The yearly Advent of Code is always a source of interesting coding challenges. You can often solve them the easy way, or spend days trying to solve them “the right way.” I personally prefer the latter. This year I decided to do some yak shaving with a puzzle that involved looking for patterns in a grid. The pattern was the string XMAS, and it could start at any location and go in any direction whatsoever.
My immediate impulse was to elevate the grid to a comonad. The idea is that a comonad describes a data structure in which every location is a center of some neighborhood, and it lets you apply an algorithm to all neighborhoods in one fell swoop. Common examples of comonads are infinite streams and infinite grids.
Why would anyone use an infinite grid to solve a problem on a finite grid? Imagine you’re walking through a neighborhood. At every step you may hit the boundary of a grid. So a function that retrieves the current state is allowed to fail. You may implement it as returning a Maybe value. So why not pre-fill the infinite grid with Maybe values, padding it with Nothing outside of bounds. This might sound crazy, but in a lazy language it makes perfect sense to trade code for data.
I won’t bore you with the details, they are available at my GitHub repository. Instead, I will discuss a similar program, one that I worked out some time ago, but wasn’t satisfied with the solution: the famous Conway’s Game of Life. This one actually uses an infinite grid, and I did implement it previously using a comonad. But this time I was more ambitious: I wanted to generate this two-dimensional comonad by composing a pair of one-dimensional ones.
The idea is simple. Each row of the grid is an infinite bidirectional stream. Since it has a specific “current position,” we’ll call it a cursor. Such a cursor can be easily made into a comonad. You can extract the current value; and you can duplicate a cursor by creating a cursor of cursors, each shifted by the appropriate offset (increasing in one direction, decreasing in the other).
A two-dimensional grid can then be implemented as a cursor of cursors–the inner one extending horizontally, and the outer one vertically.
It should be a piece of cake to define a comonad instance for it: extract should be a composition of (extract . extract) and duplicate a composition of (duplicate . fmap duplicate), right? It typechecks, so it must be right. But, just in case, like every good Haskell programmer, I decided to check the comonad laws. There are three of them:
extract . duplicate = id
fmap extract . duplicate = id
duplicate . duplicate = fmap duplicate . duplicate
And they failed! I must have done something illegal, but what?
In cases like this, it’s best to turn to basics–which means category theory. Compared to Haskell, category theory is much less verbose. A comonad is a functor 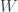 equipped with two natural transformations:
equipped with two natural transformations:


In Haskell, we write the components of these transformations as:
extract :: w a -> a
duplicate :: w a -> w (w a)
The comonad laws are illustrated by the following commuting diagrams. Here are the two counit laws:
and one associativity law:
These are the same laws we’ve seen above, but the categorical notation makes them look more symmetric.
So the problem is: Given a comonad , is the composition  also a comonad? Can we implement the two natural transformations for it?
also a comonad? Can we implement the two natural transformations for it?


The straightforward implementation would be:

corresponding to (extract . extract), and:

corresponding to (duplicate . fmap duplicate).
To see why this doesn’t work, let’s ask a more general question: When is a composition of two comonads, say  , again a comonad? We can easily define a counit:
, again a comonad? We can easily define a counit:

The comultiplication, though, is tricky:

Do you see the problem? The result is  but it should be
but it should be  . To make it a comonad, we have to be able to push
. To make it a comonad, we have to be able to push  through
through  in the middle. We need to distribute over through a natural transformation:
in the middle. We need to distribute over through a natural transformation:

But isn’t that only relevant when we compose two different comonads–surely any functor distributes over itself! And there’s the rub: Not every comonad distributes over itself. Because a distributive comonad must preserve the comonad laws. In particular, to restore the the counit law we need this diagram to commute:
and for the comultiplication law, we require:
Even if the two comonad are the same, the counit condition is still non-trivial:
The two whiskerings of  are in general not equal. All we can get from the original comonad laws is that they are only equal when applied to the result of comultiplication:
are in general not equal. All we can get from the original comonad laws is that they are only equal when applied to the result of comultiplication:
 .
.
Equipped with the distributive mapping 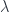 we can complete our definition of comultiplication for a composition of two comonads:
we can complete our definition of comultiplication for a composition of two comonads:

