Previously: Fibrations and Cofibrations.
In topology, we say that two shapes are the same if there is a homeomorphism– an invertible continuous map– between them. Continuity means that nothing is broken and nothing is glued together. This is how we can turn a coffe cup into a torus. A homeomorphism, however, won’t let us shrink a torus to a circle. So if we are only interested in how many holes the shapes have, we have to relax our notion of equivalence.
Let’s go back to the definition of homeomorphism. It is defined as a pair of continuous functions between two topological spaces, 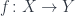




If we want to allow for extreme shrinkage, as with a (solid) torus shrinking down to a circle, we have to relax the identity conditions.
A homotopy equivalence is a pair of continuous functions, but their compositions don’t have to be equal to identities. It’s enough that they are homotopic to identities. In other words, it’s possible to create an animation that transforms one to another.
Take the example of a line 

Indeed, let’s construct the equivalence as a pair of constant functions: 




The composition 




(
![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=29303b&s=0&c=20201002)


When a space is homotopy equivalent to a point, we say that it’s contractible. Thus 
Another way of looking for holes in spaces is by trying to shrink loops. If there is a hole inside a loop, it cannot be continuously shrunk to a point. Imagine a loop going around a circle. There is no way you can “unwind” it without breaking something. In fact, you can have loops that wind n times around a circle. They can’t be homotopied into each other if their winding numbers are different.
In general, paths in a topological space 

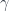





Moreover, two paths can be composed, as long as the endpoint of one coincides with the start point of the other (after performing appropriate reparametrizations).

There is a unit of such composition, a constant path; and every path has its inverse, a path that traces the original but goes in the opposite direction.

It’s easy to see that path composition induces a groupoid structure on the set of equivalence classes of paths. A groupoid is a category in which every morphism (here, path) is invertible. This particular groupoid is called the fundamental groupoid of the topological space
If we pick a base point 

Notice that, as long as there is a path 



So there is essentially a single fundamental group for the whole space, as long as
Going back to our example of a circle, its fundamental group is the group of integers 

Negative integers correspond to loops winding in the opposite direction. If you follow an n-loop with an m-loop, you get an (m+n)-loop. Zero corresponds to loops that can be shrunk to a point.
To tie these two notions of hole-counting together, it can be shown that two spaces that are homotopy equivalent also have the same fundamental groups. This makes sense, since equivalent spaces have the same holes.
Not only that, they also have the same higher homotopy groups (as long as both are path-connected).
We define the n-th homotopy group by replacing simple loops (which are homotopic to a circle, or a 1-dimensional sphere) with n-dimensional spheres. Attempts at shrinking those may detect higher-dimensional holes.
For instance, imagine an Earth-like ball with it’s inner core scooped out. Any 1-loop inside its bulk can be shrunk to a point (it will glide off the core). But a 2-sphere that envelops the core cannot be shrunk.

In fact such a 2-sphere can be wrapped around the core an arbitrary number of times. In math notation, we say:

Corresponding to these higher homotopy groups there is also a higher homotopy groupoid, in which there are invertible paths, surfaces between paths, volumes between surfaces, etc. Taken together, these form an infinity groupoid. It is exactly the inspiration behind the infinity groupoid in homotopy type theory, HoTT.
Spaces that are homotopy equivalent have the same homotopy groups, but the converse is not true. There are spaces that are not homotopy equivalent even though they have the same homotopy groups. This is why a weaker version of equivalence was introduced.
A map between topological spaces is called a weak homotopy equivalence if it induces isomorphisms between all homotopy groups.
There is a subtle difference between strong and weak equivalences. Strong equivalence can be broken by a local anomaly, like in the following example: Take 


The singleton set 
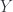
Grothendieck conjectured that the infinity groupoid captures all information about a topological space up to weak homotopy equivalence.
Weak equivalences, together with fibrations and cofibrations, form the foundation of weak factorization systems and Quillen model categories.
Next: (Weak) Factorization Systems.
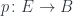 . We’ll call
. We’ll call  a projection from the total set
a projection from the total set 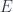 to the base set
to the base set  .
. we’ll assign a fiber, the set of elements of
we’ll assign a fiber, the set of elements of 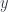 . By abuse of notation, we call such a fiber
. By abuse of notation, we call such a fiber  :
:
 ; for others, it may contain lots elements.
; for others, it may contain lots elements.
![I = [0, 1]](https://s0.wp.com/latex.php?latex=I+%3D+%5B0%2C+1%5D&bg=ffffff&fg=29303b&s=0&c=20201002) to
to 
 that lies above
that lies above  that lies above the starting point of
that lies above the starting point of  .
.

 is then the diagonal arrow that makes both triangles commute:
is then the diagonal arrow that makes both triangles commute:
 is then interpreted as time.
is then interpreted as time.  . Such potentially “fat” paths are called homotopies. In particular, if we replace
. Such potentially “fat” paths are called homotopies. In particular, if we replace  in this commuting square, such that the resulting triangles commute:
in this commuting square, such that the resulting triangles commute:
 of the shape
of the shape  of this shape in
of this shape in  , we can construct a homotopy in
, we can construct a homotopy in 
 into
into  by a surjection
by a surjection  of the exponential
of the exponential  onto
onto  , or the path space of
, or the path space of  is continuous in the compact-open topology of
is continuous in the compact-open topology of 
 .
.  .
.
 that makes the two triangles commute. In other words,
that makes the two triangles commute. In other words, 
 .
. , which induces the embedding of
, which induces the embedding of 

