Previously we were exploring universal constructions for products, coproducts, and exponentials. In particular, we were able to prove the distributive law:

The power of this law is that it relates the mapping-in universal construction (product on the left) with the mapping-out one (coproduct on the right). If you take into account that products and coproducts are just special cases of limits and colimits, you may ask a more general question: under what conditions limits commute with colimits. In a cartesian closed category a product of sums is not equal to the sum of products:
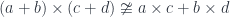
So, in general, products don’t commute with coproducts. But if you replace coproducts with a special kind of colimits, then it can be shown that:
Theorem.
In 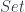 , filtered colimits commute with finite limits.
, filtered colimits commute with finite limits.
In this post I’ll try to explain these terms and provide some intuition why it works and how filtered colimits are related to the more traditional notion of limits that we know from calculus.
Limits
Let’s start with limits. They are like products, except that, instead of just two objects at the bottom, you have any number of objects plus a bunch of morphisms between them. That’s called a diagram. Then you have an apex with arrows going down to all the objects in the diagram; and you get what is called a cone. If you have morphisms in your diagram, they form triangles. These triangles must commute. For instance, in Fig 1, we have:

Fig. 1. A cone
This means that not all projections are independent–that you may obtain one projection from another by post-composing it with a morphism from the diagram. In Fig 1, for instance, you may extract a value of  either directly using
either directly using  or by applying
or by applying  to the result of
to the result of  .
.
A limit is defined as the universal cone with the apex  . It means that, if you have any other cone with some apex , built over the same diagram, there is a unique morphism
. It means that, if you have any other cone with some apex , built over the same diagram, there is a unique morphism  from to that makes all the triangles commute. For instance, in Fig 2, one of the commuting conditions is:
from to that makes all the triangles commute. For instance, in Fig 2, one of the commuting conditions is:

and so on. We’ve seen similar commuting conditions in the definition of the product.

Fig. 2. A universal cone
If you think of in this example as a data structure, you would implement it as a product of  ,
,  , and
, and  , together with two functions:
, together with two functions:


But because of the commuting conditions, the three values stored in cannot be independent. If you pick a value for , then the values for and are uniquely determined.
A limit, just like a product, is defined by a mapping-in property. If you want to define a morphism from some to , you need to provide three morphisms 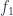 ,
,  , and
, and  . However, unlike in the case of a product, these morphisms must satisfy some commuting conditions. Here, must be equal to
. However, unlike in the case of a product, these morphisms must satisfy some commuting conditions. Here, must be equal to  and
and 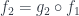 . So, really, you only need to define , and that uniquely determines . This is why the cones in Fig 2 can be simplified, as shown in Fig 3.
. So, really, you only need to define , and that uniquely determines . This is why the cones in Fig 2 can be simplified, as shown in Fig 3.

Fig. 3. A simplified universal cone
Notice that the diagram essentially forms a subcategory inside the category 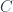 , even if we don’t explicitly draw all the identity morphisms or all the compositions. This is because triangles built by composing commuting triangles are again commuting. It therefore makes sense to define a diagram as a functor
, even if we don’t explicitly draw all the identity morphisms or all the compositions. This is because triangles built by composing commuting triangles are again commuting. It therefore makes sense to define a diagram as a functor  from an (often much smaller) index category
from an (often much smaller) index category  to . In our case it would be a category with just three objects,
to . In our case it would be a category with just three objects,  ,
,  ,
,  , and two non-identity morphisms. (The diagram category for the product is even simpler: just two objects, no non-trivial morphisms.)
, and two non-identity morphisms. (The diagram category for the product is even simpler: just two objects, no non-trivial morphisms.)
The properties of the diagram category determine the nature of cones and the nature of the limits. For instance, functors from a finite category will produce finite limits.

