In my category theory blog posts, I stated many theorems, but I didn’t provide many proofs. In most cases, it’s enough to know that the proof exists. We trust mathematicians to do their job. Granted, when you’re a professional mathematician, you have to study proofs, because one day you’ll have to prove something, and it helps to know the tricks that other people used before you. But programmers are engineers, and are therefore used to taking advantage of existing solutions, trusting that somebody else made sure they were correct. So it would seem that mathematical proofs are irrelevant to programming. Or so it may seem, until you learn about the Curry-Howard isomorphism–or propositions as types, as it is sometimes called–which says that there is a one to one correspondence between logic and programs, and that every function can be seen as a proof of a theorem. And indeed, I found that a lot of proofs in category theory turn out to be recipes for implementing functions. In most cases the problem can be reduced to this: Given some morphisms, implement another morphism, usually using simple composition. This is very much like using point-free notation to define functions in Haskell. The other ingredient in categorical proofs is diagram chasing, which is very much like equational resoning in Haskell. Of course, mathematicians use different notation, and they use lots of different categories, but the principles are the same.
I want to illustrate these points with the example from Emily Riehl’s excellent book Category Theory in Context. It’s a book for mathematicians, so it’s not an easy read. I’m going to concentrate on theorem 6.2.1, which derives a formula for left Kan extensions using colimits. I picked this theorem because it has calculational content: it tells you how to calculate a particular functor.
It’s not a short proof, and I have made it even longer by unpacking every single step. These steps are not too hard, it’s mostly a matter of understanding and using definitions of functoriality, naturality, and universality.
There is a bonus at the end of this post for Haskell programmers.
Kan Extensions
I wrote about Kan extensions before, so here I’ll only recap the definition using the notation from Emily’s book. Here’s the setup: We want to extend a functor  , which goes from category
, which goes from category 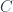 to
to 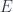 , along another functor
, along another functor 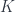 , which goes from to
, which goes from to 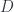 . This extension is a new functor from to .
. This extension is a new functor from to .
To give you some intuition, imagine that the functor is the Rosetta Stone. It’s a functor that maps the Ancient Egyptian text of a royal decree to the same text written in Ancient Greek. The functor embeds the Rosetta Stone hieroglyphics into the know corpus of Egyptian texts from various papyri and inscriptions on the walls of temples. We want to extend the functor to the whole corpus. In other words, we want to translate new texts from Egyptian to Greek (or whatever other language that’s isomorphic to it).
In the ideal case, we would just want to be isomorphic to the composition of the new functor after . That’s usually not possible, so we’ll settle for less. A Kan extension is a functor which, when composed with produces something that is related to through a natural transformation. In particular, the left Kan extension, 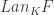 , is equipped with a natural transformation
, is equipped with a natural transformation 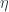 from to
from to  .
.

(The right Kan extension has this natural transformation reversed.)
There are usually many such functors, so there is the standard trick of universal construction to pick the best one.
In our analogy, we would ideally like the new functor, when applied to the hieroglyphs from the Rosetta stone, to exactly reproduce the original translation, but we’ll settle for something that has the same meaning. We’ll try to translate new hieroglyphs by looking at their relationship with known hieroglyphs. That means we should look closely at morphism in .
Comma Category
The key to understanding how Kan extensions work is to realize that, in general, the functor embeds in in a lossy way.

There may be objects (and morphisms) in that are not in the image of . We have to somehow define the action of on those objects. What do we know about such objects?
We know from the Yoneda lemma that all the information about an object is encoded in the totality of morphisms incoming to or outgoing from that object. We can summarize this information in the form of a functor, the hom-functor. Or we can define a category based on this information. This category is called the slice category. Its objects are morphisms from the original category. Notice that this is different from Yoneda, where we talked about sets of morphisms — the hom-sets. Here we treat individual morphisms as objects.
This is the definition: Given a category and a fixed object  in it, the slice category
in it, the slice category 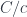 has as objects pairs
has as objects pairs 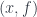 , where
, where  is an object of and
is an object of and  is a morphism from to . In other words, all the arrows whose codomain is become objects in .
is a morphism from to . In other words, all the arrows whose codomain is become objects in .
A morphism in between two objects, and  is a morphism
is a morphism 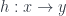 in that makes the following triangle commute:
in that makes the following triangle commute:

In our case, we are interested in an object  in , and the slice category
in , and the slice category  describes it in terms of morphisms. Think of this category as a holographic picture of .
describes it in terms of morphisms. Think of this category as a holographic picture of .
But what we are really interested in, is how to transfer this information about to . We do have a functor , which goes from to . We need to somehow back-propagate the information about to along , and then use to move it to .
So let’s try again. Instead of using all morphisms impinging on , let’s only pick the ones that originate in the image of , because only those can be back-propagated to .

This gives us limited information about , but it’ll have to do. We’ll just use a partial hologram of . Instead of the slice category, we’ll use the comma category  .
.
Here’s the definition: Given a functor  and an object of , the comma category has as objects pairs
and an object of , the comma category has as objects pairs 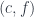 , where is an object of and is a morphism from
, where is an object of and is a morphism from  to . So, indeed, this category describes the totality of morphisms coming to from the image of .
to . So, indeed, this category describes the totality of morphisms coming to from the image of .
A morphism in the comma category from to  is a morphism
is a morphism  such that the following triangle commutes:
such that the following triangle commutes:

So how does back-propagation work? There is a projection functor  that maps an object to (with obvious action on morphisms). This functor loses a lot of information about objects (completely forgets the part), but it keeps a lot of the information in morphisms — it only picks those morphisms in that preserve the structure of the comma category. And it lets us “upload” the hologram of into
that maps an object to (with obvious action on morphisms). This functor loses a lot of information about objects (completely forgets the part), but it keeps a lot of the information in morphisms — it only picks those morphisms in that preserve the structure of the comma category. And it lets us “upload” the hologram of into
Next, we transport all this information to using . We get a mapping