Going back to our Haskell code, we need to impose the distributivity condition on our comonad. There is a type class for it defined in Data.Distributive:
class Functor w => Distributive w where
distribute :: Functor f => f (w a) -> w (f a)
Thus the general formula for composing two comonads is:
instance (Comonad w2, Comonad w1, Distributive w1) =>
Comonad (Compose w2 w1) where
extract = extract . extract . getCompose
duplicate = fmap Compose . Compose .
fmap distribute . duplicate . fmap duplicate .
getCompose
In particular, it works for composing a comonad with itself, as long as the comonad distributes over itself.
Equipped with these new tools, let’s go back to implementing a two-dimensional infinite grid. We start with an infinite stream:
data Stream a = (:>) { headS :: a
, tailS :: Stream a}
deriving Functor
infixr 5 :>
What does it mean for a stream to be distributive? It means that we can transpose a “matrix” whose rows are streams. The functor f is used to organize these rows. It could, for instance, be a list functor, in which case you’d have a list of (infinite) streams.
[ 1 :> 2 :> 3 ..
, 10 :> 20 :> 30 ..
, 100 :> 200 :> 300 ..
]
Transposing a list of streams means creating a stream of lists. The first row is a list of heads of all the streams, the second row is a list of second elements of all the streams, and so on.
[1, 10, 100] :>
[2, 20, 200] :>
[3, 30, 300] :>
..
Because streams are infinite, we end up with an infinite stream of lists. For a general functor, we use a recursive formula:
instance Distributive Stream where
distribute :: Functor f => f (Stream a) -> Stream (f a)
distribute stms = (headS stms) :> distribute (tailS stms)
(Notice that, if we wanted to transpose a list of lists, this procedure would fail. Interestingly, the list monad is not distributive. We really need either fixed size or infinity in the picture.)
We can build a cursor from two streams, one going backward to infinity, and one going forward to infinity. The head of the forward stream will serve as our “current position.”
data Cursor a = Cur { bwStm :: Stream a
, fwStm :: Stream a }
deriving Functor
Because streams are distributive, so are cursors. We just flip them about the diagonal:
instance Distributive Cursor where
distribute :: Functor f => f (Cursor a) -> Cursor (f a)
distribute fCur = Cur (distribute (bwStm fCur))
(distribute (fwStm fCur))
A cursor is also a comonad:
instance Comonad Cursor where
extract (Cur _ (a :> _)) = a
duplicate bi = Cur (iterateS moveBwd (moveBwd bi))
(iterateS moveFwd bi)
duplicate creates a cursor of cursors that are progressively shifted backward and forward. The forward shift is implemented as:
moveFwd :: Cursor a -> Cursor a
moveFwd (Cur bw (a :> as)) = Cur (a :> bw) as
and similarly for the backward shift.
Finally, the grid is defined as a cursor of cursors:
type Grid a = Compose Cursor Cursor a
And because Cursor is a distributive comonad, Grid is automatically a lawful comonad. We can now use the comonadic extend to advance the state of the whole grid:
generations :: Grid Cell -> [Grid Cell]
generations = iterate $ extend nextGen
using a local function:
nextGen :: Grid Cell -> Cell
nextGen grid
| cnt == 3 = Full
| cnt == 2 = extract grid
| otherwise = Empty
where
cnt = countNeighbors grid
You can find the full implementation of the Game of Life and the solution of the Advent of Code puzzle, both using comonad composition, on my GitHub.











