Previously: Models of (Dependent) Type Theory.
There is a deep connection between mathematics and programming. Computer programs deal with such mathematical objects as numbers, vectors, monoids, functors, algebras, and many more. We can implement such structures in most programming languages. For instance, here’s the definition of natural numbers in Haskell:
data Nat where
Z :: Nat -- zero
S :: Nat -> Nat -- successor
There is a problem, though, with encoding the laws that they are supposed to obey. These laws are expressed using equalities. But not all equalities are created equal. Take, for instance, this definition of addition:
plus :: Nat -> Nat -> Nat
plus Z n = n
plus (S n) m = S (plus n m)
The first clause tells us that  is equal to
is equal to  . This is called definitional equality, since it’s just part of the definition. However, if we reverse the order of the addends and try to prove
. This is called definitional equality, since it’s just part of the definition. However, if we reverse the order of the addends and try to prove  , there is no obvious shortcut. We have to prove it the hard way! This second type of equality is called propositional.
, there is no obvious shortcut. We have to prove it the hard way! This second type of equality is called propositional.
In traditional mathematics equality is treated as a relation. Two things are either equal or not. In type theory, on the other hand, equality is a type. It’s a type of proofs of equality. When you postulate that two things are equal, you specify the type of proofs that you are willing to accept.
Equality is a dependent type, because it depends on the values that are being compared. For a pair of values of the type  , the identity (or equality) type is denoted by
, the identity (or equality) type is denoted by  :
:

(In this notation, assumptions are listed above the horizontal line.)
You’ll also see  written as
written as  , or even
, or even  , if the type is obvious from the context.
, if the type is obvious from the context.
When two values are not equal, this type is uninhabited. Otherwise it’s inhabited by proofs, or witnesses, of equality. This is consistent with the propositions as types interpretation of type theory.
For the identity type to be useful, we have to have a way to populate it with values — proofs of equality. We do that by providing an introduction rule:

The constructor  generates a witness to the obvious fact that, for every
generates a witness to the obvious fact that, for every  ,
,  . Here, is the abbreviation of reflexivity.
. Here, is the abbreviation of reflexivity.
At first sight it doesn’t seem like we have gained anything by turning equality into a type. Indeed, if were the only inhabitant of , we’d just buy ourselves a lot of headaches for nothing. The trouble is that, if there is a type , then there’s also a type  (type of equality of proofs of equality), and so on, ad infinitum. This used to be a bane of Martin Löf type theory, but it became a bounty for Homotopy Type Theory. So let’s imagine that the identity type may have non-trivial inhabitants. We’ll call these inhabitants paths. The trivial paths generated by are degenerate do-nothing loops.
(type of equality of proofs of equality), and so on, ad infinitum. This used to be a bane of Martin Löf type theory, but it became a bounty for Homotopy Type Theory. So let’s imagine that the identity type may have non-trivial inhabitants. We’ll call these inhabitants paths. The trivial paths generated by are degenerate do-nothing loops.
But first, let’s consider the identity elimination rule: the mapping out of the identity type. What data do we need to provide in order to define a function from a path  to some type
to some type 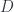 ? In full generality, should be a dependent type family parameterized by the path
? In full generality, should be a dependent type family parameterized by the path  as well as its endpoints
as well as its endpoints  and
and 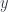 :
:

Our goal is to define a -valued mapping 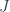 that works for any path in :
that works for any path in :

The trick is to realize that there is only one family of constructors of the identity type,  , so it’s enough to specify how is supposed to act on it. We do this by providing a dependent function
, so it’s enough to specify how is supposed to act on it. We do this by providing a dependent function  (a dependent function is a function whose return type depends on the value of its argument):
(a dependent function is a function whose return type depends on the value of its argument):

This is very similar to constructing a mapping out of a Boolean by specifying its action on the two constructors,  and
and  . Except that here we have a whole family of constructors parameterized by .
. Except that here we have a whole family of constructors parameterized by .
This is enough information to uniquely determine the action of on any path, provided it agrees with along :