Here’s the main observation: We can look at this functor  as a diagram in (remember, when constructing limits, diagrams are defined through functors). It’s just a bunch of objects and morphisms in that somehow approximate the image of . This holographic information was extracted by looking at morphisms impinging on . In our search for
as a diagram in (remember, when constructing limits, diagrams are defined through functors). It’s just a bunch of objects and morphisms in that somehow approximate the image of . This holographic information was extracted by looking at morphisms impinging on . In our search for 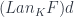 we should therefore look for an object in together with morphisms impinging on it from the diagram we’ve just constructed. In particular, we could look at cones under that diagram (or co-cones, as they are sometimes called). The best such cone defines a colimit. If that colimit exists, it is indeed the left Kan extension . That’s the theorem we are going to prove.
we should therefore look for an object in together with morphisms impinging on it from the diagram we’ve just constructed. In particular, we could look at cones under that diagram (or co-cones, as they are sometimes called). The best such cone defines a colimit. If that colimit exists, it is indeed the left Kan extension . That’s the theorem we are going to prove.

To prove it, we’ll have to go through several steps:
- Show that the mapping we have just defined on objects is indeed a functor, that is, we’ll have to define its action on morphisms.
- Construct the transformation from to and show the naturality condition.
- Prove universality: For any other functor
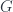 together with a natural transformation
together with a natural transformation 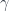 , show that uniquely factorizes through .
, show that uniquely factorizes through .
All of these things can be shown using clever manipulations of cones and the universality of the colimit. Let’s get to work.
Functoriality
We have defined the action of on objects of . Let’s pick a morphism  . Just like , the object
. Just like , the object 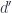 defines its own comma category
defines its own comma category  , its own projection
, its own projection  , its own diagram
, its own diagram  , and its own limiting cone. Parts of this new cone, however, can be reinterpreted as a cone for the old object . That’s because, surprisingly, the diagram contains the diagram
, and its own limiting cone. Parts of this new cone, however, can be reinterpreted as a cone for the old object . That’s because, surprisingly, the diagram contains the diagram  .
.
Take, for instance, an object  , with
, with  . There is a corresponding object
. There is a corresponding object  in . Both get projected down to the same . That shows that every object in the diagram for the cone is automatically an object in the diagram for the cone.
in . Both get projected down to the same . That shows that every object in the diagram for the cone is automatically an object in the diagram for the cone.

Now take a morphism  from to
from to  in . It is also a morphism in between and
in . It is also a morphism in between and  . The commuting triangle condition in
. The commuting triangle condition in
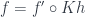
ensures the commuting condition in
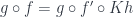

All this shows that the new cone that defines the colimit of contains a cone under .
But that diagram has its own colimit . Because that colimit is universal, there must be a unique morphism from to  , which makes all triangles between the two cones commute. We pick this morphism as the lifting of our
, which makes all triangles between the two cones commute. We pick this morphism as the lifting of our  , which ensures the functoriality of .
, which ensures the functoriality of .

The commuting condition will come in handy later, so let’s spell it out. For every object  we have a leg of the cone, a morphism
we have a leg of the cone, a morphism  from
from 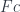 to ; and another leg of the cone
to ; and another leg of the cone  from to . If we denote the lifting of as
from to . If we denote the lifting of as 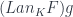 then the commuting triangle is:
then the commuting triangle is:
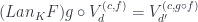

In principle, we should also check that this newly defined functor preserves composition and identity, but this pretty much follows automatically whenever lifting is defined using composition of morphisms, which is indeed the case here.
Natural Transformation
We want to show that there is a natural transformation from to . As usual, we’ll define the component of this natural transformation at some arbitrary object . It’s a morphism between and  . We have lots of morphisms at our disposal, with all those cones lying around, so it shouldn’t be a problem.
. We have lots of morphisms at our disposal, with all those cones lying around, so it shouldn’t be a problem.
First, observe that, because of the pre-composition with , we are only looking at the action of on objects which are inside the image of .

The objects of the corresponding comma category  have the form , where
have the form , where  . In particular, we can pick
. In particular, we can pick  , and
, and  , which will give us one particular vertex of the diagram
, which will give us one particular vertex of the diagram  . The object at this vertex is — exactly what we need as a starting point for our natural transformation. The leg of the colimiting cone we are interested in is:
. The object at this vertex is — exactly what we need as a starting point for our natural transformation. The leg of the colimiting cone we are interested in is:


We’ll pick this leg as the component of our natural transformation  .
.
What remains is to show the naturality condition. We pick a morphism . We know how to lift this morphism using and using . The other two sides of the naturality square are and  .
.

The bottom left composition is  . Let’s take the commuting triangle that we used to show the functoriality of :
. Let’s take the commuting triangle that we used to show the functoriality of :
and replace by  , by
, by  , by , and by
, by , and by  , to get:
, to get:

Let’s draw this as the diagonal in the naturality square, and examine the upper right composition:
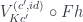 .
.
This is also equal to the diagonal  . That’s because these are two legs of the same colimiting cone corresponding to
. That’s because these are two legs of the same colimiting cone corresponding to  and
and  . These vertices are connected by in .
. These vertices are connected by in .

But how do we know that is a morphism in ? Not every morphism in is a morphism in the comma category. In this case, however, the triangle identity is automatic, because one of its sides is an identity 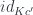 .
.