Fig. 4. Diagram category
The diagram category in our example has a very peculiar property: it has a cone for every pair of objects (it’s a cone inside , not to be confused with the cone in ). For instance, the pair , is part of the cone with the apex . This is also the apex for the (somewhat degenerate) cone based on and (with or without the connecting morphism). A category in which there is a cone for every finite subdiagram is called cofiltered. Limits defined by functors from cofiltered categories are called cofiltered limits.
The intuition is that cofiltered categories exhibit some kind of ordering. You may think of as a lower bound of and . Following these bounds, you might eventually get to some kind of roots–here it’s the object –and these roots will dictate the behavior of cones and the behavior of limits. Things get really interesting when the diagram category is infinite, because then there is no guarantee that you’ll ever reach a root. There is, for instance, no smallest (negative) integer, even though integers are ordered. You can begin to see parallels with traditional limits, like:

That’s where these ideas originally came from.
Limits in the category of sets have a particularly simple interpretation. In , we can use functions from the terminal object–the singleton set–to pick individual set elements.

Fig. 5. Elements of the limit
For every selection in Fig 5. of  ,
, 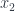 ,
,  there is a unique
there is a unique  that picks an element in . But a selection of , , is nothing but a cone with the apex
that picks an element in . But a selection of , , is nothing but a cone with the apex  . So there is a one-to-one correspondence between elements of and such cones. In other words, is a set of apex-1 cones.
. So there is a one-to-one correspondence between elements of and such cones. In other words, is a set of apex-1 cones.
Colimits
Colimits are dual to limits–you get them by inverting all the arrows. So, instead of projections, you get injections, and the universal condition defines a mapping out of a colimit (see Fig 6).

Fig. 6. A universal cocone
If you look at the colimit as a data structure, it is similar to a coproduct, except that not all the injections are independent. In the example in Fig 6,  and
and 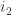 are determined by pre-composing
are determined by pre-composing 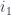 with
with 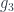 and
and  , respectively. It’s not clear how to implement a colimit in Haskell, so here’s a pseudo-Haskell attempt using imaginary dependent-type syntax:
, respectively. It’s not clear how to implement a colimit in Haskell, so here’s a pseudo-Haskell attempt using imaginary dependent-type syntax:
data Colim a1 a2 a3 (g2 :: a2 -> a1) (g3 :: a3 -> a1) =
= A1 a1 | A2 a2 | A3 a3
To deconstruct this colimit, you only need to provide one function  .
.
h :: (a1 -> c) -> Colim a1 a2 a3 g2 g3 -> c
h f1 (A1 a1) = f1 a1
h f1 (A2 a2) = f1 (g2 a2)
h f1 (A3 a3) = f1 (g3 a3)
Granted, in a lazy language like Haskell, this would be an overkill way to store essentially just one value.
A colimit in the category of sets simplifies to a disjoint union of sets, in which some elements are identified. Suppose that the colimit  is defined by some diagram category and a functor
is defined by some diagram category and a functor  . Each object
. Each object 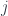 in produces a set
in produces a set  .
.

Fig. 7. Colimit in Set. On the left, the diagram category .
The disjoint union of all these sets is a set whose elements are the pairs  where
where 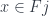 . (Notice that the sets may overlap, but each element from the overlap will be counted as many times as the number of sets it belongs to.) Coproduct injections are then functions that take an element and map it into an element
. (Notice that the sets may overlap, but each element from the overlap will be counted as many times as the number of sets it belongs to.) Coproduct injections are then functions that take an element and map it into an element  . But that doesn’t take into account the presence of morphisms in the diagram. These morphisms are mapped to functions between corresponding sets. For instance, in Fig 7, we can take an element
. But that doesn’t take into account the presence of morphisms in the diagram. These morphisms are mapped to functions between corresponding sets. For instance, in Fig 7, we can take an element 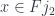 . It is injected, using , as an element
. It is injected, using , as an element  . But there is another path from
. But there is another path from  that uses
that uses  followed by . That produces
followed by . That produces  . If the triangle is to commute, these two must be equal. So in the actual colimit, they must be identified. In general, any two elements of the disjoint union that satisfy this relation:
. If the triangle is to commute, these two must be equal. So in the actual colimit, they must be identified. In general, any two elements of the disjoint union that satisfy this relation:

must be identified. This is not an equivalence relation, but it can be extended to one (by first symmetrizing it, and then making it transitive again). A colimit is then a quotient of the disjoint union by this equivalence.
As before, I chose this example to illustrate a special type of a diagram. This is a diagram that can be obtained using a functor from a filtered category. A filtered category has this property that for any finite subdiagram, there is a cocone under it. Here, for instance, the subdiagram formed by and has a cocone with the apex . Again, you may think of as a kind of upper bound of and . If the filtered category is finite, following upper bounds will eventually lead you to some roots. And in Set, the equivalence relation will allow you shift all the elements down to those roots. But in an infinite case (think natural numbers) there may be no largest element–no root. And that brings filtered colimits closer to the intuition we have for limits in calculus. In fact, all the interesting filtered colimits are based on infinite diagrams.
Commuting Limits and Colimits
What does it mean for a limit to commute with a colimit? A single colimit is generated by a functor from some index category 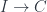 . What we need is a bunch of such colimits so that we can take a limit over those. Therefore we need a bunch of functors . Moreover, those colimits have to form a diagram. So we need another index category to parameterize those functors. Altogether, we need a functor of two arguments:
. What we need is a bunch of such colimits so that we can take a limit over those. Therefore we need a bunch of functors . Moreover, those colimits have to form a diagram. So we need another index category to parameterize those functors. Altogether, we need a functor of two arguments:
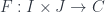
It follows that, for any given in we have a functor  . We can take a colimit of that. Then we gather those colimits into a diagram whose shape is defined by , and then take its limit. We get:
. We can take a colimit of that. Then we gather those colimits into a diagram whose shape is defined by , and then take its limit. We get:
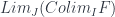
Alternatively, when we fix some  in
in  , we get a functor
, we get a functor  . We can take a limit of that. Then we can gather all those limits and form a diagram whose shape is defined by . Finally we can take a colimit of that:
. We can take a limit of that. Then we can gather all those limits and form a diagram whose shape is defined by . Finally we can take a colimit of that:

It’s not difficult to construct the mapping:
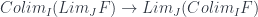
using the universal property, since the colimit has the mapping-out property. It’s the other way around that’s tricky. But it always works in the special case when is filtered, is finite, and is .
Here’s the sketch of this amazing proof, which you can find in Saunders Mac Lane’s Categories for the Working Mathematician.
Since the target of the functor is Set, it might help to visualize its image as a rectangular array of sets. A fixed picks up a row of such sets, whereas a fixed picks up a column. Because we are dealing with sets, we can try to define the mapping:

pointwise. Let’s pick an element of the limit on the left. As we’ve established earlier, a limit in Set is a set of apex-1 cones. So let’s pick one such cone. It’s just a selection of elements from a bunch of colimits.
As we’ve seen before, a colimit in Set is a discriminated union with some identifications. So our apex-1 cone will pick a set of representatives, one per colimit, say  . Any time there is a morphism
. Any time there is a morphism  , we can replace one representative with another
, we can replace one representative with another  . The intuition is that we can slide the representatives horizontally within each row along morphisms.
. The intuition is that we can slide the representatives horizontally within each row along morphisms.
If is a filtered category, then for any finite number of objects  , we can always find a common root (it will be the apex of a cocone formed by in ). So we can slide all the representatives to a single column. In other words, our cone can be brought to a set of representatives
, we can always find a common root (it will be the apex of a cocone formed by in ). So we can slide all the representatives to a single column. In other words, our cone can be brought to a set of representatives  , with a common .
, with a common .