This procedure for defining mappings out of identity types is called path induction.
Categorical Model
We’ll build a categorical interpretation of identity types making as few assumptions as possible. We’ll model as a fibration:

The introduction rule asserts the existence of the arrow:

For any given  , this arrow selects a diagonal element of the identity type,
, this arrow selects a diagonal element of the identity type,  . When projected down to
. When projected down to 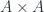 using
using 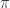 , it lands on the diagonal of . In a cartesian category, the diagonal is defined by the arrow
, it lands on the diagonal of . In a cartesian category, the diagonal is defined by the arrow  , so we have:
, so we have:

In other words, there is a factorization of the diagonal arrow.
The elimination rule starts with defining a dependent type , which can be modeled as a fibration 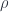 :
:

We provide a dependent function , which is interpreted as an arrow  that maps to an element
that maps to an element  of
of  . So, when projected back to using , it produces the same element as
. So, when projected back to using , it produces the same element as

Given these assumptions, there exists a mapping:

which is interpreted as a section  . The section condition is:
. The section condition is:

This mapping is unique if we assume that it agrees with when restricted to :

Consequently, we can illustrate the path induction rule using a single commuting diagram:
If the outer square commutes then there is a unique diagonal arrow that makes the two triangles commute. The similarity to the lifting property of homotopy theory is not accidental, as we’ll see next.
Next: Modeling Identity Types.
Previously: (Weak) Factorization Systems.
It’s been known since Lambek that typed lambda calculus can be modeled in a cartesian closed category, CCC. Cartesian means that you can form products, and closed means that you can form function types. Loosely speaking, types are modeled as objects and functions as arrows.
More precisely, objects correspond to contexts— which are cartesian products of types, with the terminal object representing the empty context. Arrows correspond to terms in those contexts.
Mathematicians and computer scientist use special syntax to formalize type theory that is used in lambda calculus. For instance a typing judgment:

states that is a type. The turnstile symbol is used to separate contexts from judgments. Here, the context is empty (nothing on the left of the turnstile). Categorically, this means that is an object.
A more general context 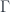 is a product of objects
is a product of objects  . The judgment:
. The judgment:

tells us that the type may depend on other types , in which case is a type constructor. The canonical example of a type constructor is a list.
A term 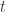 of type in some context is written as:
of type in some context is written as:

We interpret it as an arrow from the cartesian product of types that form to the object :

Things get more interesting when we allow types to not only depend on other types, but also on values. This is the real power of dependent types à la Martin-Löf.
For instance, the judgment:

defines a single-argument type family. For every argument of type it produces a new type  . The canonical example of a dependent type is a counted vector, which encodes length (a value of type
. The canonical example of a dependent type is a counted vector, which encodes length (a value of type  ) in its type.
) in its type.
Categorically, we model a type family as a fibration given by an arrow  . The type is a fiber
. The type is a fiber  .
.
In the case of counted vectors, the projection gives the length of the vector.
In general, a type family may depend on multiple arguments, as in:

Here, each type in the context may depend on the values defined by its predecessor. For instance,  may depend on
may depend on  ,
,  may depend on and
may depend on and  , and so on.
, and so on.
Categorically, we model such a judgment as a tower of fibrations:

Notice that the context is no longer a cartesian product of types but rather an ordered series of fibrations.
A term in a dependently typed system has to satisfy an additional condition: it has to map into the correct fiber. For instance, in the judgment:

not only depends on , but so does the type . If we model as an arrow 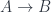 , we have to make sure that
, we have to make sure that  is projected back to . Categorically, we call such maps sections:
is projected back to . Categorically, we call such maps sections:

In other words, a section is an arrow that is a right inverse of a projection, .
Thus a well-formed vector-valued term produces, for every  , a vector of lenght .
, a vector of lenght .
In general, a term:

is interpreted as a section  of the projection
of the projection  .
.
At this point one usually introduces the definitions of dependent sums and products, which requires the modeling category to be locally cartesian closed. We’ll instead concentrate on the identity types, which are closely related to homotopy theory.
Next: Identity Types.