We have shown that our naturality square is composed of two commuting triangles, with as its diagonal, and therefore commutes as a whole.
Universality
Kan extension is defined using a universal construction: it’s the best of all functors that extend along . It means that any other extension will factor through ours. More precisely, if there is another functor and another natural transformation:
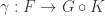

then there is a unique natural transformation  , such that
, such that


(where we have a horizontal composition of a natural transformation with the functor )
As always, we start by clearly stating the goals. The proof proceeds in these steps:
- Implement .
- Prove that it’s natural.
- Show that it factorizes through .
- Show that it’s unique.
We are defining a natural transformation between two functors: , which we have defined as a colimit, and . Both are functors from to . Let’s implement the component of at some . It must be a morphism:

Notice that varies over all of , not just the image of . We are comparing the two extensions where it really matters.
We have at our disposal the natural transformation:
or, in components:

More importantly, though, we have the universal property of the colimit. If we can construct a cone with the nadir at  then we can use its factorizing morphism to define
then we can use its factorizing morphism to define  .
.

This cone has to be built under the same diagram as . So let’s start with some  . We want to construct a leg of our new cone going from to . We can use
. We want to construct a leg of our new cone going from to . We can use  to get to
to get to  and then hop to using
and then hop to using 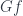 . Thus we can define the new cone’s leg as:
. Thus we can define the new cone’s leg as:


Let’s make sure that this is really a cone, meaning, its sides must be commuting triangles.

Let’s pick a morphism in from to . A morphism in must satisfy the triangle condition, :

We can lift this triangle using :

Naturality condition for tells us that:

By combining the two, we get the pentagon:

whose outline forms a commuting triangle:

Now that we have a cone with the nadir at , universality of the colimit tells us that there is a unique morphism from the colimiting cone to it that factorizes all triangles between the two cones. We make this morphism our . The commuting triangles are between the legs of the colimiting cone and the legs of our new cone  :
:


Now we have to show that so defined is a natural transformation. Let’s pick a morphism . We can lift it using or using in order to construct the naturality square:
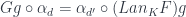

Remember that the lifting of a morphism by satisfies the following commuting condition:
We can combine the two diagrams:

The two arms of the large triangle can be replaced using the diagram that defines , and we get:
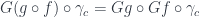
which commutes due to functoriality of .
Now we have to show that factorizes through . Both and are natural transformations between functors going from to , whereas connects functors from to . To extend , we horizontally compose it with the identity natural transformation from to . This is called whiskering and is written as  . This becomes clear when expressed in components. Let’s pick an object in . We want to show that:
. This becomes clear when expressed in components. Let’s pick an object in . We want to show that:


Let’s go back all the way to the definition of :

where 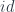 is the identity morphism at . Compare this with the definition of :
is the identity morphism at . Compare this with the definition of :

If we replace with and with , we get:
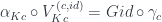

which, due to functoriality of is exactly what we need:
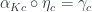
Finally, we have to prove the uniqueness of . Here’s the trick: assume that there is another natural transformation  that factorizes . Let’s rewrite the naturality condition for :
that factorizes . Let’s rewrite the naturality condition for :


Replacing with 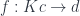 , we get:
, we get:

The lifiting of by satisfies the triangle identity:
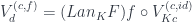
where we recognize  as .
as .

We said that factorizes through :
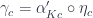
which let us straighten the left side of the pentagon.

This shows that is another factorization of the cone with the nadir at through the colimit cone with the nadir  . But that would contradict the universality of the colimit, therefore must be the same as .
. But that would contradict the universality of the colimit, therefore must be the same as .
This completes the proof.
Haskell Notes
This post would not be complete if I didn’t mention a Haskell implementation of Kan extensions by Edward Kmett, which you can find in the library Data.Functor.Kan.Lan. At first look you might not recognize the definition given there:
data Lan g h a where
Lan :: (g b -> a) -> h b -> Lan g h a
To make it more in line with the previous discussion, let’s rename some variables:
data Lan k f d where
Lan :: (k c -> d) -> f c -> Lan k f d
This is an example of GADT syntax, which is a Haskell way of implementing existential types. It’s equivalent to the following pseudo-Haskell:
Lan k f d = exists c. (k c -> d, f c)
This is more like it: you may recognize (k c -> d) as an object of the comma category , and f c as the mapping of (which is the projection of this object back to ) under the functor . In fact, the Haskell representation is based on the encoding of the colimit using a coend:

