to object B, here represented by two little piggies, and another arrow g going from object B to object C, there is an arrow called their composition, g ∘ f, that goes directly from object A to object C. We pronounce this “g after f.”
Composition is part of the definition of a category. Again, since we don’t know what these arrows are, we don’t ask what composition is. We just know that for any two composable arrows — such that the end of one coincides with the start of the other — there exists another arrow that’s their composition.
And this is exactly what we do when we solve problems. We find an arrow from A to B — that’s our subproblem. We find an arrow from B to C, that’s another subproblem. And then we compose them to get an arrow from A to C, and that’s a solution to our bigger problem. We can repeat this process, building larger and larger solutions by solving smaller problems and composing the solutions.
Notice that when we have three arrows to compose, there are two ways of doing that, depending on which pair we compose first. We don’t want composition to have history. We want to be able to say: This arrow is a composition of these three arrows: f after g after h, without having to use parentheses for grouping. That’s called associativity:
(f ∘ g) ∘ h = f ∘ (g ∘ h)
Composition in a category must be associative.
And finally, every object has to have an identity arrow. It’s an arrow that goes from the object back to itself. You can have many arrows that loop back to the same object. But there is always one such loop for every object that is the identity with respect to composition.

It has the property that if you compose it with any other arrow that’s composable with it — meaning it either starts or ends at this object — you get that arrow back. It acts like multiplication by one. It’s an identity — it doesn’t change anything.
Monoid
I can immediately give you an example of a very simple category that I’m sure you know very well and have used all your adult life. It’s called a monoid. It’s another embarrassingly simple concept. It’s a category that has only one object. It may have lots of arrows, but all these arrows have to start at this object and end at this object, so they are all composable. You can compose any two arrows in this category to get another arrow. And there is one arrow that’s the identity. When composed with any other arrow it will give you back the same arrow.

There are some very simple examples of monoids. We have natural numbers with addition and zero. An arrow corresponds to adding a number. For instance, you will have an arrow that corresponds to adding 5. You compose it with an arrow that corresponds to adding 3, and you get an arrow that corresponds to adding 8. Identity arrow corresponds to adding zero.
Multiplication forms a monoid too. The identity arrow corresponds to multiplying by 1. The composition rule for these arrows is just a multiplication table.
Strings form another interesting monoid. An arrow corresponds to appending a particular string. Unit arrow appends an empty string. What’s interesting about this monoid is that it has no additional structure. In particular, it doesn’t have an inverse for any of its arrows. There are no “negative” strings. There is no anti-“world” string that, when appended to “Hello world”, would result in the string “Hello“.
In each of these monoids, you can think of the one object as being a set: a set of all numbers, or a set of all strings. But that’s just an aid to imagination. All information about the monoid is in the composition rules — the multiplication table for arrows.
In programming we encounter monoids all over the place. We just normally don’t call them that. But every time you have something like logging, gathering data, or auditing, you are using a monoid structure. You’re basically adding some information to a log, appending, or concatenating, so that’s a monoidal operation. And there is an identity log entry that you may use when you have nothing interesting to add.
Types and Functions
So monoid is one example, but there is something closer to our hearts as programmers, and that’s the category of types and functions. And the funny thing is that this category of types and functions is actually almost enough to do programming, and in functional languages that’s what people do. In C++ there is a little bit more noise, so it’s harder to abstract this part of programming, but we do have types — it’s a strongly typed language, modulo implicit conversions. And we do have functions. So let’s see why this is a category and how it’s used in programming.
This category is actually called Set — a category of sets — because, to the lowest approximation, types are just sets of values. The type bool is a set of two values, true and false. The type int is a set of integers from something like negative two billion to two billion (on a 32-bit machine). All types are sets: whether it’s numbers, enums, structs, or objects of a class. There could be an infinite set of possible values, but it’s okay — a set may be infinite. And functions are just mappings between these sets. I’m talking about the simplest functions, ones that take just one value of some type and return another value of another type. So these are arrows from one type to another.