 :
:

 .
.
 and
and 

 and
and  that make the outer square commute, there exist a diagonal morphism
that make the outer square commute, there exist a diagonal morphism  (or, in set notation,
(or, in set notation,  ). It turns out that all surjective functions are its right liftings. In other words, all surjections are right-orthogonal to the simplest non-surjective function.
). It turns out that all surjective functions are its right liftings. In other words, all surjections are right-orthogonal to the simplest non-surjective function. 
 picks an element
picks an element  . Similarly, the diagonal function picks an element
. Similarly, the diagonal function picks an element 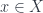 . The commuting triangle tells us that for every
. The commuting triangle tells us that for every  such that
such that  .
.  (or
(or  ).
).
 to a single element
to a single element 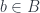 . We could then pick
. We could then pick  and
and  . The diagonal
. The diagonal  or
or  but not both, so we couldn’t make the upper triangle commute.
but not both, so we couldn’t make the upper triangle commute. ; and coverages, which are special kinds of sieves.
; and coverages, which are special kinds of sieves.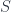 is a subfunctor of another presheaf
is a subfunctor of another presheaf  if it satisfies two conditions.
if it satisfies two conditions.  , we have a set inclusion:
, we have a set inclusion:  ,
, , the function
, the function  is a restriction of the function
is a restriction of the function  . In other words,
. In other words,  and
and  must agree on the subset
must agree on the subset  .
.
 that satisfies the condition that, for any presheaf
that satisfies the condition that, for any presheaf 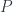 , there is a unique natural transformation
, there is a unique natural transformation  . This will work if every component
. This will work if every component  of this natural transformation is unique, which is true if we choose
of this natural transformation is unique, which is true if we choose  to be the terminal singleton set
to be the terminal singleton set  . Thus the terminal presheaf maps all objects to the terminal set, and all morphisms to the identity on
. Thus the terminal presheaf maps all objects to the terminal set, and all morphisms to the identity on 
 picks a special “True” element in the set
picks a special “True” element in the set  . If the presheaf
. If the presheaf  . The function
. The function  must therefore map the whole subset
must therefore map the whole subset 
 , then both
, then both  . In fact, when defining a subobject, we only care if the embedding of
. In fact, when defining a subobject, we only care if the embedding of  is injective (monomorphic). It’s okay if it permutes the elements of
is injective (monomorphic). It’s okay if it permutes the elements of 

 (not necessarily an element of
(not necessarily an element of 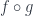 also satisfies the subset-mapping condition:
also satisfies the subset-mapping condition:

 can be made into a presheaf by defining its action on morphisms. The lifting of
can be made into a presheaf by defining its action on morphisms. The lifting of  to a sieve
to a sieve  , defined as a set of arrows
, defined as a set of arrows  , such that
, such that  .
.
 is maximal if and only if
is maximal if and only if  . (Hint: If a sieve is maximal, then it contains identity.)
. (Hint: If a sieve is maximal, then it contains identity.) .
.  is a unique such natural transformation that completes the pullback:
is a unique such natural transformation that completes the pullback: making this diagram into a pullback. Let’s redraw the subfunctor condition for arrows, replacing
making this diagram into a pullback. Let’s redraw the subfunctor condition for arrows, replacing 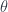 :
:
 . We’ll follow a set of equivalences.
. We’ll follow a set of equivalences. 
 is equivalent to
is equivalent to  . In other words:
. In other words:

 .
.  , acting on
, acting on  is a sieve defined by the following set of arrows:
is a sieve defined by the following set of arrows:
 is a maximal sieve, it must be that
is a maximal sieve, it must be that  .
. . Therefore
. Therefore  that maps objects to sieves, together with the natural transformation
that maps objects to sieves, together with the natural transformation  that picks maximal sieves.
that picks maximal sieves. , etc. The network of “happy” morphisms keeps growing outward. By contrast, the “unhappy” elements of
, etc. The network of “happy” morphisms keeps growing outward. By contrast, the “unhappy” elements of  is the terminal object (here, a singleton set). In principle we should insist that
is the terminal object (here, a singleton set). In principle we should insist that  is to provide an injective function
is to provide an injective function  that embeds
that embeds 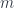 then defines the subset of
then defines the subset of 
 . We do it by means of a universal construction. We postulate that: For every monic
. We do it by means of a universal construction. We postulate that: For every monic  between two arbitrary objects there exist a unique arrow
between two arbitrary objects there exist a unique arrow  ) we first create a set of pairs
) we first create a set of pairs  where
where  and
and  (the only element of the singleton set). But not all
(the only element of the singleton set). But not all  , where
, where  is the element of
is the element of  . This tells us that
. This tells us that 

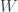 equipped with two natural transformations:
equipped with two natural transformations:



 also a comonad? Can we implement the two natural transformations for it?
also a comonad? Can we implement the two natural transformations for it?



