I am sometimes asked by C++ programmers to give an example of a problem that can’t be solved without monads. This is the wrong kind of question — it’s like asking if there is a problem that can’t be solved without for loops. Obviously, if your language supports a goto, you can live without for loops. What monads (and for loops) can do for you is to help you structure your code. The use of loops and if statements lets you convert spaghetti code into structured code. Similarly, the use of monads lets you convert imperative code into declarative code. These are the kind of transformations that make code easier to write, understand, maintain, and generalize.
So here’s a problem that you may get as an interview question. It’s a small problem, so the advantages of various approaches might not be immediately obvious, especially if you’ve been trained all your life in imperative programming, and you are seeing monads for the first time.
You’re supposed write a program to solve this puzzle:
s e n d + m o r e --------- m o n e y
Each letter correspond to a different digit between 0 and 9. Before you continue reading this post, try to think about how you would approach this problem.
The Analysis
It never hurts to impress your interviewer with your general knowledge by correctly classifying the problem. This one belongs to the class of “constraint satisfaction problems.” The obvious constraint is that the numbers obtained by substituting letters with digits have to add up correctly. There are also some less obvious constraints, namely the numbers should not start with zero.
If you were to solve this problem using pencil and paper, you would probably come up with lots of heuristics. For instance, you would deduce that m must stand for 1 because that’s the largest possible carry from the addition of two digits (even if there is a carry from the previous column). Then you’d figure out that s must be either 8 or 9 to produce this carry, and so on. Given enough time, you could probably write an expert system with a large set of rules that could solve this and similar problems. (Mentioning an expert system could earn you extra points with the interviewer.)
However, the small size of the problem suggests that a simple brute force approach is probably best. The interviewer might ask you to estimate the number of possible substitutions, which is 10!/(10 – 8)! or roughly 2 million. That’s not a lot. So, really, the solution boils down to generating all those substitutions and testing the constraints for each.
The Straightforward Solution
The mind of an imperative programmer immediately sees the solution as a set of 8 nested loops (there are 8 unique letters in the problem: s, e, n, d, m, o, r, y). Something like this:
for (int s = 0; s < 10; ++s) for (int e = 0; e < 10; ++e) for (int n = 0; n < 10; ++n) for (int d = 0; d < 10; ++d) ...
and so on, until y. But then there is the condition that the digits have to be different, so you have to insert a bunch of tests like:
e != s n != s && n != e d != s && d != e && d != n
and so on, the last one involving 7 inequalities… Effectively you have replaced the uniqueness condition with 28 new constraints.
This would probably get you through the interview at Microsoft, Google, or Facebook, but really, can’t you do better than that?
The Smart Solution
Before I proceed, I should mention that what follows is almost a direct translation of a Haskell program from the blog post by Justin Le. I strongly encourage everybody to learn some Haskell, but in the meanwhile I’ll be happy to serve as your translator.
The problem with our naive solution is the 28 additional constraints. Well, I guess one could live with that — except that this is just a tiny example of a whole range of constraint satisfaction problems, and it makes sense to figure out a more general approach.
The problem can actually be formulated as a superposition of two separate concerns. One deals with the depth and the other with the breadth of the search for solutions.
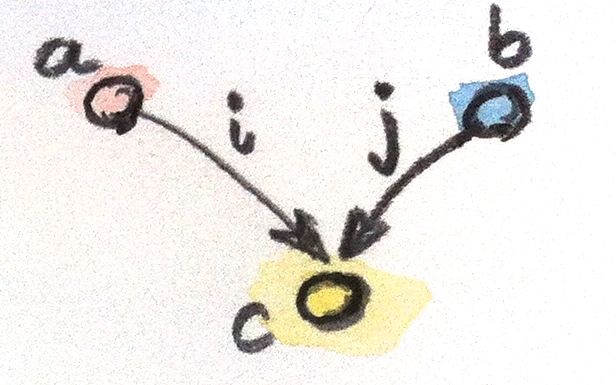
Let me touch on the depth issue first. Let’s consider the problem of creating just one substitution of letters with numbers. This could be described as picking 8 digits from a list of 0, 1, …9, one at a time. Once a digit is picked, it’s no longer in the list. We don’t want to hard code the list, so we’ll make it a parameter to our algorithm. Notice that this approach works even if the list contains duplicates, or if the list elements are not easily comparable for equality (for instance, if they are futures). We’ll discuss the list-picking part of the problem in more detail later.