Can we compose these functions? Of course we can. We do it all the time. We call one function, it returns some value, and with this value we call another function. That’s function composition. In fact this is the basis of procedural decomposition, the first serious approach to formalizing problem solving in programming.
Here’s a piece of C++ code that composes two functions f and g.
C g_after_f(A x) {
B y = f(x);
return g(y);
}
In modern C++ you can make this code generic — a higher order function that accepts two functions and returns a third function that’s the composition of the two.
Can you compose any two functions? Yes — if they are composable. The output type of one must match the input type of another. That’s the essence of strong typing in C++ (modulo implicit conversions).
Is there an identity function? Well, in C++ we don’t have an identity function in the library, which is too bad. That’s because there’s a complex issue of how you pass things: is it by value, by reference, by const reference, by move, and so on. But in functional languages there is just one function called identity. It takes an argument and returns it back. But even in C++, if you limit yourself to functions that take arguments by value and return values, then it’s very easy to define a generic identity function.
Notice that the functions I’m talking about are actually special kind of functions called pure functions. They can’t have any side effects. Mathematically, a function is just a mapping from one set to another set, so it can’t have side effects. Also, a pure function must return the same value when called with the same arguments. This is called referential transparency.
A pure function doesn’t have any memory or state. It doesn’t have static variables, and doesn’t use globals. A pure function is an ideal we strive towards in programming, especially when writing reusable components and libraries. We don’t like having global variables, and we don’t like state hidden in static variables.
Moreover, if a function is pure, you can memoize it. If a function takes a long time to evaluate, maybe you’ll want to cache the value, so it can be retrieved quickly next time you call it with the same arguments.
Another property of pure functions is that all dependencies in your code only come through composition. If the result of one function is used as an argument to another then obviously you can’t run them in parallel or reverse the order of execution. You have to call them in that particular order. You have to sequence their execution. The dependencies between functions are fully explicit. This is not true for functions that have side effects. They may look like independent functions, but they have to be executed in sequence, or their side effects will be different.
We know that compiler optimizers will try to rearrange our code, but it’s very hard to do it in C++ because of hidden dependencies. If you have two functions that are not composed, they just calculate different things, and you try to call them in a different order, you might get a completely different result. It’s because of the order of side effects, which are invisible to the compiler. You would have to go deep into the implementation of the functions; you would have to analyse everything they are doing, and the functions they are calling, and so on, in order to find out what these side effects are; and only then you could decide: Oh, I can swap these two functions.
In functional programming, where you only deal with pure functions, you can swap any two functions that are not explicitly composed, and composition is immediately visible.
At this point I would expect half of the audience to leave and say: “You can’t program with pure functions, Programming is all about side effects.” And it’s true. So in order to keep you here I will have to explain how to deal with side effects. But it’s important that you start with something that is easy to understand, something you can reason about, like pure functions, and then build side effects on top of these things, so you can build up abstractions on top of other abstractions.
You start with pure functions and then you talk about side effects, not the other way around.
Auditing
Instead of explaining the general theory of side effects in category theory, I’ll give you an example from programming. Let’s solve this simple problem that, in all likelihood, most C++ programmers would solve using side effects. It’s about auditing.
You start with a sequence of functions that you want to compose. For instance, you have a function getKey. You give it a password and it returns a key. And you have another function, withdraw. You give it a key and gives you back money. You want to compose these two functions, so you start with a password and you get money. Excellent!
But now you have a new requirement: you want to have an audit trail. Every time one of these functions is called, you want to log something in the audit trail, so that you’ll know what things have happened and in what order. That’s a side effect, right?
How do we solve this problem? Well, how about creating a global variable to store the audit trail? That’s the simplest solution that comes to mind. And it’s exactly the same method that’s used for standard output in C++, with the global object std::cout. The functions that access a global variable are obviously not pure functions, we are talking about side effects.
string audit;
int logIn(string passwd){
audit += passwd;
return 42;
}
double withdraw(int key){
audit += “withdrawing ”;
return 100.0;
}
So we have a string, audit, it’s a global variable, and in each of these functions we access this global variable and append something to it. For simplicity, I’m just returning some fake numbers, not to complicate things.