The Haskell library also contains the proof that Kan extension is a functor:
instance Functor (Lan k f) where
fmap g (Lan kcd fc) = Lan (g . kcd) fc
The natural transformation that is part of the definition of the Kan extension can be extracted from the Haskell definition:
eta :: f c -> Lan k f (k c)
eta = Lan id
In Haskell, we don’t have to prove naturality, as it is a consequence of parametricity.
The universality of the Kan extension is witnessed by the following function:
toLan :: Functor g => (forall c. f c -> g (k c)) -> Lan k f d -> g d
toLan gamma (Lan kcd fc) = fmap kcd (gamma fc)
It takes a natural transformation from to  , and produces a natural transformation we called from to .
, and produces a natural transformation we called from to .
This is expressed as a composition of and :
fromLan :: (forall d. Lan k f d -> g d) -> f c -> g (k c)
fromLan alpha = alpha . eta
As an example of equational reasoning, let’s prove that defined by toLan indeed factorizes . In other words, let’s prove that:
fromLan (toLan gamma) = gamma
Let’s plug the definition of toLan into the left hand side:
fromLan (\(Lan kcd fc) -> fmap kcd (gamma fc))
then use the definition of fromLan:
(\(Lan kcd fc) -> fmap kcd (gamma fc)) . eta
Let’s apply this to some arbitrary function g and expand eta:
(\(Lan kcd fc) -> fmap kcd (gamma fc)) (Lan id g)
Beta-reduction gives us:
fmap id (gamma g)
which is indeed equal to the right hand side acting on g:
gamma g
The proof of toLan . fromLan = id is left as an exercise to the reader (hint: you’ll have to use naturality).
Acknowledgments
I’m grateful to Emily Riehl for reviewing the draft of this post and for writing the book from which I borrowed this proof.
La filosofia è scritta in questo grandissimo libro che continuamente ci sta aperto innanzi a gli occhi (io dico l’universo), ma non si può intendere se prima non s’impara a intender la lingua, e conoscer i caratteri, ne’ quali è scritto. Egli è scritto in lingua matematica, e i caratteri son triangoli, cerchi, ed altre figure geometriche, senza i quali mezi è impossibile a intenderne umanamente parola; senza questi è un aggirarsi vanamente per un oscuro laberinto.
― Galileo Galilei, Il Saggiatore (The Assayer)
Joan was quizzical; studied pataphysical science in the home. Late nights all alone with a test tube.
— The Beatles, Maxwell’s Silver Hammer
Unless you’re a member of the Flat Earth Society, I bet you’re pretty confident that the Earth is round. In fact, you’re so confident that you don’t even ask yourself the question why you are so confident. After all, there is overwhelming scientific evidence for the round-Earth hypothesis. There is the old “ships disappearing behind the horizon” proof, there are satellites circling the Earth, there are even photos of the Earth seen from the Moon, the list goes on and on. I picked this particular theory because it seems so obviously true. So if I try to convince you that the Earth is flat, I’ll have to dig very deep into the foundation of your belief systems. Here’s what I’ve found: We believe that the Earth is round not because it’s the truth, but because we are lazy and stingy (or, to give it a more positive spin, efficient and parsimonious). Let me explain…
https://upload.wikimedia.org/wikipedia/commons/8/87/Flammarion.jpg
The New Flat Earth Theory
Let’s begin by stressing how useful the flat-Earth model is in everyday life. I use it all the time. When I want to find the nearest ATM or a gas station, I take out my cell phone and look it up on its flat screen. I’m not carrying a special spherical gadget in my pocket. The screen on my phone is not bulging in the slightest when it’s displaying a map of my surroundings. So, at least within the limits of my city, or even the state, flat-Earth theory works just fine, thank you!
I’d like to make parallels with another widely accepted theory, Einstein’s special relativity. We believe that it’s true, but we never use it in everyday life. The vast majority of objects around us move much slower than the speed of light, so traditional Newtonian mechanics works just fine for us. When was the last time you had to reset your watch after driving from one city to another to account for the effects of time dilation?
The point is that every physical theory is only valid within a certain range of parameters. Physicists have always been looking for the Holy Grail of theories — the theory of everything that would be valid for all values of parameters with no exceptions. They haven’t found one yet.
But, obviously, special relativity is better than Newtonian mechanics because it’s more general. You can derive Newtonian mechanics as a low velocity approximation to special relativity. And, sure enough, the flat-Earth theory is an approximation to the round-Earth theory for small distances. Or, equivalently, it’s the limit as the radius of the Earth goes to infinity.
But suppose that we were prohibited (for instance, by a religion or a government) from ever considering the curvature of the Earth. As explorers travel farther and farther, they discover that the “naive” flat-Earth theory gives incorrect answers. Unlike present-day flat-earthers, who are not scientifically sophisticated, they would actually put some effort to refine their calculations to account for the “anomalies.” For instance, they could postulate that, as you get away from the North Pole, which is the center of the flat Earth, something funny keeps happening to measuring rods. They get elongated when positioned along the parallels (the circles centered at the North Pole). The further away you get from the North Pole, the more they elongate, until at a certain distance they become infinite. Which means that the distances (measured using those measuring rods) along the big circles get smaller and smaller until they shrink to zero.

I know this theory sounds weird at first, but so does special and, even more so, general relativity. In special relativity, weird things happen when your speed is close to the speed of light. Time slows down, distances shrink in the direction of flight (but not perpendicular to it!), and masses increase. In general relativity, similar things happen when you get closer to a black hole’s event horizon. In both theories things diverge as you hit the limit — the speed of light, or the event horizon, respectively.
Back to flat Earth — our explorers conquer space. They have to extend their weird geometry to three dimensions. They find out that horizontally positioned measuring rods shrink as you go higher (they un-shrink when you point them vertically). The intrepid explorers also dig into the ground, and probe the depths with seismographs. They find another singularity at a particular depth, where the horizontal dilation of measuring rods reaches infinity (round-Earthers call this the center of the Earth).
This generalized flat-Earth theory actually works. I know that, because I have just described the spherical coordinate system. We use it when we talk about degrees of longitude and latitude. We just never think of measuring distances using spherical coordinates — it’s too much work, and we are lazy. But it’s possible to express the metric tensor in those coordinates. It’s not constant — it varies with position — and it’s not isotropic — distances vary with direction. In fact, because of that, flat Earthers would be better equipped to understand general relativity than we are.
So is the Earth flat or spherical? Actually it’s neither. Both theories are just approximations. In cartesian coordinates, the Earth is the shape of a flattened ellipsoid, but as you increase the resolution, you discover more and more anomalies (we call them mountains, canyons, etc.). In spherical coordinates, the Earth is flat, but again, only approximately. The biggest difference is that the math is harder in spherical coordinates.
Have I confused you enough? On one level, unless you’re an astronaut, your senses tell you that the Earth is flat. On the other level, unless you’re a conspiracy theorist who believes that NASA is involved in a scam of enormous proportions, you believe that the Earth is pretty much spherical. Now I’m telling you that there is a perfectly consistent mathematical model in which the Earth is flat. It’s not a cult, it’s science! So why do you feel that the round Earth theory is closer to the truth?
The Occam’s Razor
The round Earth theory is just simpler. And for some reason we cling to the belief that nature abhors complexity (I know, isn’t it crazy?). We even express this belief as a principle called the Occam’s razor. In a nutshell, it says that:
Among competing hypotheses, the one with the fewest assumptions should be selected.
Notice that this is not a law of nature. It’s not even scientific: there is no way to falsify it. You can argue for the Occam’s razor on the grounds of theology (William of Ockham was a Franciscan friar) or esthetics (we like elegant theories), but ultimately it boils down to pragmatism: A simpler theory is easier to understand and use.

