One of the tropes of detective movies is the almost miraculous ability to reconstruct an image from a blurry photograph. You just scan the picture, say “enhance!”, and voila, the face of the suspect or the registration number of their car appear on your computer screen.

Computer, enhance!
With constant improvements in deep learning, we might eventually get there. In category theory, though, we do this all the time. We recover lost information. The procedure is based on the basic tenet of category theory: an object is defined by its interactions with the rest of the world. This is the basis of all universal constructions, the Yoneda lemma, Grothendieck fibration, Kan extensions, and practically everything else.
An iconic example is the construction of the left adjoint to a given functor, and that’s what we are going to study here. But first let me explain why I decided to pick this subject, and how it’s related to programming. I wanted to write a blog post about CPS (continuation passing style) and defunctionalization, and I stumbled upon an article in nLab that related defunctionalization to Freyd’s Adjoint Functor Theorem; in particular to the Solution Set Condition. Such an unexpected connection peaked my interest and I decided to dig deeper into it.
Adjunctions
Consider a functor 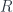 from some category
from some category 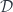 to another category
to another category 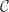 .
.
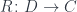
A functor, in general, loses some data, so it’s normally impossible to invert it. It produces a “blurry” image of inside . Its left adjoint is a functor from to
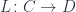
that attempts to reconstruct lost information, to the best of its ability. Often the functor is forgetful, which means that it purposefully forgets some information. Its left adjoint is then called free, because it freely ad-libs the forgotten information.
Of course it’s not always possible, but under certain conditions such left adjoint exists. These conditions are spelled out in the Freyd’s General Adjoint Functor Theorem.
To understand them, we have to talk a little about size issues.
Size issues
A lot of interesting categories are large. It means that there are so many objects in the category that they don’t even form a set. The category of all sets, for instance, is large (there is no set of all sets). It’s also possible that morphisms between two objects don’t form a set.
A category in which objects form a set is called small, and a category in which hom-sets are sets is called locally small.
A lot of complexities in Freyd’s theorem are related to size issues, so it’s important to precisely spell out all the assumptions.
We assume that the source of the functor , the category , is locally small. It must also be small-complete, that is, every small diagram in must have a limit. (A small diagram is a functor from a small category.) We also want the functor to be continuous, that is, to preserve all small limits.
If it weren’t for size issues, this would be enough to guarantee the existence of the left adjoint, and we’ll first sketch the proof for this simplified case. In the general case, there is one more condition, the Solution Set Condition, which we’ll discuss later.
Left adjoint and the comma category
Here’s the problem we are trying to solve. We have a functor that maps objects and morphisms from to . We want to define another functor  that goes in the opposite direction. We’re not looking for the inverse, so we’re not expecting the composition of this functor with to be identity, but we want it to be related to identity by two natural transformations called unit and counit. Their components are, respectively:
that goes in the opposite direction. We’re not looking for the inverse, so we’re not expecting the composition of this functor with to be identity, but we want it to be related to identity by two natural transformations called unit and counit. Their components are, respectively:

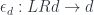
and, as long as they satisfy some additional triangle identities, they will establish the adjunction  .
.
We are going to define point-wise, so let’s pick an object  in and try to propagate it back to . To do that, we have to gather as much information about as possible. We will propagate all this information back to and find an object in that “looks the same.” Think of this as creating a hologram of and shipping it back to .
in and try to propagate it back to . To do that, we have to gather as much information about as possible. We will propagate all this information back to and find an object in that “looks the same.” Think of this as creating a hologram of and shipping it back to .
All information about is encoded in morphisms so, in order to generate our hologram, we’ll gather all morphisms that originate in . These morphisms form a category called the coslice category 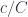 .
.
The objects in are pairs  . In other words, these are all the arrows that emanate from , indexed by their target objects
. In other words, these are all the arrows that emanate from , indexed by their target objects  . But what really defines the structure of this category are morphisms between these arrows. A morphism in from
. But what really defines the structure of this category are morphisms between these arrows. A morphism in from 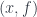 to
to  is a morphism
is a morphism  that makes the following triangle commute:
that makes the following triangle commute:

We now have complete information about encoded in the slice category, but we have no way to propagate it back to . This is because, in general, the image of doesn’t cover the whole of . Even more importantly, not all morphisms in have corresponding morphisms in . We have to scale down our expectations, and define a partial hologram that does not capture all the information about ; only this part which can be back-propagated to using the functor . Such partial hologram is called a comma category 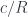 .
.
The objects of are pairs 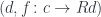 , where
, where  is an object in . In other words, these are all the arrows emanating from whose target is in the image of . Again, the important structure is encoded in the morphisms of . These are the arrows in ,
is an object in . In other words, these are all the arrows emanating from whose target is in the image of . Again, the important structure is encoded in the morphisms of . These are the arrows in ,  that make the following diagram commute in
that make the following diagram commute in

Notice an interesting fact: we can interpret these triangles as commutation conditions in a cone whose apex is and whose base is formed by objects and morphisms in the image of . But not all objects or morphism in the image of are included. Only those morphisms that make the appropriate triangle commute–and these are exactly the morphisms that satisfy the cone condition. So the comma category builds a cone in .

Constructing the limit
We can now take all this information about that’s been encoded in and move it back to . We define a projection functor  that maps
that maps 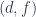 to , thus forgetting the morphism
to , thus forgetting the morphism  . What’s important, though, is that this functor keeps the information encoded in the morphisms of , because these are morphisms in .
. What’s important, though, is that this functor keeps the information encoded in the morphisms of , because these are morphisms in .

The image of 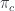 doesn’t necessarily cover the whole of , because not every
doesn’t necessarily cover the whole of , because not every 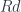 has arrows coming from . Similarly, only some morphisms, the ones that make the appropriate triangle in commute, are picked by . But those objects and morphisms that are in the image of form a diagram in . This diagram is our partial hologram, and we can use it to pick an object in that looks almost exactly like . That object is the limit of this diagram. We pick the limit of this diagram as the definition of
has arrows coming from . Similarly, only some morphisms, the ones that make the appropriate triangle in commute, are picked by . But those objects and morphisms that are in the image of form a diagram in . This diagram is our partial hologram, and we can use it to pick an object in that looks almost exactly like . That object is the limit of this diagram. We pick the limit of this diagram as the definition of  : the left adjoint of acting on .
: the left adjoint of acting on .
Here’s the tricky part: we assumed that was small-complete, so every small diagram has a limit; but the diagram defined by is not necessarily small. Let’s ignore this problem for a moment, and continue sketching the proof. We want to show that the mapping that assigns the limit of to every is left adjoint to .
Let’s see if we can define the unit of the adjunction:
Since we have defined as the limit of the diagram and preserves limits (small limits, really; but we are ignoring size problems for the moment) then 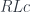 must be the limit of the diagram
must be the limit of the diagram  in . But, as we noted before, the diagram is exactly the base of the cone with the apex that we used to define the comma category . Since is the limit of this diagram, there must be a unique morphism from any other cone to it. In particular there must be a morphism from to it, because is an apex of the cone defined by the comma category. And that’s the morphism we’ll chose as our
in . But, as we noted before, the diagram is exactly the base of the cone with the apex that we used to define the comma category . Since is the limit of this diagram, there must be a unique morphism from any other cone to it. In particular there must be a morphism from to it, because is an apex of the cone defined by the comma category. And that’s the morphism we’ll chose as our  .
.

Incidentally, we can interpret itself as an object of the comma category , namely the one defined by the pair  . In fact, this is the initial object in that category. If you pick any other object, say,
. In fact, this is the initial object in that category. If you pick any other object, say, 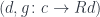 , you can always find a morphism
, you can always find a morphism  , which is just a leg, a projection, in the limiting cone that defines . It is automatically a morphism in because the following triangle commutes:
, which is just a leg, a projection, in the limiting cone that defines . It is automatically a morphism in because the following triangle commutes:

This is the triangle that defines as a morphism of cones, from the top cone with the apex , to the bottom (limiting) cone with the apex . We’ll use this interpretation later, when discussing the full version of the Freyd’s theorem.
We can also define the counit of the adjunction. Its component at is a morphism
First, we repeat our construction starting with 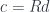 . We define the comma category
. We define the comma category 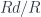 and use
and use 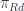 to create the diagram whose limit is
to create the diagram whose limit is  . We pick
. We pick 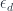 to be a projection in the limiting cone. We are guaranteed that is in the base of the cone, because it’s the image of
to be a projection in the limiting cone. We are guaranteed that is in the base of the cone, because it’s the image of 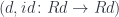 under .
under .
To complete this proof, one should show that the unit and counit are natural transformations and that they satisfy triangle identities.
End of a comma category
An interesting insight into this construction can be gained using the end calculus. In my previous post, I talked about (weighted) colimits as coends, but the same argument can be dualized to limits and ends. For instance, this is our comma category as a category of elements in the coend notation:

The limit of of the projection functor over the comma category can be written in the end notation as
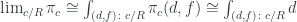
This, in turn, can be rewritten as a weighted limit, with every weighted by the set 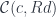 :
:
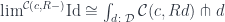
The pitchfork here is the power (cotensor) defined by the equation
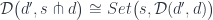
You may think of 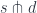 as the product of
as the product of  copies of the object , where is a set. The name power conveys the idea of iterated multiplication. Or, since power is a special case of exponentiation, you may think of as a function object imitating mappings from to .
copies of the object , where is a set. The name power conveys the idea of iterated multiplication. Or, since power is a special case of exponentiation, you may think of as a function object imitating mappings from to .
To continue, if the left adjoint exists, the weighted limit in question can be replaced by

which, using standard calculus of ends (see Appendix), can be shown to be isomorphic to . We end up with:
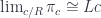
Solution set condition
So what about those pesky size issues? It’s one thing to demand the existence of all small limits, and a completely different thing to demand the existence of large limits (such requirement may narrow down the available categories to preorders). Since the comma category may be too large, maybe we can cut it down to size by carefully picking up a (small) set of objects out of all objects of . We may take some indexing set  and construct a family
and construct a family  of objects of indexed by elements of . It doesn’t have to be one family for all—we may pick a different family for every object for which we are performing our construction.
of objects of indexed by elements of . It doesn’t have to be one family for all—we may pick a different family for every object for which we are performing our construction.
Instead of using the whole comma category , we’ll limit ourselves to a set of arrows 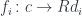 . But in a comma category we also have morphisms between arrows. In fact they are the essential carriers of the structure of the comma category. Let’s have another look at these morphisms.
. But in a comma category we also have morphisms between arrows. In fact they are the essential carriers of the structure of the comma category. Let’s have another look at these morphisms.

This commuting condition can be re-interpreted as a factorization of  through . It so happens that every morphism can be trivially factorized through some by picking
through . It so happens that every morphism can be trivially factorized through some by picking 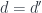 and
and  . But if we restrict the factors to be members of the family
. But if we restrict the factors to be members of the family 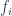 then not every
then not every 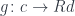 (for arbitrary ) can be automatically factorized. We have to demand it. That gives us the following:
(for arbitrary ) can be automatically factorized. We have to demand it. That gives us the following:
Solution Set Condition: For every object there exists a small set with an -indexed family of objects in and a family of morphisms , such that every morphism can be factored through one of . That is, there exists a morphism  such that
such that