This is not a good solution, for many reasons. It doesn’t scale very well. It’s difficult to maintain. If you want to change the name of the variable, you’d have to go through all this code and modify it. And if, at some point, you decide you want to log more information, not just a string but maybe a timestamp as well, then you have to go through all this code again and modify everything. And I’m not even mentioning concurrency. So this is not the best solution.
But there is another solution that’s really pure. It’s based on the idea that whatever you’re accessing in a function, you should pass explicitly to it, and then return it, with modifications, from the function. That’s pure. So here’s the next solution.
pair<int, string>
logIn(string passwd, string audit){
return make_pair(42, audit + passwd);
}
pair<double, string>
withdraw(int key, string audit){
return make_pair(100.0
, audit + “withdrawing ”);
}
You modify all the functions so that they take an additional argument, the audit string. And the return type is also changed. When we had an int before, it’s now a pair of int and string. When we had a double before, it’s now a pair of double and string. These function now call make_pair before they return, and they put in whatever they were returning before, plus they do this concatenation of a new message at the end of the old audit string. This is a better solution because it uses pure functions. They only depend on their arguments. They don’t have any state, they don’t access any global variables. Every time you call them with the same arguments, they produce the same result.
The problem though is that they don’t memoize that well. Look at the function logIn: you normally get the same key for the same password. But if you want to memoize it when it takes two arguments, you suddenly have to memoize it for all possible histories. Even if you call it with the same password, but the audit string is different, you can’t just access the cache, you have to cache a new pair of values. Your cache explodes with all possible histories.
An even bigger problem is security. Each of these functions has access to the complete log, including the passwords.
Also, each of these functions has to care about things that maybe it shouldn’t be bothered with. It knows about how to concatenate strings. It knows the details of the implementation of the log: that the log is a string. It must know how to accumulate the log.
Now I want to show you a solution that maybe is not that obvious, maybe a little outside of what we would normally think of.
pair<int, string>
logIn(string passwd){
return make_pair(42, passwd);
}
pair<double, string>
withdraw(int key){
return make_pair(100.0
,“withdrawing ”);
}
We use modified functions, but they don’t take the audit string any more. They just return a pair of whatever they were returning before, plus a string. But each of them only creates a message about what it considers important. It doesn’t have access to any log and it doesn’t know how to work with an audit trail. It’s just doing its local thing. It’s only responsible for its local data. It’s not responsible for concatenation.
It still creates a pair and it has a modified return type.
We have one problem though: we don’t know how to compose these functions. We can’t pass a pair of key and string from logIn to withdraw, because withdraw expects an int. Of course we could extract the int and drop the string, but that would defeat the goal of auditing the code.
Let’s go back a little bit and see how we can abstract this thing. We have functions that used to return some types, and now they return pairs of the original type and a string. This should in principle work with any original type, not just an int or a double. In functional programming we call this “lifting.” Here we lift some type A to a new type, which is a pair of A and a string. Or we can say that we are “embellishing” the return type of a function by pairing it with a string.
I’ll create an alias for this new parameterised type and call it Writer.
template<class A> using Writer = pair<A, string>;
My functions now return Writers: logIn returns a writer of int, and withdraw returns a writer of double. They return “embellished” types.
Writer<int> logIn(string passwd){
return make_pair(42, passwd);
}
Writer<double> withdraw(int key){
return make_pair(100.0, “withdrawing ”);
}
So how do we compose these embellished functions?
In this case we want to compose logIn with withdraw to create a new function called transact. This new function transact will take a password, log the user in, withdraw money, and return the money plus the audit trail. But it will return the audit trail only from those two functions.
Writer<double> transact(string passwd){
auto p1 logIn(passwd);
auto p2 withdraw(p1.first);
return make_pair(p2.first
, p1.second + p2.second);
}
How is it done? It’s very simple. I call the first function, logIn, with the password. It returns a pair of key and string. Then I call the second function, passing it the first component of the pair — the key. I get a new pair with the money and a string. And then I perform the composition. I take the money, which is the first component of the second pair, and I pair it with the concatenation of the two string that were the second components of the pairs returned by logIn and withdraw.