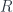
, with
and

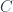











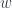




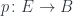
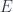

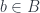

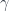







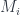






























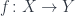 and
and  , such that their compositions are identity maps,
, such that their compositions are identity maps,  and
and  , respectively.
, respectively. 
 and a point. The point is a trivial topological space where only the whole space (here, the singleton
and a point. The point is a trivial topological space where only the whole space (here, the singleton  ) and the empty set are open.
) and the empty set are open.  and
and  (the origin of
(the origin of  is the whole real line, which is open. The pre-image
is the whole real line, which is open. The pre-image  of any open set in
of any open set in 
 is equal to the identity on
is equal to the identity on  , which is emphatically not equal to identity on
, which is emphatically not equal to identity on 


![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=29303b&s=0&c=20201002) .) Such a function exists:
.) Such a function exists:

 , as well as n-dimensional balls are all contractible. A circle, however, is not contractible, because it has a hole.
, as well as n-dimensional balls are all contractible. A circle, however, is not contractible, because it has a hole.  , naturally split into equivalence classes with respect to homotopy. Two paths,
, naturally split into equivalence classes with respect to homotopy. Two paths,  , sharing the same endpoints are in the same class if there is a homotopy between them:
, sharing the same endpoints are in the same class if there is a homotopy between them:





 in
in  .
.  , the fundamental groups at both points are isomorphic. This is because every loop
, the fundamental groups at both points are isomorphic. This is because every loop  at
at  .
.
 with addition. All loops that wind n-times around the circle in one direction correspond to the integer n.
with addition. All loops that wind n-times around the circle in one direction correspond to the integer n. 


 , the set of natural numbers in which every number is considered an open set. Take
, the set of natural numbers in which every number is considered an open set. Take  with the topology inherited from the real line.
with the topology inherited from the real line. 
 in
in 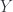 is the obstacle to constructing a homeomorphism or a homotopy equivalence between
is the obstacle to constructing a homeomorphism or a homotopy equivalence between  we’ll assign a fiber, the set of elements of
we’ll assign a fiber, the set of elements of 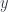 . By abuse of notation, we call such a fiber
. By abuse of notation, we call such a fiber  :
:
 ; for others, it may contain lots elements.
; for others, it may contain lots elements.
![I = [0, 1]](https://s0.wp.com/latex.php?latex=I+%3D+%5B0%2C+1%5D&bg=ffffff&fg=29303b&s=0&c=20201002) to
to 
 that lies above
that lies above  .
.


 . Such potentially “fat” paths are called homotopies. In particular, if we replace
. Such potentially “fat” paths are called homotopies. In particular, if we replace  in this commuting square, such that the resulting triangles commute:
in this commuting square, such that the resulting triangles commute:
 , we can construct a homotopy in
, we can construct a homotopy in 
 into
into  by a surjection
by a surjection  of the exponential
of the exponential  onto
onto  , or the path space of
, or the path space of  is continuous in the compact-open topology of
is continuous in the compact-open topology of 
 .
.
 that makes the two triangles commute. In other words,
that makes the two triangles commute. In other words, 
 .
.