There is a shorthand for this statement: All comma categories admit weakly initial families of objects. We’ll come back to it later.
Freyd’s theorem
We can now formulate:
Freyd’s Adjoint Functor Theorem: If is a locally small and small-complete category, and the functor 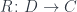 is continuous (small-limit preserving), and it satisfies the solution set condition, then has a left adjoint.
is continuous (small-limit preserving), and it satisfies the solution set condition, then has a left adjoint.
We’ve seen before that the key to defining the point-wise left adjoint was to find the initial object in the comma category . The problem is that this comma category may be large. So the trick is to split the proof into two parts: first defining a weakly initial object, and then constructing the actual initial object using equalizers. A weakly initial object has morphisms to every object in the category but, unlike its strong version, these morphisms don’t have to be unique.
An even weaker notion is that of a weakly initial set of objects. These are objects that among themselves have arrows to every object in the category, but it’s possible that no individual object has all the arrows. The solution set in Freyd’s theorem is such a weakly initial set in the comma category . Since we assumed that is small-complete, we can take a product of these objects and show that it’s weakly initial. The proof then proceeds with the construction of the initial object.
The details of the proof can be found in any category theory text or in nLab.
Next we’ll see the application of these results to the problem of defunctionalization of computer programs.
Appendix
To show that
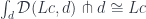
it’s enough to show that the hom-functors from an arbitrary object 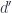 are isomorphic
are isomorphic
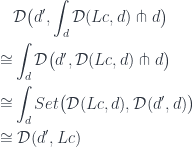
I used the continuity of the hom-functor, the definition of the power (cotensor) and the ninja Yoneda lemma.
It’s funny how similar ideas pop up in different branches of mathematics. Calculus, for instance, is built around metric spaces (or, more generally, Banach spaces) and measures. A limit of a sequence is defined by points getting closer and closer together. An integral is an area under a curve. In category theory, though, we don’t talk about distances or areas (except for Lawvere’s take on metric spaces), and yet we have the abstract notion of a limit, and we use integral notation for ends. The similarities are uncanny.
This blog post was inspired by my trying to understand the idea behind the Freyd’s adjoint functor theorem. It can be expressed as a colimit over a comma category, which is a special case of a Grothendieck fibration. To understand it, though, I had to get a better handle on weighted colimits which, as I learned, were even more general than Kan extensions.
Category of elements as coend
Grothendieck fibration is like splitting a category in two orthogonal directions, the base and the fiber. Fiber may vary from object to object (as in dependent types, which are indeed modeled as fibrations).
The simplest example of a Grothendieck fibration is the category of elements, in which fibers are simply sets. Of course, a set is also a category—a discrete category with no morphisms between elements, except for compulsory identity morphisms. A category of elements is built on top of a category  using a functor
using a functor

Such a functor is traditionally called a copresheaf (this construction works also on presheaves, 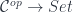 ). Objects in the category of elements are pairs
). Objects in the category of elements are pairs 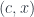 where is an object in , and
where is an object in , and 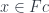 is an element of a set.
is an element of a set.
A morphism from to 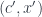 is a morphism
is a morphism 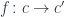 in , such that
in , such that 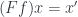 .
.
There is an obvious projection functor that forgets the second component of the pair

(In fact, a general Grothendieck fibration starts with a projection functor.)
You will often see the category of elements written using integral notation. An integral, after all, is a gigantic sum of tiny slices. Similarly, objects of the category of elements form a gigantic sum (disjoint union) of sets 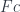 . This is why you’ll see it written as an integral
. This is why you’ll see it written as an integral
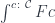
However, this notation conflicts with the one for conical colimits so, following Fosco Loregian, I’ll write the category of elements as
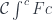
An interesting specialization of a category of elements is a comma category. It’s the category 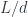 of arrows originating in the image of the functor
of arrows originating in the image of the functor 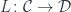 and terminating at a fixed object in
and terminating at a fixed object in 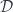 . The objects of are pairs
. The objects of are pairs 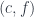 where is an object in and
where is an object in and 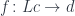 is a morphism in . These morphisms are elements of the hom-set
is a morphism in . These morphisms are elements of the hom-set  , so the comma category is just a category of elements for the functor
, so the comma category is just a category of elements for the functor 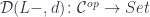
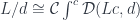
You’ll mostly see integral notation in the context of ends and coends. A coend of a profunctor is like a trace of a matrix: it’s a sum (a coproduct) of diagonal elements. But (co-)end notation may also be used for (co-)limits. Using the trace analogy, if you fill rows of a matrix with copies of the same vector, the trace will be the sum of the components of the vector. Similarly, you can construct a profunctor from a functor by repeating the same functor for every value of the first argument  :
:
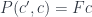
The coend over this profunctor is the colimit of the functor, a colimit being a generalization of the sum. By slight abuse of notation we write it as

This kind of colimit is called conical, as opposed to what we are going to discuss next.
Weighted colimit as coend
A colimit is a universal cocone under a diagram. A diagram is a bunch of objects and morphisms in selected by a functor  from some indexing category
from some indexing category 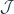 . The legs of a cocone are morphisms that connect the vertices of the diagram to the apex of the cocone.
. The legs of a cocone are morphisms that connect the vertices of the diagram to the apex of the cocone.