It’s a mistake to think that Occam’s razor tells us anything about the nature of things, whatever that means. It simply describes the limitations of our mind. It’s not nature that abhors complexity — it’s our brains that prefer simplicity.
Unless you believe that physical laws have an independent existence of their own.
The Layered Cake Hypothesis
Scientists since Galileo have a picture of the Universe that consists of three layers. The top layer is nature that we observe and interact with. Below are laws of physics — the mechanisms that drive nature and make it predictable. Still below is mathematics — the language of physics (that’s what Galileo’s quote at the top of this post is about). According to this view, physics and mathematics are the hidden components of the Universe. They are the invisible cogwheels and pulleys whose existence we can only deduce indirectly. According to this view, we discover the laws of physics. We also discover mathematics.
Notice that this is very different from art. We don’t say that Beethoven discovered the Fifth Symphony (although Igor Stravinsky called it “inevitable”) or that Leonardo da Vinci discovered the Mona Lisa. The difference is that, had not Beethoven composed his symphony, nobody would; but if Cardano hadn’t discovered complex numbers, somebody else probably would. In fact there were many cases of the same mathematical idea being discovered independently by more than one person. Does this prove that mathematical ideas exist the same way as, say, the moons of Jupiter?
Physical discoveries have a very different character than mathematical discoveries. Laws of physics are testable against physical reality. We perform experiments in the real world and if the results contradict a theory, we discard the theory. A mathematical theory, on the other hand, can only be tested against itself. We discard a theory when it leads to internal contradictions.
The belief that mathematics is discovered rather than invented has its roots in Platonism. When we say that the Earth is spherical, we are talking about the idea of a sphere. According to Plato, these ideas do exist independently of the observer — in this case, a mathematician who studies them. Most mathematicians are Platonists, whether they admit it or not.
Being able to formulate laws of physics in terms of simple mathematical equations is a thing of beauty and elegance. But you have to realize that history of physics is littered with carcasses of elegant theories. There was a very elegant theory, which postulated that all matter was made of just four elements: fire, air, water, and earth. The firmament was a collection of celestial spheres (spheres are so Platonic). Then the orbits of planets were supposed to be perfect circles — they weren’t. They aren’t even elliptical, if you study them close enough.
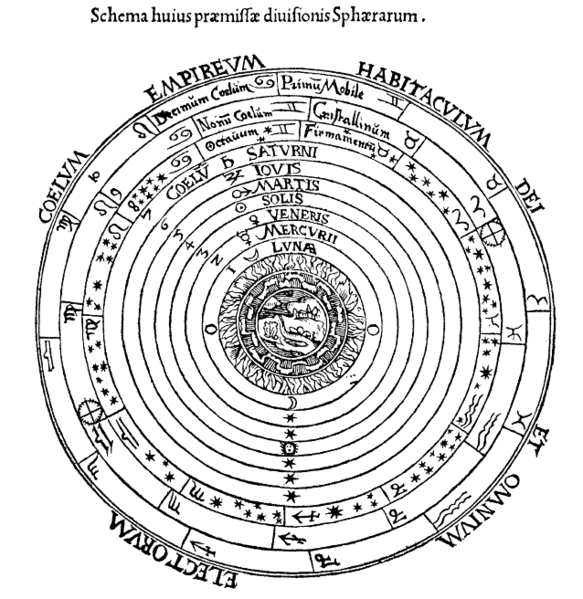
Celestial spheres. An elegant theory, slightly complicated by the need to introduce epicycles to describe the movements of planets
The Impasse
But maybe at the level of elementary particles and quantum fields some of this presumed elegance of the Universe shines through? Well, not really. If the Universe obeyed the Occam’s razor, it would have stopped at two quarks, up and down. Nobody needs the strange and the charmed quarks, not to mention the bottom and the top quarks. The Standard Model of particle physics looks like a kitchen sink filled with dirty dishes. And then there is gravity that resists all attempts at grand unification. Strings were supposed to help but they turned out to be as messy as the rest of it.
Of course the current state of impasse in physics might be temporary. After all we’ve been making tremendous progress up until about the second half of the twentieth century (the most recent major theoretical breakthroughs were the discovery of the Higgs mechanism in 1964 and the proof or renormalizability of the Standard Model in 1971).
On the other hand, it’s possible that we might be reaching the limits of human capacity to understand the Universe. After all, there is no reason to believe that the structure of the Universe is simple enough for the human brain to analyze. There is no guarantee that it can be translated into the language of physics and mathematics.
Is the Universe Knowable?
In fact, if you think about it, our expectation that the Universe is knowable is quite arbitrary. On the one hand you have the vast complex Universe, on the other hand you have slightly evolved monkey brains that have only recently figured out how to use tools and communicate using speech. The idea that these brains could produce and store a model of the Universe is preposterous. Granted, our monkey brains are a product of evolution, and our survival depends on those brains being able to come up with workable models of our environment. These models, however, do not include the microcosm or the macrocosm — just the narrow band of phenomena in between. Our senses can perceive space and time scales within about 8 orders of magnitude. For comparison, the Universe is about 40 orders of magnitude larger than the size of the atomic nucleus (not to mention another 20 orders of magnitude down to Planck length).
The evolution came up with an ingenious scheme to deal with the complexities of our environment. Since it is impossible to store all information about the Universe in the very limited amount of memory at our disposal, and it’s impossible to run the simulation in real time, we have settled for the next best thing: creating simplified partial models that are composable.
The idea is that, in order to predict the trajectory of a spear thrown at a mammoth, it’s enough to roughly estimate the influence of a constant downward pull of gravity and the atmospheric drag on the idealized projectile. It is perfectly safe to ignore a lot of subtle effects: the non-uniformity of the gravitational field, air-density fluctuations, imperfections of the spear, not to mention relativistic effects or quantum corrections.
And this is the key to understanding our strategy: we build a simple model and then calculate corrections to it. The idea is that corrections are small enough as not to destroy the premise of the model.
Celestial Mechanics
A great example of this is celestial mechanics. To the lowest approximation, the planets revolve around the Sun along elliptical orbits. The ellipse is a solution of the one body problem in a central gravitational field of the Sun; or a two body problem, if you also take into account the tiny orbit of the Sun. But planets also interact with each other — in particular the heaviest one, Jupiter, influences the orbits of other planets. We can treat these interactions as corrections to the original solution. The more corrections we add, the better predictions we can make. Astronomers came up with some ingenious numerical methods to make such calculations possible. And yet it’s known that, in the long run, this procedure fails miserably. That’s because even the tiniest of corrections may lead to a complete change of behavior in the far future. This is the property of chaotic systems, our Solar System being just one example of such. You must have heard of the butterfly effect — the Universe is filled with this kind of butterflies.