 .
.
 and
and 

 that make the outer square commute, there exist a diagonal morphism
that make the outer square commute, there exist a diagonal morphism  (or, in set notation,
(or, in set notation,  ). It turns out that all surjective functions are its right liftings. In other words, all surjections are right-orthogonal to the simplest non-surjective function.
). It turns out that all surjective functions are its right liftings. In other words, all surjections are right-orthogonal to the simplest non-surjective function. 
 picks an element
picks an element  . Similarly, the diagonal function picks an element
. Similarly, the diagonal function picks an element 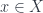 . The commuting triangle tells us that for every
. The commuting triangle tells us that for every  such that
such that  .
.  (or
(or  ).
).
 to a single element
to a single element  and
and  . The diagonal
. The diagonal  or
or  but not both, so we couldn’t make the upper triangle commute.
but not both, so we couldn’t make the upper triangle commute. ; and coverages, which are special kinds of sieves.
; and coverages, which are special kinds of sieves.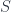 is a subfunctor of another presheaf
is a subfunctor of another presheaf  if it satisfies two conditions.
if it satisfies two conditions.  , we have a set inclusion:
, we have a set inclusion:  ,
, , the function
, the function  is a restriction of the function
is a restriction of the function  . In other words,
. In other words,  and
and  must agree on the subset
must agree on the subset  .
.
 that satisfies the condition that, for any presheaf
that satisfies the condition that, for any presheaf 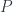 , there is a unique natural transformation
, there is a unique natural transformation  . This will work if every component
. This will work if every component  of this natural transformation is unique, which is true if we choose
of this natural transformation is unique, which is true if we choose  to be the terminal singleton set
to be the terminal singleton set  . Thus the terminal presheaf maps all objects to the terminal set, and all morphisms to the identity on
. Thus the terminal presheaf maps all objects to the terminal set, and all morphisms to the identity on 
 picks a special “True” element in the set
picks a special “True” element in the set  . If the presheaf
. If the presheaf  . The function
. The function  must therefore map the whole subset
must therefore map the whole subset 
 , then both
, then both  . In fact, when defining a subobject, we only care if the embedding of
. In fact, when defining a subobject, we only care if the embedding of  is injective (monomorphic). It’s okay if it permutes the elements of
is injective (monomorphic). It’s okay if it permutes the elements of 

 (not necessarily an element of
(not necessarily an element of 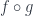 also satisfies the subset-mapping condition:
also satisfies the subset-mapping condition:

 can be made into a presheaf by defining its action on morphisms. The lifting of
can be made into a presheaf by defining its action on morphisms. The lifting of  to a sieve
to a sieve  , defined as a set of arrows
, defined as a set of arrows  , such that
, such that  .
.
 is maximal if and only if
is maximal if and only if  . (Hint: If a sieve is maximal, then it contains identity.)
. (Hint: If a sieve is maximal, then it contains identity.) .
.  is a unique such natural transformation that completes the pullback:
is a unique such natural transformation that completes the pullback: making this diagram into a pullback. Let’s redraw the subfunctor condition for arrows, replacing
making this diagram into a pullback. Let’s redraw the subfunctor condition for arrows, replacing 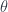 :
:
 . We’ll follow a set of equivalences.
. We’ll follow a set of equivalences. 
 is equivalent to
is equivalent to  . In other words:
. In other words:

 .
.  , acting on
, acting on  is a sieve defined by the following set of arrows:
is a sieve defined by the following set of arrows:
 is a maximal sieve, it must be that
is a maximal sieve, it must be that  .
. . Therefore
. Therefore  that maps objects to sieves, together with the natural transformation
that maps objects to sieves, together with the natural transformation  that picks maximal sieves.
that picks maximal sieves. , etc. The network of “happy” morphisms keeps growing outward. By contrast, the “unhappy” elements of
, etc. The network of “happy” morphisms keeps growing outward. By contrast, the “unhappy” elements of  is the terminal object (here, a singleton set). In principle we should insist that
is the terminal object (here, a singleton set). In principle we should insist that  is to provide an injective function
is to provide an injective function  that embeds
that embeds 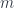 then defines the subset of
then defines the subset of 
 . We do it by means of a universal construction. We postulate that: For every monic
. We do it by means of a universal construction. We postulate that: For every monic  between two arbitrary objects there exist a unique arrow
between two arbitrary objects there exist a unique arrow  ) we first create a set of pairs
) we first create a set of pairs  where
where  and
and  (the only element of the singleton set). But not all
(the only element of the singleton set). But not all  , where
, where  is the element of
is the element of  . This tells us that
. This tells us that 

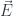 , and we are embedding
, and we are embedding 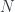 words of context as 12,288-dimensional vectors,
words of context as 12,288-dimensional vectors,  ,
,  (for GPT-3,
(for GPT-3,  tokens). Initially, the mapping from words to embeddings is purely random, but as the training progresses, it is gradually refined using backpropagation.
tokens). Initially, the mapping from words to embeddings is purely random, but as the training progresses, it is gradually refined using backpropagation. that is derived from the context
that is derived from the context  to the embedding
to the embedding 
 as the question: “Who am I with respect to the Universe?” The entries in the matrix
as the question: “Who am I with respect to the Universe?” The entries in the matrix  to every vector
to every vector 
 as a possible response from the
as a possible response from the 
 .
.