For any given indexing object  , we select an element of the hom-set
, we select an element of the hom-set  , as a wire of the cocone. This is a selection of an element of a set (the hom-set) and, as such, can be described by a function from the singleton set
, as a wire of the cocone. This is a selection of an element of a set (the hom-set) and, as such, can be described by a function from the singleton set  . In other words, a wire is a member of
. In other words, a wire is a member of 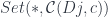 . In fact, we can describe the whole cocone as a natural transformation between two functors, one of them being the constant functor
. In fact, we can describe the whole cocone as a natural transformation between two functors, one of them being the constant functor 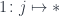 . The set of cocones is then the set of natural transformations:
. The set of cocones is then the set of natural transformations:
)](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BJ%7D%5E%7Bop%7D%2C+Set%5D%281%2C+%5Cmathcal%7BC%7D%28D+-%2C+c%29%29&bg=ffffff&fg=29303b&s=0&c=20201002)
Here, ![[J^{op}, Set]](https://s0.wp.com/latex.php?latex=%5BJ%5E%7Bop%7D%2C+Set%5D&bg=ffffff&fg=29303b&s=0&c=20201002) is the category of presheaves, that is functors from
is the category of presheaves, that is functors from 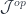 to
to 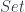 , with natural transformations as morphisms. As a bonus, we get the cocone triangle commuting conditions from naturality.
, with natural transformations as morphisms. As a bonus, we get the cocone triangle commuting conditions from naturality.
Using singleton sets to pick morphisms doesn’t generalize very well to enriched categories. For conical limits, we are building cocones from zero-thickness wires. What we need instead is what Max Kelly calls cylinders obtained by replacing the constant functor  with a more general functor
with a more general functor  . The result is a weighted colimit (or an indexed colimit, as Kelly calls it),
. The result is a weighted colimit (or an indexed colimit, as Kelly calls it), 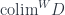 . The set of weighted cocones is defined by natural transformations
. The set of weighted cocones is defined by natural transformations
)](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BJ%7D%5E%7Bop%7D%2C+Set%5D%28W%2C+%5Cmathcal%7BC%7D%28D+-%2C+c%29%29&bg=ffffff&fg=29303b&s=0&c=20201002)
and the weighted colimit is the universal one of these. This definition generalizes nicely to the enriched setting (which I won’t be discussing here).
Universality can be expressed as a natural isomorphism
) \cong \mathcal{C}(\mbox{colim}^W D, c)](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BJ%7D%5E%7Bop%7D%2C+Set%5D%28W%2C+%5Cmathcal%7BC%7D%28D+-%2C+c%29%29++%5Ccong++%5Cmathcal%7BC%7D%28%5Cmbox%7Bcolim%7D%5EW+D%2C+c%29&bg=ffffff&fg=29303b&s=0&c=20201002)
We interpret this formula as a one-to-one correspondence: for every weighted cocone with the apex there is a unique morphism from the colimit to . Naturality conditions guarantee that the appropriate triangles commute.
A weighted colimit can be expressed as a coend (see Appendix 1)

The dot here stands for the tensor product of a set by an object. It’s defined by the formula
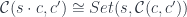
If you think of 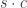 as the sum of copies of the object , then the above asserts that the set of functions from a sum (coproduct) is equivalent to a product of functions, one per element of the set ,
as the sum of copies of the object , then the above asserts that the set of functions from a sum (coproduct) is equivalent to a product of functions, one per element of the set ,

Right adjoint as a colimit
A fibration is like a two-dimensional category. Or, if you’re familiar with bundles, it’s like a fiber bundle, which is locally isomorphic to a cartesian product of two spaces, the base and the fiber. In particular, the category of elements 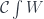 is, roughly speaking, like a bundle whose base is the category , and the fiber is a (-dependent) set
is, roughly speaking, like a bundle whose base is the category , and the fiber is a (-dependent) set 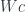 .
.
We also have a projection functor on the category of elements that ignores the component
The coend of this functor is the (conical) colimit
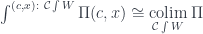
But this functor is constant along the fiber, so we can “integrate over it.” Since fibers depends on , different objects end up weighted differently. The result is a coend over the base category, with objects weighted by sets