So the accumulation of the log is done “in between” the calls (think of composition as happening between calls). I have these two functions, and I’m composing them in this funny way that involves the concatenation of strings. The accumulation of the log does not happen inside these two functions, as it happened before. It happens outside. And I can pull out this code and abstract the composition. It doesn’t really matter what functions I’m calling. I can do it for any two functions that return embellished results. I can write generic code that does it and I can call it “compose”.
template<class A, class B, class C>
function<Writer<C>(A)> compose(function<Writer<B>(A)> f
,function<Writer<C>(B)> g)
{
return [f, g](A x) {
auto p1 = f(x);
auto p2 = g(p1.first);
return make_pair(p2.first
, p1.second + p2.second);
};
}
What does compose do? It takes two functions. The first function takes A and returns a Writer of B. The second function takes a B and return a Writer of C. When I compose them, I get a function that takes an A and returns a Writer of C.
This higher order function just does the composition. It has no idea that there are functions like logIn or withdraw, or any other functions that I may come up with later. It takes two embellished functions and glues them together.
We’re lucky that in modern C++ we can work with higher order functions that take functions as arguments and return other functions.
This is how I would implement the transact function using compose.
Writer<double> transact(string passwd){
return compose<string, int, double>
(logIn, withdraw)(passwd);
}
The transact function is nothing but the composition of logIn and withdraw. It doesn’t contain any other logic. I’m using this special composition because I want to create an audit trail. And the audit trail is accumulated “between” the calls — it’s in the glue that glues these two functions together.
This particular implementation of compose requires explicit type annotations, which is kind of ugly. We would like the types to be inferred. And you can do it in C++14 using generalised lambdas with return type deduction. This code was contributed by Eric Niebler.
auto const compose = [](auto f, auto g) {
return [f, g](auto x) {
auto p1 = f(x);
auto p2 = g(p1.first);
return make_pair(p2.first
, p1.second + p2.second);
};
};
Writer<double> transact(string passwd){
return compose(logIn, withdraw)(passwd);
}
Back to Categories
Now that we’ve done this example, let’s go back to where we started. In category theory we have functions and we have composition of functions. Here we also have functions and composition, but it’s a funny composition. We have functions that take simple types, but they return embellished types. The types don’t match.
Let me remind you what we had before. We had a category of types and pure functions with the obvious composition.
- Objects: types,
- Arrows: pure functions,
- Composition: pass the result of one function as the argument to another.
What we have created just now is a different category. Slightly different. It’s a category of embellished functions. Objects are still types: Types A, B, C, like integers, doubles, strings, etc. But an arrow from A to B is not a function from type A to type B. It’s a function from type A to the embellishment of the type B. The embellished type depends on the type B — in our case it was a pair type that combined B and a string — the Writer of B.
Now we have to say how to compose these arrows. It’s not as trivial as it was before. We have one arrow that takes A into a pair of B and string, and we have another arrow that takes B into a pair of C and string, and the composition should take an A and return a pair of C and string. And I have just defined this composition. I wrote code that does this:
auto const compose = [](auto f, auto g) {
return [f, g](auto x) {
auto p1 = f(x);
auto p2 = g(p1.first);
return make_pair(p2.first
, p1.second + p2.second);
};
};
So do we have a category here? A category that’s different from the original category? Yes, we do! It has composition and it has identity.
What’s its identity? It has to be an arrow from the object to itself, from A to A. But an arrow from A to A is a function from A to a pair of A and string — to a Writer of A. Can we implement something like this? Yes, easily. We will return a pair that contains the original value and the empty string. The empty string will not contribute to our audit trail.
template<class A>
Writer<A> identity(A x) {
return make_pair(x, "");
}
Is this composition associative? Yes, it is, because the underlying composition is associative, and the concatenation of strings is associative.