Ephemerides: Tables showing positions of planets on the firmament.
The Microcosm
Anyone who is not shocked by quantum
theory has not understood a single word.
— Niels Bohr
At the other end of the spectrum we have atoms and elementary particles. We call them particles because, to the lowest approximation, they behave like particles. You might have seen traces made by particles in a bubble chamber.

Elementary particles might, at first sight, exhibit some properties of macroscopic objects. They follow paths through the bubble chamber. A rock thrown in the air also follows a path — so elementary particles can’t be much different from little rocks. This kind of thinking led to the first model of the atom as a miniature planetary system. As it turned out, elementary particles are nothing like little rocks. So maybe they are like waves on a lake? But waves are continuous and particles can be counted by Geiger counters. We would like elementary particles to either behave like particles or like waves but, despite our best efforts, they refuse to nicely fall into one of the categories.
There is a good reason why we favor particle and wave explanations: they are composable. A two-particle system is a composition of two one-particle systems. A complex wave can be decomposed into a superposition of simpler waves. A quantum system is neither. We might try to separate a two-particle system into its individual constituents, but then we have to introduce spooky action at a distance to explain quantum entanglement. A quantum system is an alien entity that does not fit our preconceived notions, and the main characteristic that distinguishes it from classical phenomena is that it’s not composable. If quantum phenomena were composable in some other way, different from particles or waves, we could probably internalize it. But non-composable phenomena are totally alien to our way of thinking. You might think that physicists have some deeper insight into quantum mechanics, but they don’t. Richard Feynman, who was a no-nonsense physicist, famously said, “If you think you understand quantum mechanics, you don’t understand quantum mechanics.” The problem with understanding quantum mechanics is not that it’s too complex. The problem is that our brains can only deal with concepts that are composable.
It’s interesting to notice that by accepting quantum mechanics we gave up on composability on one level in order to decompose something at another level. The periodic table of elements was the big challenge at the beginning of the 20th century. We already knew that earth, water, air, and fire were not enough. We understood that chemical compounds were combinations of atoms; but there were just too many kinds of atoms, and they could be grouped into families that shared similar properties. Atom was supposed to be indivisible (the Greek word ἄτομος [átomos] means indivisible), but we could not explain the periodic table without assuming that there was some underlying structure. And indeed, there is structure there, but the way the nucleus and the electrons compose in order to form an atom is far from trivial. Electrons are not like planets orbiting the nucleus. They form shells and orbitals. We had to wait for quantum mechanics and the Fermi exclusion principle to describe the structure of an atom.
Every time we explain one level of complexity by decomposing it in terms of simpler constituents we seem to trade off some of the simplicity of the composition itself. This happened again in the sixties, when physicists were faced with a confusing zoo of elementary particles. It seemed like there were hundreds of strongly interacting particles, hadrons, and every year was bringing new discoveries. This mess was finally cleaned up by the introduction of quarks. It was possible to categorize all hadrons as composed of just six types of quarks. This simplification didn’t come without a price, though. When we say an atom is composed of the nucleus and electrons, we can prove it by knocking off a few electrons and studying them as independent particles. We can even split the nucleus into protons and neutrons, although the neutrons outside of a nucleus are short lived. But no matter how hard we try, we cannot split a proton into its constituent quarks. In fact we know that quarks cannot exist outside of hadrons. This is called quark- or color-confinement. Quarks are supposed to come in three “colors,” but the only composites we can observe are colorless. We have stretched the idea of composition by accepting the fact that a composite structure can never be decomposed into its constituents.
I’m Slightly Perturbed
How do physicists deal with quantum mechanics? They use mathematics. Richard Feynman came up with ingenious ways to perform calculations in quantum electrodynamics using perturbation theory. The idea of perturbation theory is that you start with the simple approximation and keep adding corrections to it, just like with celestial mechanics. The terms in the expansion can be visualized as Feynman diagrams. For instance, the lowest term in the interaction between two electrons corresponds to a diagram in which the electrons exchange a virtual photon.