Using a more traditional notation, this is the formula that relates a (conical) colimit over the category of elements and a weighted colimit of the identity functor
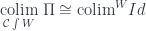
There is a category of elements that will be of special interest to us when discussing adjunctions: the comma category for the functor , in which the weight functor is the hom-functor 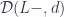
If we plug it into the last formula, we get

If the functor has a right adjoint
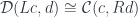
we can rewrite this as

and useing the ninja Yoneda lemma (see Appendix 2) we get a formula for the right adjoint in terms of a colimit of a comma category
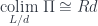
Incidentally, this is the left Kan extension of the identity functor along . (In fact, it can be used to define the right adjoint as long as it preserves the functor .)
We’ll come back to this formula when discussing the Freyd’s adjoint functor theorem.
Appendix 1
I’m going to prove the following identity using some of the standard tricks of coend calculus
To show that two objects are isomorphic, it’s enough to show that their hom-sets to any object are isomorphic (this follows from the Yoneda lemma)
![\begin{aligned} \mathcal{C}(\mbox{colim}^W D, c') & \cong [\mathcal{J}^{op}, Set]\big(W-, \mathcal{C}(D -, c')\big) \\ &\cong \int_j Set \big(W j, \mathcal{C}(D j, c')\big) \\ &\cong \int_j \mathcal{C}(W j \cdot D j, c') \\ &\cong \mathcal{C}(\int^j W j \cdot D j, c') \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++%5Cmathcal%7BC%7D%28%5Cmbox%7Bcolim%7D%5EW+D%2C+c%27%29+%26+%5Ccong+%5B%5Cmathcal%7BJ%7D%5E%7Bop%7D%2C+Set%5D%5Cbig%28W-%2C+%5Cmathcal%7BC%7D%28D+-%2C+c%27%29%5Cbig%29+%5C%5C+++%26%5Ccong+%5Cint_j+Set+%5Cbig%28W+j%2C+%5Cmathcal%7BC%7D%28D+j%2C+c%27%29%5Cbig%29+%5C%5C+++%26%5Ccong+%5Cint_j+%5Cmathcal%7BC%7D%28W+j+%5Ccdot+D+j%2C+c%27%29+%5C%5C+++%26%5Ccong+%5Cmathcal%7BC%7D%28%5Cint%5Ej+W+j+%5Ccdot+D+j%2C+c%27%29++%5Cend%7Baligned%7D+++&bg=ffffff&fg=29303b&s=0&c=20201002)
I first used the universal property of the colimit, then rewrote the set of natural transformations as an end, used the definition of the tensor product of a set and an object, and replaced an end of a hom-set by a hom-set of a coend (continuity of the hom-set functor).
Appendix 2
The proof of

follows the same pattern
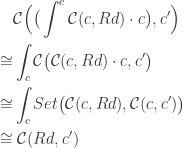
I used the fact that a hom-set from a coend is isomorphic to an end of a hom-set (continuity of hom-sets). Then I applied the definition of a tensor. Finally, I used the Yoneda lemma for contravariant functors, in which the set of natural transformations is written as an end.
![[ \mathcal{C}^{op}, Set]\big(\mathcal{C}(-, x), H \big) \cong \int_c Set \big( \mathcal{C}(c, x), H c \big) \cong H x](https://s0.wp.com/latex.php?latex=%5B+%5Cmathcal%7BC%7D%5E%7Bop%7D%2C+Set%5D%5Cbig%28%5Cmathcal%7BC%7D%28-%2C+x%29%2C+H+%5Cbig%29+%5Ccong+%5Cint_c+Set+%5Cbig%28+%5Cmathcal%7BC%7D%28c%2C+x%29%2C+H+c+%5Cbig%29+%5Ccong+H+x&bg=ffffff&fg=29303b&s=0&c=20201002)