We have a new category. We have incorporated side effects by modifying the original category. We are still only using pure functions and yet we are able to accumulate an audit trail as a side effect. And we moved the side effects to the definition of composition.
It’s a funny new way of looking at programming. We usually see the functions, and the data being passed between functions, and here suddenly we see a new dimension to programming that is orthogonal to this, and we can manipulate it. We change the way we compose functions. We have this new power to change composition. We have a new way of solving problems by moving to these embellished functions and defining a new way of composing them. We can define new combinators to compose functions, and we’ll let the combinators do some work that we don’t want these functions to do. We can factor these things out and make them orthogonal.
Does this approach generalize?
One easy generalisation is to observe that the Writer structure works for any monoid. It doesn’t have to be just strings. Look at how composition and identity are defined in our new cateogory. The only properties of the log we are using are concatenation and unit. Concatenation must be associative for the composition to be associative. And we need a unit of concatenation so that we can define identity in our category. We don’t need anything else. This construction will work with any monoid.
And that’s great because you have one more dimension in which you can modify your code without touching the rest. You can change the format of the log, and all you need to modify in your code is compose and identity. You don’t have to go through all your functions and modify the code. They will still work because all the concatenation of logs is done inside compose.
Kleisli Categories
This was just a little taste of what is possible with category theory. The thing I called embellishment is called a functor in category theory. You can implement categorical functors in C++. There are all kinds of embellishments/functors that you can use here. And now I can tell you the secret: this funny composition of functions with the funny identity is really a monad in disguise. A monad is just a funny way of composing embellished functions so that they form a category. A category based on a monad is called a Kleisli category.
Are there any other interesting monads that I can use this construction with? Yes, lots! I’ll give you one example. Functions that return futures. That’s our new embellishment. Give me any type A and I will embellish it by making it into a future. This embellishment also produces a Kleisli category. The composition of functions that return futures is done through the combinator “then”. You call one function returning a future and compose it with another function returning a future by passing it to “then.” You can compose these function into chains without ever having to block for a thread to finish. And there is an identity, which is a function that returns a trivial future that’s always ready. It’s called make_ready_future. It’s an arrow that takes A and returns a future of A.
Now you understand what’s really happening. We are creating this new category based on future being a monad. We have new words to describe what we are doing. We are reusing an idea from category theory to solve a completely different problem.
Resumable Functions
There is one little invonvenience with this approach. It requires writing a lot of so called “boilerplate” code. Repetitive code that obscures the simple logic. Here it’s the glue code, the “compose” and the “then.” What you’d like to do is to write your code directly in terms of embellished function, and the composition to be implicit. People noticed this and came up with solutions. In case of futures, the practical solution is called resumable functions.
Resumable functions are designed to hide the composition of functions that return futures. Here’s an example.
int cnt = 0;
do
{
cnt = await streamR.read(512, buf);
if ( cnt == 0 ) break;
cnt = await streamW.write(cnt, buf);
} while (cnt > 0);
This code copies a file using a buffer, but it does it asynchronously. We call a function read that’s asynchronous. It doesn’t immediately fill the buffer, it returns a future instead. Then we call the function write that’s also asynchronous. We do it in a loop.
This code looks almost like sequential code, except that it has these await keywords. These are the points of insertion of our composition. These are the places where the code is chopped into pieces and composed using then.
I won’t go into details of the implementation. The point is that the composition of these embellished functions is almost entirely hidden. It doesn’t look like composition in a Kleisli category, but it really is.
This solution is usually described at a very low level, in terms of coroutines implemented as state machines with static variables and gotos. And what is being lost in all this engineering talk is how general this idea is — the idea of overloading composition to build a category of embellished functions.
Just to drive this home, here’s an example of different code that does completely different stuff. It calculates Fibonacci numbers on demand. It’s a generator of Fibonacci numbers.
generator<int> fib()
{
int a = 0;
int b = 1;
for (;;) {
__yield_value a;
auto next = a + b;
a = b;
b = next;
}
}
Instead of await it has __yield_value. But it’s the same idea of resumable functions, only with a different monad. This monad is called a list monad. And this kind of code in combination with Eric Niebler’s proposed range library could lead to very powerful programming idioms.