Now let’s talk about breadth: we have to repeat the above process for all possible picks. This is what the 8 nested loops were doing. Except that now we are in trouble because each individual pick is destructive. It removes items from the list — it mutates the list. This is a well known problem when searching through solution spaces, and the standard remedy is called backtracking. Once you have processed a particular candidate, you put the elements back in the list, and try the next one. Which means that you have to keep track of your state, either implicitly on your function’s stack, or in a separate explicit data structure.
Wait a moment! Weren’t we supposed to talk about functional programming? So what’s all this talk about mutation and state? Well, who said you can’t have state in functional programming? Functional programmers have been using the state monad since time immemorial. And mutation is not an issue if you’re using persistent data structures. So fasten your seat belts and make sure your folding trays are in the upright position.
The List Monad
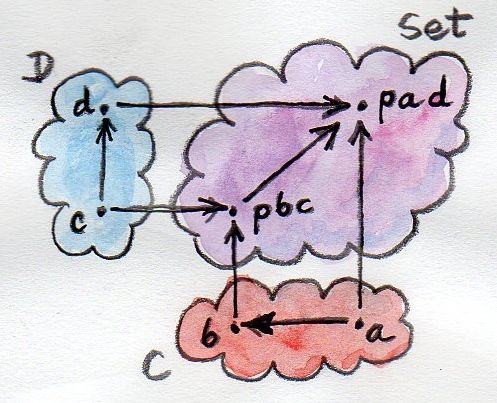
We’ll start with a small refresher in quantum mechanics. As you may remember from school, quantum processes are non-deterministic. You may repeat the same experiment many times and every time get a different result. There is a very interesting view of quantum mechanics called the many-worlds interpretation, in which every experiment gives rise to multiple alternate histories. So if the spin of an electron may be measured as either up or down, there will be one universe in which it’s up, and one in which it’s down.
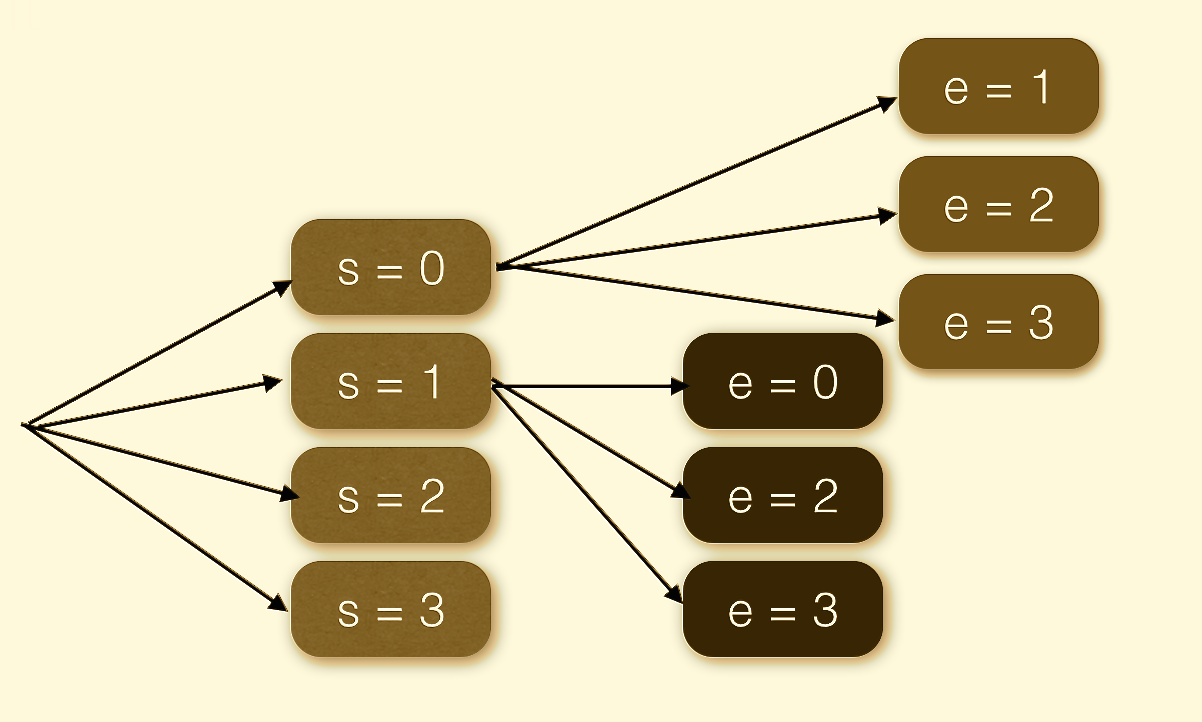
We’ll use the same approach to solving our puzzle. We’ll create an alternate universe for each digit substitution for a given letter. So we’ll start with 10 universes for the letter s; then we’ll split each of them into ten universes for the letter e, and so on. Of course, most of these universes won’t yield the desired result, so we’ll have to destroy them. I know, it seems kind of wasteful, but in functional programming it’s easy come, easy go. The creation of a new universe is relatively cheap. That’s because new universes are not that different from their parent universes, and they can share almost all of their data. That’s the idea behind persistent data structures. These are the immutable data structures that are “mutated” by cloning. A cloned data structure shares most of its implementation with the parent, except for a small delta. We’ll be using persistent lists described in my earlier post.