This terms gives the classical repulsive force between two charged particles. The first quantum correction to it involves the exchange of two virtual photons. And here’s the kicker: this correction is not only larger than the original term — it’s infinite! So much for small corrections. Yes, there are tricks to shove this infinity under the carpet, but everybody who’s not fooling themselves understands that the so called renormalization is an ugly hack. We don’t understand what the world looks like at very small scales and we try to ignore it using tricks that make mathematicians faint.
Physicists are very pragmatic. As long as there is a recipe for obtaining results that can be compared with the experiment, they are happy with a theory. In this respect, the Standard Model is the most successful theory in the Universe. It’s a unified quantum field theory of electromagnetism, strong, and weak interactions that produces results that are in perfect agreement with all high-energy experiments we were able to perform to this day. Unfortunately, the Standard Model does not give us the understanding of what’s happening. It’s as if physicists were given an alien cell phone and figured out how to use various applications on it but have no idea about the internal workings of the gadget. And that’s even before we try to involve gravity in the model.
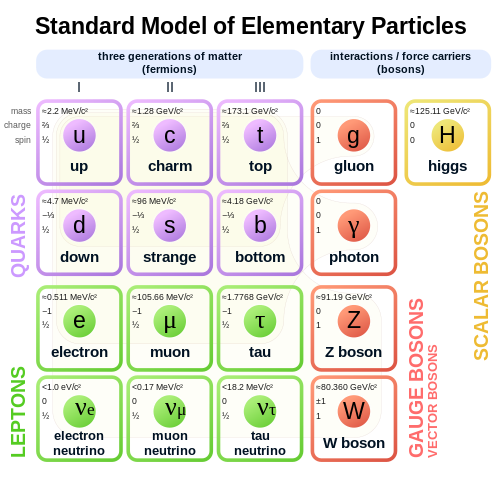
The “periodic table” of elementary particles.
The prevailing wisdom is that these are just little setbacks on the way toward the ultimate theory of everything. We just have to figure out the correct math. It may take us twenty years, or two hundred years, but we’ll get there. The hope that math is the answer led theoretical physicists to study more and more esoteric corners of mathematics and to contribute to its development. One of the most prominent theoretical physicists, Edward Witten, the father of M-theory that unified a number of string theories, was awarded the prestigious Fields Medal for his contribution to mathematics (Nobel prizes are only awarded when a theory is confirmed by experiment which, in the case of string theory, may be a be long way off, if ever).
Math is About Composition
If mathematics is discoverable, then we might indeed be able to find the right combination of math and physics to unlock the secrets of the Universe. That would be extremely lucky, though.
There is one property of all of mathematics that is really striking, and it’s most clearly visible in foundational theories, such as logic, category theory, and lambda calculus. All these theories are about composability. They all describe how to construct more complex things from simpler elements. Logic is about combining simple predicates using conjunctions, disjunctions, and implications. Category theory starts by defining a composition of arrows. It then introduces ways of combining objects using products, coproducts, and exponentials. Typed lambda calculus, the foundation of computer languages, shows us how to define new types using product types, sum types, and functions. In fact it can be shown that constructive logic, cartesian closed categories, and typed lambda calculus are three different formulations of the same theory. This is known as the Curry Howard Lambek isomorphism. We’ve been discovering the same thing over and over again.
It turns out that most mathematical theories have a skeleton that can be captured by category theory. This should not be a surprise considering how the biggest revolutions in mathematics were the result of realization that two or more disciplines were closely related to each other. The latest such breakthrough was the proof of the Fermat’s last theorem. This proof was based on the Taniyama-Shimura conjecture that related the study of elliptic curves to modular forms — two radically different branches of mathematics.
Earlier, geometry was turned upside down when it became obvious that one can define shapes using algebraic equations in cartesian coordinates. This retooling of geometry turned out to be very advantageous, because algebra has better compositional qualities than Euclidean-style geometry.
Finally, any mathematical theory starts with a set of axioms, which are combined using proof systems to produce theorems. Proof systems are compositional which, again, supports the view that mathematics is all about composition. But even there we hit a snag when we tried to decompose the space of all statements into true and false. Gödel has shown that, in any non-trivial theory, we can formulate a statement that can neither be proved to be right or wrong, and thus the Hilbert’s great project of defining one grand mathematical theory fell apart. It’s as if we have discovered that the Lego blocks we were playing with were not part of a giant Lego spaceship.
Where Does Composability Come From?
It’s possible that composability is the fundamental property of the Universe, which would make it comprehensible to us humans, and it would validate our physics and mathematics. Personally, I’m very reluctant to accept this point of view, because it would give intelligent life a special place in the grand scheme of things. It’s as if the laws of the Universe were created in such a way as to be accessible to the brains of the evolved monkeys that we are.
It’s much more likely that mathematics describes the ways our brains are capable of composing simpler things into more complex systems. Anything that we can comprehend using our brains must, by necessity, be decomposable — and there are only so many ways of putting things together. Discovering mathematics means discovering the structure of our brains. Platonic ideals exist only as patterns of connections between neurons.
The amazing scientific progress that humanity has been able to make to this day was possible because there were so many decomposable phenomena available to us. Granted, as we progressed, we had to come up with more elaborate composition schemes. We have discovered differential equations, Hilbert spaces, path integrals, Lie groups, tensor calculus, fiber bundles, etc. With the combination of physics and mathematics we have tapped into a gold vein of composable phenomena. But research takes more and more resources as we progress, and it’s possible that we have reached the bedrock that may be resistant to our tools.
We have to seriously consider the possibility that there is a major incompatibility between the complexity of the Universe and the simplicity of our brains. We are not without recourse, though. We have at our disposal tools that multiply the power of our brains. The first such tool is language, which helps us combine brain powers of large groups of people. The invention of the printing press and then the internet helped us record and gain access to vast stores of information that’s been gathered by the combined forces of teams of researchers over long periods of time. But even though this is quantitative improvement, the processing of this information still relies on composition because it has to be presented to human brains. The fact that work can be divided among members of larger teams is proof of its decomposability. This is also why we sometimes need a genius to make a major breakthrough, when a task cannot be easily decomposed into smaller, easier, subtasks. But even genius has to start somewhere, and the ability to stand on the shoulders of giants is predicated on decomposability.
Can Computers Help?
The role of computers in doing science is steadily increasing. To begin with, once we have a scientific theory, we can write computer programs to perform calculations. Nobody calculates the orbits of planets by hand any more — computers can do it much faster and error free. We are also beginning to use computers to prove mathematical theorems. The four-color problem is an example of a proof that would be impossible without the help of computers. It was decomposable, but the number of special cases was well over a thousand (it was later reduced to 633 — still too many, even for a dedicated team of graduate students).