Conclusion
Why do we have to separate the two notions: that of resumable functions and that of generators, if they are based on the same abstraction? Why do we have to reinvent the wheel?
There’s this great opportunity for C++, and I’m afraid it will be missed like so many other opportunities for great generalisations that were missed in the past. It’s the opportunity to introduce one general solution based on monads, rather than keep creating ad-hoc solutions, one problem at a time. The same very general pattern can be used to control all kinds of side effects. It can be used for auditing, exceptions, ranges, futures, I/O, continuations, and all kinds of user-defined monads.
This amazing power could be ours if we start thinking in more abstract terms, if we reach into category theory.
 equipped with a pair of morphisms going to, respectively,
equipped with a pair of morphisms going to, respectively,  and
and  , there was a unique morphism
, there was a unique morphism  mapping
mapping 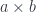 . The commuting condition ensured that the correspondence went both ways, that is, given an
. The commuting condition ensured that the correspondence went both ways, that is, given an  . So, really, we have an isomorphism between hom-sets in two categories, one in
. So, really, we have an isomorphism between hom-sets in two categories, one in 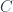 . We can also define two functors going between these categories. An arbitrary object
. We can also define two functors going between these categories. An arbitrary object 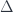 to a pair
to a pair 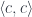 in
in  to the product
to the product 
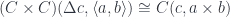
 , which is the result of applying the functor
, which is the result of applying the functor 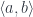 cannot be injective. It must map many different pairs to the same (up to isomorphism) product. In the process, it “forgets” some of the information, just like the number 12 forgets whether it was obtained by multiplying 2 and 6 or 3 and 4. Common examples of this forgetfulness are isomorphisms such as
cannot be injective. It must map many different pairs to the same (up to isomorphism) product. In the process, it “forgets” some of the information, just like the number 12 forgets whether it was obtained by multiplying 2 and 6 or 3 and 4. Common examples of this forgetfulness are isomorphisms such as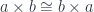

 and the unit
and the unit 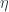 .
.
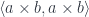 . The counit
. The counit 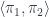 (which is a single morphism in
(which is a single morphism in  ). It’s easy to see that the family of such morphisms defines a natural transformation.
). It’s easy to see that the family of such morphisms defines a natural transformation.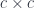 . The component of the unit natural transformation,
. The component of the unit natural transformation,  , is implemented using the universal property of the product. Indeed, such a morphism is uniquely determined by a pair of identity morphsims
, is implemented using the universal property of the product. Indeed, such a morphism is uniquely determined by a pair of identity morphsims  . Again, when we vary
. Again, when we vary 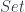 carry over to a more general setting. In a category with a terminal object, for instance, we can talk about global elements as mappings from the terminal object. In the absence of the terminal object, we may use other objects to define generalized elements. This is all in the true spirit of category theory, which defines all properties of objects in terms of morphisms.
carry over to a more general setting. In a category with a terminal object, for instance, we can talk about global elements as mappings from the terminal object. In the absence of the terminal object, we may use other objects to define generalized elements. This is all in the true spirit of category theory, which defines all properties of objects in terms of morphisms.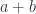 to
to 


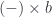 or, more explicitly:
or, more explicitly:
 is defined by the mapping-in property. The mappings out of the product
is defined by the mapping-in property. The mappings out of the product  to
to 


 . The unit is just the curried version of the product constructor.
. The unit is just the curried version of the product constructor.
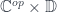 to
to 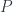 (a.k.a., a distributor, or bimodule) maps a pair of objects,
(a.k.a., a distributor, or bimodule) maps a pair of objects, 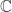 and
and  from
from 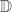 , to a set
, to a set 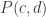 . Being a functor, it also maps any pair of morphisms in
. Being a functor, it also maps any pair of morphisms in 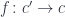
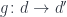
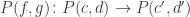
 goes in the opposite direction to what we normally expect for functors. We say that the profunctor is contravariant in its first argument and covariant in the second.
goes in the opposite direction to what we normally expect for functors. We say that the profunctor is contravariant in its first argument and covariant in the second.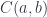 .