Once you internalize the many-worlds approach to programming, the implementation is pretty straightforward. First, we need functions that generate new worlds. Since we are cheap, we’ll only generate the parts that are different. So what’s the difference between all the worlds that we get when selecting the substitution for the letter s? Just the number that we assign to s. There are ten worlds corresponding to the ten possible digits (we’ll deal with the constraints like s being different from zero later). So all we need is a function that generates a list of ten digits. These are our ten universes in a nutshell. They share everything else.
Once you are in an alternate universe, you have to continue with your life. In functional programming, the rest of your life is just a function called a continuation. I know it sounds like a horrible simplification. All your actions, emotions, and hopes reduced to just one function. Well, maybe the continuation just describes one aspect of your life, the computational part, and you can still hold on to our emotions.
So what do our lives look like, and what do they produce? The input is the universe we’re in, in particular the one number that was picked for us. But since we live in a quantum universe, the outcome is a multitude of universes. So a continuation takes a number, and produces a list. It doesn’t have to be a list of numbers, just a list of whatever characterizes the differences between alternate universes. In particular, it could be a list of different solutions to our puzzle — triples of numbers corresponding to “send”, “more”, and “money”. (There is actually only one solution, but that’s beside the point.)
And what’s the very essence of this new approach? It’s the binding of the selection of the universes to the continuation. That’s where the action is. This binding, again, can be expressed as a function. It’s a function that takes a list of universes and a continuation that produces a list of universes. It returns an even bigger list of universes. We’ll call this function for_each, and we’ll make it as generic as possible. We won’t assume anything about the type of the universes that are passed in, or the type of the universes that the continuation k produces. We’ll also make the type of the continuation a template parameter and extract the return type from it using auto and decltype:
template<class A, class F>
auto for_each(List<A> lst, F k) -> decltype(k(lst.front()))
{
using B = decltype(k(lst.front()).front());
// This should really be expressed using concepts
static_assert(std::is_convertible<
F, std::function<List<B>(A)>>::value,
"for_each requires a function type List<B>(A)");
List<List<B>> lstLst = fmap(k, lst);
return concatAll(lstLst);
}
The function fmap is similar to std::transform. It applies the continuation k to every element of the list lst. Because k itself produces a list, the result is a list of lists, lstLst. The function concatAll concatenates all those lists into one big list.