Every planar map can be colored using only four colors.
Computer programs that are used in theorem proving provide a level of indirection between the mind of a scientist and formal manipulations necessary to prove a theorem. A programmer is still in control, and the problem is decomposable, but the number of components may be much larger, often too large for a human to go over one by one. The combined forces of humans and computers can stretch the limits of composability.
But how can we tackle problems that cannot be decomposed? First, let’s observe that in real life we rarely bother to go through the process of detailed analysis. In fact the survival of our ancestors depended on the ability to react quickly to changing circumstances, to make instantaneous decisions. When you see a tiger, you don’t decompose the image into individual parts, analyze them, and put together a model of a tiger. Image recognition is one of these areas where the analytic approach fails miserably. People tried to write programs that would recognize faces using separate subroutines to detect eyes, noses, lips, ears, etc., and composing them together, but they failed. And yet we instinctively recognize faces of familiar people at a glance.
Neural Networks and the AI
We are now able to teach computers to classify images and recognize faces. We do it not by designing dedicated algorithms; we do it by training artificial neural networks. A neural network doesn’t start with a subsystem for recognizing eyes or noses. It’s possible that, in the process of training, it will develop the notions of lines, shadows, maybe even eyes and noses. But by no means is this necessary. Those abstractions, if they evolve, would be encoded in the connections between its neurons. We might even help the AI develop some general abstractions by tweaking its architecture. It’s common, for instance, to include convolutional layers to pre-process the input. Such a layer can be taught to recognize local features and compress the input to a more manageable size. This is very similar to how our own vision works: the retina in our eye does this kind of pre-processing before sending compressed signals through the optic nerve.

Compression is the key to matching the complexity of the task at hand to the simplicity of the system that is processing it. Just like our sensory organs and brains compress the inputs, so do neural networks. There are two kinds of compression: the kind that doesn’t lose any information, just removing the redundancy in the original signal; and the lossy kind that throws away irrelevant information. The task of deciding what information is irrelevant is in itself a process of discovery. The difference between the Earth and a sphere is the size of the Himalayas, but we ignore it when when we look at the globe. When calculating orbits around the Sun, we shrink all planets to points. That’s compression by elimination of details that we deem less important for the problem we are solving. In science, this kind of compression is called abstraction.
We are still way ahead of neural networks in our capacity to create abstractions. But it’s possible that, at some point, they’ll catch up with us. The problem is: Will we be able to understand machine-generated abstractions? We are already at the limits of understanding human-generated abstractions. You may count yourself a member of a very small club if you understand the statement “monad is a monoid in the category of endofunctors” that is chock full of mathematical abstractions. If neural networks come up with new abstractions/compression schemes, we might not be able to reverse engineer them. Unlike a human scientist, an AI is unlikely to be able to explain to us how it came up with a particular abstraction.
I’m not scared about a future AI trying to eliminate human kind (unless that’s what its design goals are). I’m afraid of the scenario in which we ask the AI a question like, “Can quantum mechanics be unified with gravity?” and it will answer, “Yes, but I can’t explain it to you, because you don’t have the brain capacity to understand the explanation.”
And this is the optimistic scenario. It assumes that such questions can be answered within the decomposition/re-composition framework. That the Universe can be decomposed into particles, waves, fields, strings, branes, and maybe some new abstractions that we haven’t even though about. We would at least get the satisfaction that we were on the right path but that the number of moving parts was simply too large for us to assimilate — just like with the proof of the four-color theorem.
But it’s possible that this reductionist scenario has its limits. That the complexity of the Universe is, at some level, irreducible and cannot be captured by human brains or even the most sophisticated AIs.
There are people who believe that we live in a computer simulation. But if the Universe is irreducible, it would mean that the smallest computer on which such a simulation could be run is the Universe itself, in which case it doesn’t make sense to call it a simulation.
Conclusion
The scientific method has been tremendously successful in explaining the workings of our world. It led to exponential expansion of science and technology that started in the 19th century and continues to this day. We are so used to its successes that we are betting the future of humanity on it. Usually when somebody attacks the scientific method, they are coming from the background of obscurantism. Such attacks are easily rebuffed or dismissed. What I’m arguing is that science is not a property of the Universe, but rather a construct of our limited brains. We have developed some very sophisticated tools to create models of the Universe based on the principle of composition. Mathematics is the study of various ways of composing things and physics is applied composition. There is no guarantee, however, that the Universe is decomposable. Assuming that would be tantamount to postulating that its structure revolves around human brains, just like we used to believe that the Universe revolves around Earth.
You can also watch my talk on this subject.



{kind=link}