You don’t need to know anything about category theory to use Haskell as a programming language. But if you want to understand the theory behind Haskell or contribute to its development, some familiarity with category theory is a prerequisite.
Category theory is very easy at the beginning. I was able to explain what a category is to my 10-year old son. But the learning curve gets steeper as you go. Functors are easy. Natural transformations may take some getting used to, but after chasing a few diagrams, you’ll get the hang of it. The Yoneda lemma is usually the first serious challenge, because to understand it, you have to be able to juggle several things in your mind at once. But once you’ve got it, it’s very satisfying. Things just fall into place and you gain a lot of intuition about categories, functors, and natural transformations.
A Teaser Problem
You are given a polymorphic function imager that, for any function from Bool to any type r, returns a list of r. Try running this code in the School of Haskell, with colorMap, heatMap, and soundMap. You may also define your own function of Bool and pass it to imager.
{-# LANGUAGE ExplicitForAll #-}
imager :: forall r . ((Bool -> r) -> [r])
imager = ???
data Color = Red | Green | Blue deriving Show
data Note = C | D | E | F | G | A | B deriving Show
colorMap x = if x then Blue else Red
heatMap x = if x then 32 else 212
soundMap x = if x then C else G
main = print $ imager colorMap
Can you guess the implementation of imager? How many possible imagers with the same signature are there? By the end of this article you should be able to validate your answers using the Yoneda’s lemma.
Categories
A category is a bunch of objects with arrows between them (incidentally, a “bunch” doesn’t mean a set but a more generall collection). We don’t know anything about the objects — all we know is the arrows, a.k.a morphisms.
Our usual intuition is that arrows are sort of like functions. Functions are mappings between sets. Indeed, morphisms have some function-like properties, for instance composability, which is associative:

Fig 1. Associativity of morphisms demonstrated on Haskell functions. (In my pictures, piggies will represent objects; sacks of potatoes, sets; and fireworks, morphisms.)
h :: a -> b
g :: b -> c
f :: c -> d
f . (g . h) == (f . g) . h
There is also an identity morphism for every object in a category, just like the id function:

Fig 2. The identity morphism.
id :: a -> a
id . f == f . id == f
In all Haskell examples I’ll be using the category Hask of Haskell types, with morphisms being plain old functions. An object in Hask is a type, like Int, [Bool], or [a]->Int. Types are nothing more than just sets of values. Bool is a two element set {True, False}, Integer is the set of all integers, and so on.
In general, a category of all sets and functions is called Set .
So how good is this sets-and-functions intuition for an arbitrary category? Are all categories really like collections of sets, and morphisms are like functions from set to set? What does the word like even mean in this context?
Functors
In category theory, when we say one category is “like” another category, we usually mean that there is a mapping between the two. For this mapping to be meaningful, it should preserve the structure of the category. So not only every object from one category has to be mapped into an object from another category, but also all morphisms must be mapped correctly — meaning they should preserve composition. Such a mapping has a name: it’s called a functor.
Functors in Hask are described by the type class Functor
class Functor f where
fmap :: (a -> b) -> (f a -> f b)
A Haskell Functor maps types into types and functions into functions — a type constructor does the former and fmap does the latter.
A type contructor is a mapping from one type to another. For instance, a list type constructor takes any type a and creates a list type, [a].
So instead of asking if every category is “like” the Set category, we can ask a more precise question: For what types of categories (if not all of them) there exist functors that map them into Set . Such categories are called representable, meaning they have a representation in Set .
As a physicist I had to deal a lot with groups, such as groups of spacetime rotations in various dimensions or unitary groups in complex spaces. It was very handy to represent these abstract groups as matrices acting on vectors. For instance, different representations of the same Lorenz group (more precisely, SL(2, C)) would correspond to physical particles with different spins. So vector spaces and matrices are to abstract groups as sets and functions are to abstract categories.
Yoneda Embedding
One of the things Yoneda showed is that there is at least one canonical functor from any so called locally small category into the category of sets and functions. The construction of this functor is surpisingly easy, so let me sketch it.
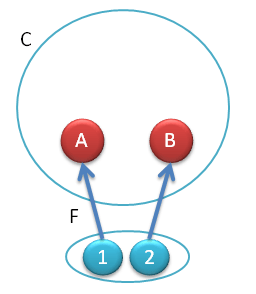
This functor should map every object in category C into a set. Set of what? It doesn’t really matter, a set is a set. So how about using a set of morphisms?

Fig 3. The Yoneda embedding. Object X is mapped by the functor into the set HA(X). The elements of the set correspond to morphisms from A to X.
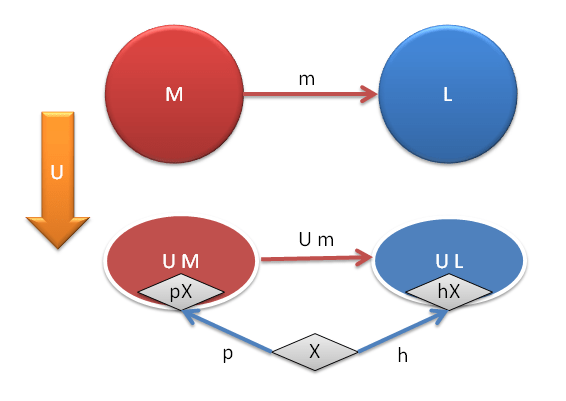
How can we map any object into a set of morphisms? Easy. First, let’s arbitrarily fix one object in the category C, call it A. It doesn’t matter which object we pick, we’ll just have to hold on to it. Now, for every object X in C there is a set of morphisms (arrows) going from our fixed A to this X. We designate this set to be the image of X under the functor we are constructing. Let’s call this functor HA. There is one element in the set HA(X) for every morphism from A to X.
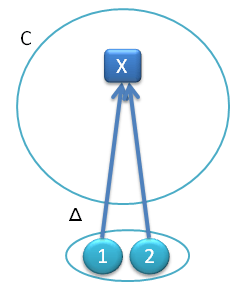
A functor must define a mapping of objects to objects (to sets, in our case) and morphisms to morphisms (to functions in our case). We have established the first part of the mapping. To define the second part, let’s pick an arbitrary morphism f from X to Y. We have to map it to some function from the set HA(X) to the set HA(Y).

Fig 4. The Yoneda functor also maps morphisms. Here, morphism f is mapped into the function HA(f) between sets HA(X) and HA(Y).
Let’s define this function, we’ll call it HA(f), through its action on any element of the set HA(X), call it x. By our construction, x corresponds to some particular morphism, u, from A to X. We now have at our disposal two morphisms, u :: A -> X and f :: X -> Y (that’s the morphism we are mapping). We can compose them. The result f . u is a morphism from A to Y, so it’s a member of the set HA(Y). We have just defined a function that takes an x from HA(X) and maps it into y from HA(Y), and this will be our HA(f).
Of course, you have to prove that this construction of HA is indeed a functor preserving composition of morphisms, but that’s reasonably easy, once the technique we have just used becomes familiar to you. Here’s the gist of this technique: Use components! When you are defining a functor from category C to category D, pick a component — an object X in C — and define its image, F(X). Then pick a morphism f in C, say from X to Y, and define its image, F(f), as a particular morphism from F(X) to F(Y).
Similarly, when defining a function from set S to T, use its components. Pick an element x of S and define its image in T. That’s exactly what we did in our construction.
Incidentally, what was that requirement that the category C be locally small? A category is locally small if the collection of morphisms between any two objects forms a set. This may come as a surprise but there are things in mathematics that are too big to be sets. A classic example is a collection of all sets, which cannot be a set itself, because it would lead to a paradox. A collection of all sets, however, is the basis of the Set category (which, incidentally, turns out to be locally small).
Summary So Far
Let me summarize what we’ve learned so far. A category is just a bunch of abstract objects and arrows between them. It tells us nothing about the internal structure of objects. However, for every (locally small) category there is a structure-preserving mapping (a functor) that maps it into a category of sets. Objects in the Set category do have internal structure: they have elements; and morphisms are functions acting on those elements. A representation maps the categorie’s surface structure of morphisms into the internal structure of sets.
It is like figuring out the properties of orbitals in atoms by looking at the chemical compounds they form, and at the way valencies work. Or discovering that baryons are composed of quarks by looking at their decay products. Incidentally, no one has ever “seen” a free quark, they always live inside other particles. It’s as if physicists were studying the “category” of baryons by mapping them into sets of quarks.
A Bar Example
This is all nice but we need an example. Let’s start with “A mathematician walks into a bar and orders a category.” The barman says, “We have this new tasty category but we can’t figure out what’s in it. All we know is that it has just one object A” — (“Oh, it’s a monoid,” the mathematician murmurs knowingly) — “…plus a whole bunch of morphisms. Of course all these morphisms go from A to A, because there’s nowhere else to go.”
What the barman doesn’t know is that the new category is just a re-packaging of the good old set of ASCII strings. The morphisms correspond to appending strings. So there is a morphism called foo that apends the string "foo"
foo :: String -> String
foo = (++"foo")
main = putStrLn $ foo "Hello "
and so on.
“I can tell you what’s inside A,” says the mathematician, “but only up to an isomorphism. I’m a mathematician not a magician.”
She quickly constructs a set that contains one element for each morphism — morphisms must, by law, be listed by the manufacturer on the label. So, when she sees foo, she puts an element with the label “foo”, and so on. Incidentally, there is one morphism with no name, which the mathematician maps to an empty label. (In reality this is an identity morphism that appends an empty string.)
“That’s what’s inside the object A,” she says.
“Moreover, this set comes equipped with functions that rearrange its elements. In fact there is a function for every morphism listed in the category,” she says. “Name any morphism and I’ll construct you a function.”
The barman gives her morphism p, which in reality is:
p = (++"p")
“Okay,” she says, “here’s how I construct the corresponding function. Pick any element in my set.”
The barman picks “foo”.
“Okay, ‘foo’ corresponds to the morphism foo,” she says, “so tell me what you call the morphism that’s the composition of foo and p?” (By law, the manufacturer is obliged to specify all admissible compositions of morphisms on the label.)
“It’s called foop,” says the barman.
Quick check:
p . foo == (++"p") . (++"foo") == (++"foop")
foop = (++"foop")
“Okay,” she says, “the function corresponding to p maps “foo” into “foop”. Hm, how curious! I bet this function will map the no-label elment into “p”, is that right?”
“Indeed, it does,” says the barman.
Quick check:
p . id == p
“I bet you this is just a string monoid,” says the mathematician.
“I think I’ll have my usual Top on the rocks instead.”
Natural Transformations
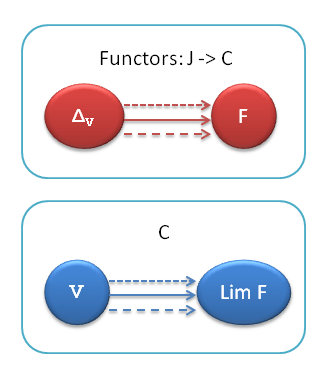
We’ve seen how to construct a representation of any (locally small) category in Set by selecting an arbitrary object A in the category and studying morphisms originating at A. What if we choose a different object B instead? How different is the representation HA from HB? For that matter, what if we pick any functor F from C to Set ? How is it related to HA? That’s what the Yoneda lemma is all about.
Let me start with a short recap.
A functor is a mapping between categories that preserves their structure. The structure of a category is defined by the way its morphisms compose. A functor F maps objects into objects and morphism into morphisms in such a way that if f . g = h then F(f) . F(g) = F(h).
A natural transformation is a mapping between functors that preserves the structure of the underlying categories.

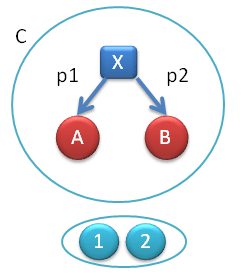
Fig 5. A component of a transformation Φ at X. Φ maps functor F into functor G, ΦX is a morphism that maps object F(X) into object G(X).
First we have to understand how to define mappings between functors. Suppose we have functors F and G, both going from category C to category D. For a given object X in C, F will map it into F(X) in D, and G will map it into G(X) in D. A mapping Φ between functors must map object F(X) to object G(X), both in category D. We know that a mapping of objects is called a morphism. So for every object X we have to provide a morphism ΦX from F(X) to G(X). This morphism is called a component of Φ at X. Or, looking at it from a different angle, Φ is a family of morphisms parameterized by X.
An Example of Natural Transformation
Just to give you some Haskell intuition, consider functors on Hask . These are mapping of types (type constructors) such as a -> [a] or a -> Maybe a, with the corresponging mappings of morphisms (functions) defined by fmap. Recall:
class Functor f where
fmap :: (a -> b) -> (f a -> f b)
The mapping between Haskell functors is a family of functions parameterized by types. For instance, a mapping between the [] functor and the Maybe functor will map a list of a, [a] into Maybe a. Here’s an example of such a family of functions called safeHead:
safeHead :: [a] -> Maybe a
safeHead [] = Nothing
safeHead (x:xs) = Just x
A family of functions parameterized by type is nothing special: it’s called a polymorphic function. It can also be described as a function on both types and values, with a more verbose signature:
{-# LANGUAGE ExplicitForAll #-}
safeHead :: forall a . [a] -> Maybe a
safeHead [] = Nothing
safeHead (x:xs) = Just x
main = print $ safeHead ["One", "Two"]
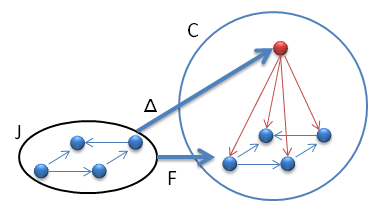
Let’s go back to natural transformations. I have described what it means to define a transformation of functors in terms of objects, but functors also map morphism. It turns out, however, that the tranformation of morphisms is completely determined by the two functors. A morphism f from X to Y is transformed under F into F(f) and under G into G(f). G(f) must therefore be the image of F(f) under Φ. No choice here! Except that now we have two ways of going from F(X) to G(Y).

Fig 6. The naturality square. Φ is a natural transformation if this diagram commutes, that is, both paths are equivalent.
We can first use the morphism F(f) to take us to F(Y) and then use ΦY to get to G(Y). Or we can first take ΦX to take us to G(X), and then G(f) to get to G(Y). We call Φ a natural transformation if these two paths result in the same morphism (the diagram commutes).
The best insight I can offer is that a natural transformation works on structure, while a general morphism works on contents. The naturality condition ensures that it doesn’t matter if you first rearrange the structure and then the content, or the other way around. Or, in other words, that a natural transformation doesn’t touch the content. This will become clearer in examples.
Going back to Haskell: Is safeHead a natural transformation between two functors [] and Maybe? Let’s start with a function f from some type a to b. There are two ways of mapping this function: one using the fmap defined by [], which is the list function map; and the other using the Maybe‘s fmap, which is defined in the Maybe‘s functor instance definition:
instance Functor Maybe where
fmap f (Just x) = Just (f x)
fmap _ Nothing = Nothing
The two path from [a] to Maybe b are:
- Apply
fmap f to [a] to get [b] and then safeHead it, or
- Apply
safeHead to [a] and then use the Maybe version of fmap.
There are only two cases to consider: an empty list and a non-empty list. For an emtpy list we get Nothing both ways, otherwise we get Just f acting on the first element of the list.
We have thus shown that safeHead is a natural transformation. There are more interestig examples of natural transformations in Haskell; monadic return and join come to mind.
The intuition behind natural transformations is that they deal with structure, not contents. safeHead couldn’t care less about what’s stored in a list, but it understands the structure of the list: things like the list being empty, or having a first element. The type of this element doesn’t matter. In Haskell, natural transformations are polymorphic functions that can, like safeHead be typed using forall:
safeHead :: forall a . [a] -> Maybe a
Yoneda Lemma
Going back to the Yoneda lemma, it states that for any functor from C to Set there is a natural transformation from our canonical representation HA to this functor. Moreover, there are exactly as many such natural transformations as there are elements in F(A).
That, by the way, answers our other question about the dependence on the choice of A in the Yoneda embedding. The Yoneda lemma tells us that there are natural transformations both ways between HA and HB.
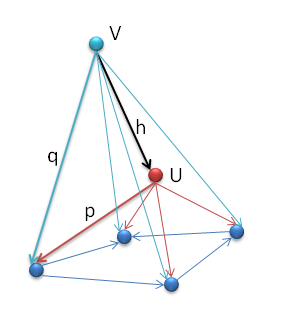
Amazingly, the proof of the Yoneda lemma, at least in one direction, is quite simple. The trick is to first define the natural transformation Φ on one special element of HA(A): the element that corresponds to the identity morphism on A (remember, there is always one of these for every object). Let’s call this element p. Its image under ΦA will be in F(A), which is a set. You can pick any element of this set and it will define a different but equally good Φ. Let’s call this element q. So we have fixed ΦA(p) = q.
Now we have to define the action of Φ on an arbitrary element in the image of HA. Remember that the functor HA transforms objects in C into sets. So let’s take an arbitrary object X and its image HA(X). The elements in HA(X) correspond to morphisms from A to X. So let’s pick one such morphism and call it f. Its image is an element r in HA(X). The question is, what does r map into under Φ? Remember, it’s image must be an element of F(X).

Fig 7. The mappings in the Yoneda lemma. F is an arbitrary functor. Any choice of p determines the morphism ΦX for any X.
To figure that out, let’s consider the F route. F being a functor transforms our morphism f into F(f) — which is a morphism from F(A) to F(X). But, as you may remember, we have selected a special element in F(A) — our q. Now apply F(f) to q and you get an element in F(X), call it s. (Remember, F(f) is just a regular function between two sets, F(A) and F(X).)
There’s nothing more natural than picking ΦX(r) to be this s! We have thus defined a natural transformation Φ for any X and r.
The straightforward proof that this definition of Φ is indeed natural is left as an exercise to the user.
A Haskell Example
I’ve been very meticulous about distinguishing between morphisms from A to X in C and the corresponding set elements in HA(X). But in practice it’s more convenient to skip the middle man and define natural transformations in the Yoneda lemma as going directly from these morphisms to F(X). Keeping this in mind, the Haskell version of the Yoneda lemma is ofter written as follows:
forall r . ((a -> r) -> f r) ~ f a
where the (lowercase) f is the functor (think of it as a type constructor and its corresponding fmap), (a -> r) is a function corresponding to the morphism from A to X in our orginal formulation. The Yoneda’s natural transformation maps this morphism into the image of r under f — the F(X) in the original formulation. The forall r means that the function ((a -> r) -> f r) works for any type r, as is necessary to make it a natural transformation.
The lemma states that the type of this function, forall r . ((a -> r) -> f r) is equivalent to the much simpler type f a. If you remember that types are just sets of values, you can interpret this result as stating that there is one-to-one correspondence between natural transformations and values of the type f r.
Remember the example from the beginning of this article? There was a function imager with the following signature:
imager :: forall r . ((Bool -> r) -> [r])
This looks very much like a natural transformation from the Yoneda lemma with the type a fixed to Bool and the functor, the list functor []. (I’ll call the functions Bool->r iffies.)
The question was, how many different implementations of this signature are there?
The Yoneda lemma tells us exactly how to construct such natural transformations. It instructs us to start with an identity iffie: idBool :: Bool -> Bool, and pick any element of [Bool] to be its image under our natural transformation. We can, for instance, pick [True, False, True, True]. Once we’ve done that, the action of this natural transformation on any iffie h is fixed. We just map the morphism h using the functor (in Haskell we fmap the iffie), and apply it to our pick, [True, False, True, True].
Therefore, all natural transformations with the signature:
forall r . ((Bool -> r) -> [r])
are in one-to-one correspondence with different lists of Bool.
Conversely, if you want to find out what list of Bool is hidden in a given implementation of imager, just pass it an identity iffie. Try it:
{-# LANGUAGE ExplicitForAll #-}
imager :: forall r . ((Bool -> r) -> [r])
imager iffie = fmap iffie [True, False, True, True]
data Color = Red | Green | Blue deriving Show
data Note = C | D | E | F | G | A | B deriving Show
colorMap x = if x then Blue else Red
heatMap x = if x then 32 else 212
soundMap x = if x then C else G
idBool :: Bool -> Bool
idBool x = x
main = print $ imager idBool
Remember, this application of the Yoneda lemma is only valid if imager is a natural transformation — its naturality square must commute. The two functors in the imager naturality diagram are the Yoneda embedding and the list functor. Naturality of imager translates into the requirement that any function f :: a -> b modifying an iffie could be pulled out of the imager:
imager (f . iffie) == map f (imager iffie)
Here’s an example of such a function translating colors to strings commuting with the application of imager:
{-# LANGUAGE ExplicitForAll #-}
imager :: forall r . ((Bool -> r) -> [r])
imager iffie = fmap iffie [True, False, True, True]
data Color = Red | Green | Blue deriving Show
colorMap x = if x then Blue else Red
f :: Color -> String
f = show
main = do
print $ imager (f . colorMap)
print $ map f (imager colorMap)
The Structure of Natural Transformations
That brings another important intuition about the Yoneda lemma in Haskell. You start with a type signature that describes a natural transformation: a particular kind of polymorphic function that takes a probing function as an argument and returns a type that’s the result of a functor acting on the result type of the probing function. Yoneda tells us that the structure of this natural transformation is tightly constrained.
One of the strengths of Haskell is its very strict and powerful type system. Many Haskell programers start designing their programs by defining type signatures of major functions. The Yoneda lemma tells us that type signatures not only restrict how functions can be combined, but also how they can be implemented.
As an extreme, there is one particular signature that has only one implementation: a->a (or, more explicitly, forall a. a -> a). The only natural implementation of this signature is the identity function, id.
Just for fun, let me sketch the proof using the Yoneda lemma. If we pick the source type as the singleton unit type, (), then the Yoneda embedding consists of all functions taking unit as an argument. A function taking unit has only one return value so it’s really equivalent to this value. The functor we pick is the identity functor. So the question is, how many natural tranformation of the the following type are there?
forall a. ((() -> a) -> a)
Well, there are as many as there are elements in the image of () under the identity functor, which is exactly one! Since a function ()->a can be identified with a, it means we have only one natural transformation with the following signature:
forall a. (a -> a)
Moreover, by Yoneda construction, this function is defined by fmapping the function ()->a over the element () using the identity functor. So our natural transformation, when probed with a value of the type a will return the same value. But that’s just the definition of the identity function. (In reality things are slightly more complicated because every Haskell type must include undefined, but that’s a different story.)
Here’s an exercise for the reader: Show that the naturality square for this example is equivalent to id commuting with any function: f . id == id . f.
Conclusion
I hope I provided you with enough background information and intuition so that you’ll be able to easily read more advanced blog posts, like this one:
Reverse Engineering Machines with the Yoneda Lemma by Dan Piponi, or GADTs by Gabriel Gonzales.
Acknowledgments
I’d like to thank Gabriel Gonzales for providing useful comments and John Wiegley, Michael Sloan, and Eric Niebler for many interesting conversations.