 , again a comonad? We can easily define a counit:
, again a comonad? We can easily define a counit:

 but it should be
but it should be  . To make it a comonad, we have to be able to push
. To make it a comonad, we have to be able to push  through
through  in the middle. We need
in the middle. We need 



 are in general not equal. All we can get from the original comonad laws is that they are only equal when applied to the result of comultiplication:
are in general not equal. All we can get from the original comonad laws is that they are only equal when applied to the result of comultiplication: .
.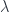 we can complete our definition of comultiplication for a composition of two comonads:
we can complete our definition of comultiplication for a composition of two comonads:
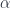 between two virtual objects corresponding to two presheaves
between two virtual objects corresponding to two presheaves  , seen as an arrow
, seen as an arrow  , we get an arrow
, we get an arrow  simply by composition
simply by composition  . Notice that we are thus defining the composition with
. Notice that we are thus defining the composition with  of a natural transformation is a mapping between two arrows.
of a natural transformation is a mapping between two arrows.
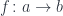 , consider a zigzag path from
, consider a zigzag path from  . The two ways of associating this composition give us
. The two ways of associating this composition give us  .
.
 is a bunch of arrows converging on
is a bunch of arrows converging on  , if we pick a compatible family of
, if we pick a compatible family of  that agrees on all overlaps, then this uniquely determines the element (virtual arrow)
that agrees on all overlaps, then this uniquely determines the element (virtual arrow)  .
.
 and all its open subsets (that is objects that have arrows pointing to
and all its open subsets (that is objects that have arrows pointing to  , even if they are not present in the original cover.
, even if they are not present in the original cover. . Indeed,
. Indeed,  maps all objects either to singletons or to empty sets. In terms of virtual arrows, there is at most one arrow going to
maps all objects either to singletons or to empty sets. In terms of virtual arrows, there is at most one arrow going to  .
.
 is automatically a compatible family. Therefore, if
is automatically a compatible family. Therefore, if  and the set
and the set  .
. and
and  .
.
 is a member of the hom-set
is a member of the hom-set  . Now consider the fact that
. Now consider the fact that  is a presheaf,
is a presheaf,  , and ask the question: Is a cover a “subfunctor” of
, and ask the question: Is a cover a “subfunctor” of  ,
,  is a subset of
is a subset of  and, for each arrow
and, for each arrow  , the function
, the function  is a restriction of
is a restriction of 
 is non-empty for any object
is non-empty for any object  ‘s.
‘s.
 connecting it to some element
connecting it to some element  of the cover. Functoriality requires the (virtual) composition
of the cover. Functoriality requires the (virtual) composition  to exist.
to exist.
 . A coverage assigns a collection of covers to every object, satisfying the sub-coverage conditions described in the previous post. A category with coverage is called a site.
. A coverage assigns a collection of covers to every object, satisfying the sub-coverage conditions described in the previous post. A category with coverage is called a site. , to our category. The set
, to our category. The set  .
.
 . The presheaf lifts it to a function between sets:
. The presheaf lifts it to a function between sets:  (contravariance means that the arrow is reversed). For any
(contravariance means that the arrow is reversed). For any  we can define the composition
we can define the composition 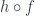 to be
to be  .
.
 that are in the cover of
that are in the cover of 
 . It’s as if the objects
. It’s as if the objects  a matching family, if this new covering respects the existing intersections. If
a matching family, if this new covering respects the existing intersections. If 
 ‘s intersect as covers of
‘s intersect as covers of  and every matching family
and every matching family 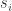 there exists a unique
there exists a unique  that factorizes those
that factorizes those 
 defined over
defined over 

 are also continuous (this follows from the condition that an intersection of open sets is open). Thus going from global to local is easy.
are also continuous (this follows from the condition that an intersection of open sets is open). Thus going from global to local is easy.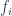 , one per each open set
, one per each open set  defined over
defined over 

 that are members of the individual sets
that are members of the individual sets  . Every such selection forms a giant
. Every such selection forms a giant 






 such that
such that  , for all
, for all 
 and producing a matrix indexed by elements of
and producing a matrix indexed by elements of 

 (the two parallel arrows):
(the two parallel arrows):
 . These restrictions are then required to match when further restricted by
. These restrictions are then required to match when further restricted by 
 and a function
and a function  , there is a function
, there is a function  such that
such that  on
on 
 . We have defined a mapping
. We have defined a mapping  means that
means that  that assigns to each
that assigns to each  .
.
 . The “op” notation means that the directions of arrows are reversed: the functor is “contravariant.”
. The “op” notation means that the directions of arrows are reversed: the functor is “contravariant.” maps to a trivial do-nothing restriction, and that restrictions compose:
maps to a trivial do-nothing restriction, and that restrictions compose:  for
for  .
. to
to  had to be confusingly called co-presheaves.
had to be confusingly called co-presheaves. , with natural transformations as arrows.
, with natural transformations as arrows.