Fig. 9. A single cone after shifting representatives from all colimits to a common column
But that’s just a cone over . It’s an element of  . And we can inject it into a colimit over to get an element of . We have thus defined our mapping.
. And we can inject it into a colimit over to get an element of . We have thus defined our mapping.
Conclusion
If you didn’t get the proof the first time, don’t get discouraged. Take a break, sleep over it, and then read it slowly again. Make sure you have internalized all the definitions. Draw your own pictures. The two major tricks are: (1) visualizing an element of a limit as a cone originating from the singleton set, and (2) the idea of sliding the elements of multiple colimits to a common column.
The importance of this theorem is that it tells you when and how you can define mappings out of limits. For instance, how to define functions from a product or from an end.
Acknowledgment
I’m grateful to Derek Elkins for correcting mistakes in the original version of this post.
As functional programmers we are interested in functions. Category theorists are similarly interested in morphisms. There is a slight difference in approach, though. A programmer must implement a function, whereas a mathematician is often satisfied with the proof of existence of a morphism (unless said mathematician is a constructivist). Category theory if full of such proofs. It turns out that many of these proofs can be converted to code, often resulting in quite unexpected encodings.
A lot of objects in category theory are defined using universal constructions and universality is used all over the place to show the existence (as a rule: unique, up to unique isomorphism) of morphisms between objects.
There are two major types of universal constructions: the ones asserting the mapping-in property, and the ones asserting the mapping-out property. For instance, the product has the mapping-in property.
Product
Recall that a product of two objects  and
and  is an object
is an object  together with two projections:
together with two projections:
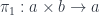
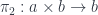
This object must satisfy the universal property: for any other object with a pair of morphisms:


there exists a unique morphism  such that:
such that:
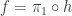

In other words, the two triangles in Fig 1 commute.

Fig. 1. Universality of the product
This universal property can be used any time you need to find a morphism that’s mapping into the product, and it can actually produce code.
For instance, let’s say you want to find a morphism from the terminal object to . All you need is to define two morphisms  and
and 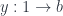 . This is not always possible, but if it is, you are guaranteed the existence of a morphism
. This is not always possible, but if it is, you are guaranteed the existence of a morphism  (Fig 2).
(Fig 2).

Fig. 2. Global element of a product
Morphisms from the terminal object are called global elements, so we have just shown that, as long as and have global elements, say  and
and 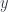 , their product has a global element too. Moreover the projection of this global element is the same as , and
, their product has a global element too. Moreover the projection of this global element is the same as , and 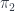 is the same as . In other words, an element of a product is a pair of elements. But you probably knew that.
is the same as . In other words, an element of a product is a pair of elements. But you probably knew that.
The universal construction of the product is implemented as an operator in Haskell:
(&&&) :: (c->a) -> (c->b) -> (c -> (a, b))
We can also go the other way: given a mapping-in , we can always extract a pair of morphisms:
This bijection between and a pair of morphisms  is in fact an adjunction.
is in fact an adjunction.
You might think this kind of reasoning is very different from what programmers do, but it’s not. Here’s one possible definition of a product in Haskell (besides the built-in one, (,)):
data Product a b = MkProduct { fst :: a
, snd :: b }
It is in one-to-one correspondence with what I’ve just explained. The two functions fst and snd are and , and MkProduct corresponds to our . The categorical definition is just a different, much more general, way of saying the same thing.
Here’s another application of universality: Show that product is functorial. Suppose that you have a pair of morphisms:


and you want to lift them to a morphism:

Since we are dealing with products, we should use the mapping-in property. So we draw the universality diagram for the target  , and put the source at the top. The pair of functions that fits the bill is
, and put the source at the top. The pair of functions that fits the bill is  (Fig 3).
(Fig 3).

Fig. 3. Functoriality of the product
The universal property gives us, uniquely, the , which is usually written simply as  .
.
Exercise for the reader: Show, using universality, that categorical product is symmetric.
Coproduct
The coproduct, being the dual of the product, is defined by the universal mapping-out property, see Fig 4.