Congratulations! You have just seen a monad. This one is called the list monad and it’s used to model non-deterministic processes. The monad is actually defined by two functions. One of them is for_each, and here’s the other one:
template<class A>
List<A> yield(A a)
{
return List<A> (a);
}
It’s a function that returns a singleton list. We use yield when we are done multiplying universes and we just want to return a single value. We use it to create a single-valued continuation. It represents the lonesome boring life, devoid of any choices.
I will later rename these functions to mbind and mreturn, because they are part of any monad, not just the list monad.
The names like for_each or yield have a very imperative ring to them. That’s because, in functional programming, monadic code plays a role similar to imperative code. But neither for_each nor yield are control structures — they are functions. In particular for_each, which sounds and works like a loop, is just a higher order function; and so is fmap, which is used in its implementation. Of course, at some level the code becomes imperative — fmap can either be implemented recursively or using an actual loop — but the top levels are just declarations of functions. Hence, declarative programming.
There is a slight difference between a loop and a function on lists like for_each: for_each takes a whole list as an argument, while a loop might generate individual items — in this case integers — on the fly. This is not a problem in a lazy functional language like Haskell, where a list is evaluated on demand. The same behavior may be implemented in C++ using streams or lazy ranges. I won’t use it here, since the lists we are dealing with are short, but you can read more about it in my earlier post Getting Lazy with C++.
We are not ready yet to implement the solution to our puzzle, but I’d like to give you a glimpse of what it looks like. For now, think of StateL as just a list. See if it starts making sense (I grayed out the usual C++ noise):
StateL<tuple<int, int, int>> solve()
{
StateL<int> sel = &select<int>;
return for_each(sel, [=](int s) {
return for_each(sel, [=](int e) {
return for_each(sel, [=](int n) {
return for_each(sel, [=](int d) {
return for_each(sel, [=](int m) {
return for_each(sel, [=](int o) {
return for_each(sel, [=](int r) {
return for_each(sel, [=](int y) {
return yield_if(s != 0 && m != 0, [=]() {
int send = asNumber(vector{s, e, n, d});
int more = asNumber(vector{m, o, r, e});
int money = asNumber(vector{m, o, n, e, y});
return yield_if(send + more == money, [=]() {
return yield(make_tuple(send, more, money));
});
});
});});});});});});});});
}
The first for_each takes a selection of integers, sel, (never mind how we deal with uniqueness); and a continuation, a lambda, that takes one integer, s, and produces a list of solutions — tuples of three integers. This continuation, in turn, calls for_each with a selection for the next letter, e, and another continuation that returns a list of solutions, and so on.
The innermost continuation is a conditional version of yield called yield_if. It checks a condition and produces a zero- or one-element list of solutions. Internally, it calls another yield_if, which calls the ultimate yield. If that final yield is called (and it might not be, if one of the previous conditions fails), it will produce a solution — a triple of numbers. If there is more than one solution, these singleton lists will get concatenated inside for_each while percolating to the top.
In the second part of this post I will come back to the problem of picking unique numbers and introduce the state monad. You can also have a peek at the code on github.
Challenges
- Implement
for_eachandyieldfor avectorinstead of aList. Use the Standard Librarytransforminstead offmap. - Using the list monad (or your vector monad), write a function that generates all positions on a chessboard as pairs of characters between
'a'and'h'and numbers between 1 and 8. - Implement a version of
for_each(call itrepeat) that takes a continuationkof the typefunction<List<B>()>(notice the void argument). The functionrepeatcallskfor each element of the listlst, but it ignores the element itself.