 .)
.)
 . The result is a batch of value vectors
. The result is a batch of value vectors  :
:
 . We get the adjusted meaning of our original embedding
. We get the adjusted meaning of our original embedding 
 is infused with the additional information gained from a larger context. It’s closer to the actual meaning. For instance, the word “it” would be nudged towards the noun that it stands for.
is infused with the additional information gained from a larger context. It’s closer to the actual meaning. For instance, the word “it” would be nudged towards the noun that it stands for.





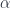 between two virtual objects corresponding to two presheaves
between two virtual objects corresponding to two presheaves  , seen as an arrow
, seen as an arrow  , we get an arrow
, we get an arrow  simply by composition
simply by composition  . Notice that we are thus defining the composition with
. Notice that we are thus defining the composition with  of a natural transformation is a mapping between two arrows.
of a natural transformation is a mapping between two arrows.
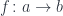 , consider a zigzag path from
, consider a zigzag path from  . The two ways of associating this composition give us
. The two ways of associating this composition give us  .
.
 is a bunch of arrows converging on
is a bunch of arrows converging on  , if we pick a compatible family of
, if we pick a compatible family of  that agrees on all overlaps, then this uniquely determines the element (virtual arrow)
that agrees on all overlaps, then this uniquely determines the element (virtual arrow)  .
.
 and all its open subsets (that is objects that have arrows pointing to
and all its open subsets (that is objects that have arrows pointing to  , even if they are not present in the original cover.
, even if they are not present in the original cover. . Indeed,
. Indeed,  maps all objects either to singletons or to empty sets. In terms of virtual arrows, there is at most one arrow going to
maps all objects either to singletons or to empty sets. In terms of virtual arrows, there is at most one arrow going to  .
.
 is automatically a compatible family. Therefore, if
is automatically a compatible family. Therefore, if  and the set
and the set  .
. and
and  .
.
 is a member of the hom-set
is a member of the hom-set  . Now consider the fact that
. Now consider the fact that  is a presheaf,
is a presheaf,  , and ask the question: Is a cover a “subfunctor” of
, and ask the question: Is a cover a “subfunctor” of  ,
,  is a subset of
is a subset of  and, for each arrow
and, for each arrow  , the function
, the function  is a restriction of
is a restriction of 
 is non-empty for any object
is non-empty for any object  ‘s.
‘s.
 connecting it to some element
connecting it to some element  of the cover. Functoriality requires the (virtual) composition
of the cover. Functoriality requires the (virtual) composition  to exist.
to exist.
 . A coverage assigns a collection of covers to every object, satisfying the sub-coverage conditions described in the previous post. A category with coverage is called a site.
. A coverage assigns a collection of covers to every object, satisfying the sub-coverage conditions described in the previous post. A category with coverage is called a site. , to our category. The set
, to our category. The set  .
.
 . The presheaf lifts it to a function between sets:
. The presheaf lifts it to a function between sets:  (contravariance means that the arrow is reversed). For any
(contravariance means that the arrow is reversed). For any  we can define the composition
we can define the composition 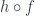 to be
to be  .
.
 that are in the cover of
that are in the cover of 
 . It’s as if the objects
. It’s as if the objects  a matching family, if this new covering respects the existing intersections. If
a matching family, if this new covering respects the existing intersections. If 
 ‘s intersect as covers of
‘s intersect as covers of  and every matching family
and every matching family 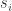 there exists a unique
there exists a unique  that factorizes those
that factorizes those 