Fig. 4. Universality of the coproduct
So if you need a morphism from a coproduct 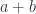 to some , it’s enough to define two morphisms:
to some , it’s enough to define two morphisms:

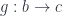
This universal property may also be restated as the isomorphism between pairs of morphisms and morphisms of the type  (so there is, in fact, a corresponding adjunction).
(so there is, in fact, a corresponding adjunction).
This is easily illustrated in Haskell:
h :: Either a b -> c
h (Left a) = f a
h (Right b) = g b
Here Left and Right correspond to the two injections and . There is a convenient function in Haskell that encapsulates this universal construction:
either :: (a->c) -> (b->c) -> (Either a b -> c)
Exercise for the reader: Show that coproduct is functorial.
So next time you ask yourself, what can I do with a universal construction? the answer is: use it to define a morphism, either mapping in or mapping out of your construct. Why is it useful? Because it decomposes a problem into smaller problems. In the examples above, the problem of constructing one morphism was nicely decomposed into defining  and separately.
and separately.
The flip side of this is that there is no simple way of defining a mapping out of a product or a mapping into a coproduct.
Distributive Law
For instance, you might wonder if the familiar distributive law:
holds in an arbitrary category that defines products and coproducts (so called bicartesian category). You can immediately see that defining a morphism from right to left is easy, because it involves the mapping out of a coproduct. All we need is to define a pair of morphisms leading to the common target (Fig 5):



Fig. 5. Right to left proof
The trick is to take advantage of the functoriality of the product, which we have already established, and use it to implement and as:

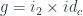
But if you try to construct a proof in the other direction, from left to right, you’re stuck, because it would require the mapping out of a product. So the distributive property does not hold in general.
“Wait a moment!” I hear you say, “I can easily implement it in Haskell.”
f :: (Either a b, c) -> Either (a, c) (b, c)
f (Left a, c) = Left (a, c)
f (Right b, c) = Right (b, c)
Exponential
That’s correct, but Haskell does a little cheating behind the scenes. You can see it clearly when you convert this code to point free notation (I’ll explain later how I figured it out):
f = uncurry (either (curry Left) (curry Right))
I want to direct your attention to the use of curry and uncurry. Currying is the application of another universal construction, namely that of the exponential object 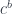 , representing the function type
, representing the function type b -> c. This is exactly the construction that provides the missing mapping out of a product, (a, b) -> c. Here we go:
uncurry :: (c -> (a -> b)) -> ((c, a) -> b)
Categorically, we have the bijection between morphisms (again, a sign of an adjunction):


Universality tells us that for every and there is a unique in Fig 6 (and vice versa). The arrow  is the lifting of the pair
is the lifting of the pair 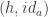 by the product functor (we’ve established the functoriality of the product earlier).
by the product functor (we’ve established the functoriality of the product earlier).

Fig. 6. Universality of the exponential
Not every category has exponentials–the ones that do are called cartesian closed (cartesian, because they must also have products).
So how does the fact that we have exponentials in Haskell help us here? We are trying to define a mapping out of a product:

Here’s where the exponential saves the day. This mapping exists if we can define another mapping:

see Fig 7.

Fig. 7. Uncurrying
This morphism, in turn, is easy to define, because it involves a mapping out of a sum. We just need a pair of morphisms:


We can define the first morphism using the universal property of the exponential, picking the injection :

Fig. 8. Defining 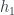
This translates to Haskell as h1 = curry Left. Similarly for  we get
we get curry Right.
We can now combine all these diagrams into a single point-free definition, and that’s exactly how I came up with the original code:
f = uncurry (either (curry Left) (curry Right))
Notice that curry is used to get from to , and uncurry from to in the original diagram.
Products and coproducts are examples of more general constructions called limits and colimits. Importantly, the universal property of limits can be used to define the mapping-in morphisms, whereas the universal property of colimits allows us to define the mapping-out morphisms. I’ll talk more about it in the upcoming post.

