.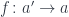
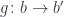
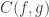 , between hom-sets:
, between hom-sets: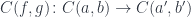
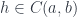 we have:
we have:
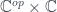 to
to 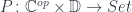
 . Their composition is another heteromorphism obtained by lifting the pair
. Their composition is another heteromorphism obtained by lifting the pair 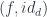 . Indeed:
. Indeed:
 to
to 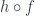 of a heteromorphism
of a heteromorphism 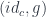 .
.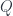 , denoted by
, denoted by 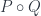 is defined as a path between objects. Objects
is defined as a path between objects. Objects 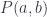 and
and 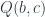 are non-empty. As a witness of this relation we can pick any pair of elements, one from
are non-empty. As a witness of this relation we can pick any pair of elements, one from 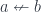 .
.
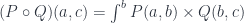
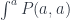 equipped with a family of injections
equipped with a family of injections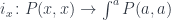
 and a family:
and a family: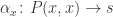
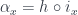

 (we’ll switch to lower case to be compatible with Haskell) as
(we’ll switch to lower case to be compatible with Haskell) as 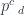 . Einstein also came up with a clever convention: implicit summation over a repeated index. In the case of profunctors, the summation corresponds to taking a coend. In this notation, a coend over a profunctor
. Einstein also came up with a clever convention: implicit summation over a repeated index. In the case of profunctors, the summation corresponds to taking a coend. In this notation, a coend over a profunctor 

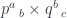
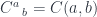
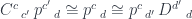
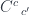 and
and 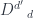 behave like Kronecker deltas (in tensor-speak) or unit matrices. Here, the profunctor
behave like Kronecker deltas (in tensor-speak) or unit matrices. Here, the profunctor 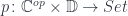
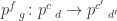

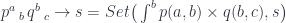
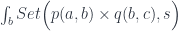
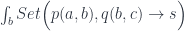

 has categories as 0-cells, profunctors as 1-cells, and natural transformations as 2-cells. A natural transformation
has categories as 0-cells, profunctors as 1-cells, and natural transformations as 2-cells. A natural transformation 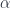 between profunctors
between profunctors 

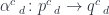
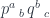 and another,
and another, 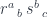 , having at our disposal two natural transformations:
, having at our disposal two natural transformations: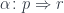
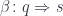
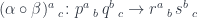
 to
to 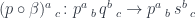
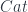 just happens to be a (strict) bicategory. It has (small) categories as 0-cells, functors as 1-cells, and natural transformations as 2-cells. A monad is defined as a combination of a 0-cell (you need a category to define a monad), an endo-1-cell (that would be an endofunctor in that category), and two 2-cells. These 2-cells are variably called multiplication and unit,
just happens to be a (strict) bicategory. It has (small) categories as 0-cells, functors as 1-cells, and natural transformations as 2-cells. A monad is defined as a combination of a 0-cell (you need a category to define a monad), an endo-1-cell (that would be an endofunctor in that category), and two 2-cells. These 2-cells are variably called multiplication and unit,  and
and 

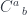 is the hom-profunctor in the category
is the hom-profunctor in the category 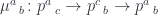
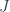 from
from 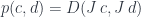
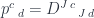
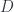 can be used to define the composition of heteromorphisms. This, in turn, can be used to define
can be used to define the composition of heteromorphisms. This, in turn, can be used to define 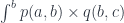
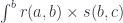

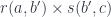 for some
for some 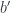 . We’ll look for a function that would construct such an element in the following hom-set:
. We’ll look for a function that would construct such an element in the following hom-set: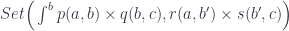
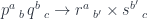
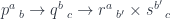
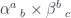 .
. , as in the diagram below (courtesy Alex Campbell).
, as in the diagram below (courtesy Alex Campbell).
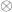 and a unit
and a unit  :
: