Previously: Subfunctor Classifier.
We are used to thinking of a mapping as either being invertible or not. It’s a yes or no question. A mapping between sets is invertible if it’s both injective and surjective. It means that it never merges two elements into one, and it covers the whole target set.
But if you are willing to look closer, the failures of invertibility are a whole fascinating area of research. Things get a lot more interesting if you consider mapping between topological spaces, which have to skillfully navigate around various holes and tears in the target space, and shrink or glue together parts of the source space. I will be glossing over some of the topological considerations, concentrating on the big-picture intuitions (both culinary and cinematographic).
Fibrations
In what follows, we’ll be considering a function 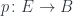 . We’ll call
. We’ll call  a projection from the total set
a projection from the total set 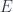 to the base set
to the base set  .
.
Let’s start by considering the first reason for a failure of invertibility: multiple elements being mapped into one. Even though we can’t invert such a mapping, we can use it to fibrate the source .
To each element  we’ll assign a fiber, the set of elements of that are mapped to
we’ll assign a fiber, the set of elements of that are mapped to 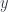 . By abuse of notation, we call such a fiber
. By abuse of notation, we call such a fiber  :
:

For some ‘s, this set may be empty  ; for others, it may contain lots elements.
; for others, it may contain lots elements.
Notice that is an isomorphism if and only if every fiber is a singleton set. This property gives rise to a very useful definition of equivalence in homotopy type theory, where we ask for every fiber to be contractible.
A set-theoretic union of all fibers reconstructs the total set .
Things get more interesting when we move to topological spaces and continuous functions. To begin with, we can define a path in as a continuous mapping from the unit interval ![I = [0, 1]](https://s0.wp.com/latex.php?latex=I+%3D+%5B0%2C+1%5D&bg=ffffff&fg=29303b&s=0&c=20201002) to .
to .

We can then ask if it’s possible to lift this path to , that is to construct  that lies above
that lies above 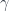 . To do this, we pick the starting point
. To do this, we pick the starting point  that lies above the starting point of , that is
that lies above the starting point of , that is  .
.
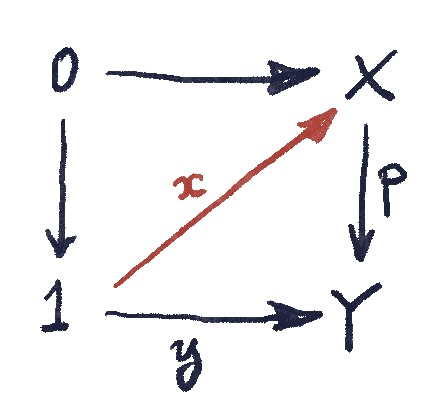
This setup can be summarized in the commuting square:
The lifting  is then the diagonal arrow that makes both triangles commute:
is then the diagonal arrow that makes both triangles commute:
It’s helpful to imagine a path as a trajectory of a point moving through a topological space. The parameter  is then interpreted as time.
is then interpreted as time.
In homotopy theory we generalize this idea to the movement, or deformation, of arbitrary shapes, not just points.
If we describe such a shape as the image of some topological space  , its deformation is a mapping
, its deformation is a mapping  . Such potentially “fat” paths are called homotopies. In particular, if we replace by a single point, we recover our “thin” paths.
. Such potentially “fat” paths are called homotopies. In particular, if we replace by a single point, we recover our “thin” paths.
A homotopy lifting property is expressed as the existence of the diagonal function  in this commuting square, such that the resulting triangles commute:
in this commuting square, such that the resulting triangles commute:
In other words, given a homotopy  of the shape in the base, and an embedding
of the shape in the base, and an embedding  of this shape in above
of this shape in above  , we can construct a homotopy in whose projection is .
, we can construct a homotopy in whose projection is .
Cofibrations
In category theory, every construction has its dual, which is obtained by reversing all the arrows. In topology, there is an analogous relation called the Eckmann-Hilton duality. Besides reversing the arrows, it also dualizes products to exponentials (using the currying adjunction), and injections to surjections.
When dualizing the homotopy lifting diagram, we replace the trivial injection of  into
into  by a surjection
by a surjection  of the exponential
of the exponential  onto . Here, is the set of functions
onto . Here, is the set of functions  , or the path space of . The surjection maps every path
, or the path space of . The surjection maps every path  to its starting point by evaluating it at zero. (The evaluation map
to its starting point by evaluating it at zero. (The evaluation map  is continuous in the compact-open topology of .)
is continuous in the compact-open topology of .)
The homotopy lifting property is thus dualized to the homotopy extension property:
Corresponding to the fibration that deals with the failure of the injectivity of , the homotopy extension property deals with the failure of the surjectivity of  .
.
If the mapping has the extension property for all topological spaces , it is called a cofibration.
Intuitively, a cofibration is an embedding of in such that any “spaghettification” of , that is embedding it in the path space , can be extended to a spaghettification of . plays the role of an ambient space where these operations can be visualized. Later we’ll see how to construct a minimal such ambient space called a mapping cylinder.
Let’s deconstruct the meaning of the outer commuting square.
- embeds into .
- further embeds into , and we end up with the embedding of inside given by
 .
.
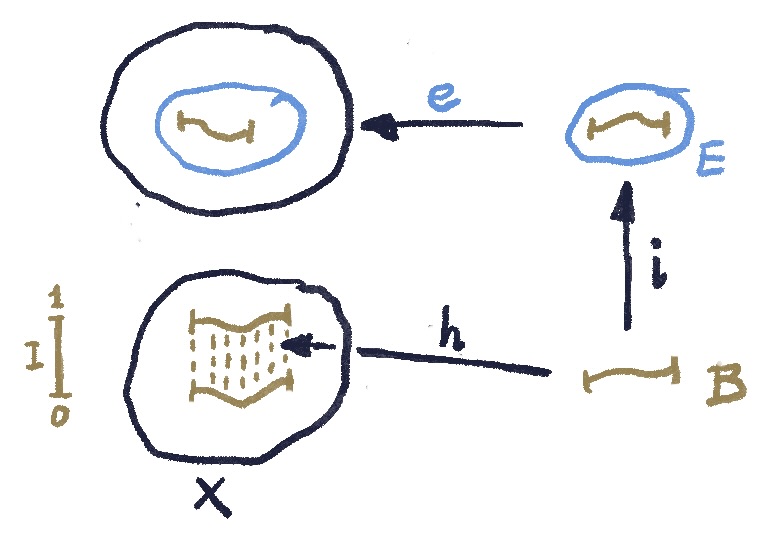
- embeds into the path space of (the dotted paths below).
The commuting condition for this square means that the starting points of all these paths, the result of applying to each of them, coincide with the embedding of into given by . It’s like extruding a bunch of spaghetti, each strand corresponding to a point in .
With this setup, we postulate the existence of the diagonal mapping  that makes the two triangles commute. In other words, is mapped to a family of paths in which, when restricted to the image of coincide with the original mapping .
that makes the two triangles commute. In other words, is mapped to a family of paths in which, when restricted to the image of coincide with the original mapping .
The spaghetti extruded through the shape contain the spaghetti extruded through the shape.
Another intuitive description of this situation uses the idea of homotopy as animation. The strands of spaghetti become trajectories of particles.
We start by setting up the initial scene. We embed in the big space using  .
.
We have the embedding  , which induces the embedding of into :
, which induces the embedding of into :

Then we animate the embedding of using the homotopy

The initial frame of this animation is given by  :
:

We say that is a cofibration if every such animation can be extended to the bigger animation:

whose starting frame is given by :
 .
.
The commuting condition (for the lower triangle) means that the two animations coincide for all  and :
and :

Just like a fiber is an epitome of non-injectiveness, one can define a cofiber as an epitome of non-surjectiveness. It’s essentially the part of that is not covered by .
As a topological space it’s the result of shrinking the image of inside to a point (the resulting topology is called the quotient topology).
Notice that, unlike with fibers, there is just one cofiber for a given cofibration (up to homotopy equivalence).
Lifting Property
A category theorist looking at the two diagrams that define, respectively, homotopy lifting and extension, will immediately ignore all the superfluous details. She will turn the second diagram upside down and merge it with the first diagram to get:
This is how we read the new diagram: If for any morphisms  and
and  that make the outer square commute, there exist a diagonal morphism that makes the two triangles commute, then we say that has the left lifting property with respect to . Equivalently, has the right lifting property with respect to .
that make the outer square commute, there exist a diagonal morphism that makes the two triangles commute, then we say that has the left lifting property with respect to . Equivalently, has the right lifting property with respect to .
Or we can say that the two morphisms are orthogonal to each other.
The motivation for this nomenclature is interesting. In the category of sets, the archetypal non-surjective function is the “absurd”  (or, in set notation,
(or, in set notation,  ). It turns out that all surjective functions are its right liftings. In other words, all surjections are right-orthogonal to the simplest non-surjective function.
). It turns out that all surjective functions are its right liftings. In other words, all surjections are right-orthogonal to the simplest non-surjective function.
Indeed, the function at the bottom  picks an element
picks an element  . Similarly, the diagonal function picks an element
. Similarly, the diagonal function picks an element 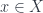 . The commuting triangle tells us that for every there exists an
. The commuting triangle tells us that for every there exists an  such that
such that  .
.
Similarly, we can show that all injective functions are orthogonal to the archetypal non-injective function  (or
(or  ).
).
Indeed, assume that maps two different elements  to a single element
to a single element 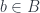 . We could then pick such that
. We could then pick such that  and
and  . The diagonal can map to either
. The diagonal can map to either  or
or  but not both, so we couldn’t make the upper triangle commute.
but not both, so we couldn’t make the upper triangle commute.
Incidentally, injections are also right-orthogonal to the archetypal non-injection.
Next: (Weak) Homotopy Equivalences.

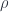



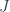










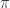

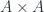





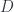



 is neither surjective nor injective. We can however isolate the two “failure modes” if we insert a third set
is neither surjective nor injective. We can however isolate the two “failure modes” if we insert a third set  to be the surjective part of
to be the surjective part of  . We get the (Surj, Inj) factorization of an arbitrary function into a surjection followed by an injection:
. We get the (Surj, Inj) factorization of an arbitrary function into a surjection followed by an injection:

 and
and 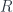 , satisfying conditions loosely analogous to the (Surj, Inj) factorization:
, satisfying conditions loosely analogous to the (Surj, Inj) factorization: , with
, with  and
and 
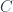 . Its objects are arrows or, more precisely, triples
. Its objects are arrows or, more precisely, triples  . A morphism from
. A morphism from  to
to  is a pair of arrows
is a pair of arrows  that make the following square commute:
that make the following square commute:
 :
:
 . Morphisms are triples of arrows
. Morphisms are triples of arrows  that make the following diagram commute:
that make the following diagram commute:
 is the commuting diagram above. For functoriality, we need the arrow
is the commuting diagram above. For functoriality, we need the arrow 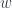 to be determined uniquely.
to be determined uniquely.

 . This time, however, we postulate that
. This time, however, we postulate that 
 to
to 

 . A mapping cylinder
. A mapping cylinder 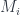 is a topological space that formalizes this picture.
is a topological space that formalizes this picture. , where
, where  is the unit segment, which we use to parameterize the length of each wire. Then we add the target
is the unit segment, which we use to parameterize the length of each wire. Then we add the target  of each wire to its “socket”
of each wire to its “socket”  , identifying each
, identifying each  .
.
 . Notice that
. Notice that  that we’re constructing.
that we’re constructing.
 . For every
. For every  .
. ,
,  is the point in
is the point in  and
and  we define
we define  . It reverses the direction of wires in the cylinder
. It reverses the direction of wires in the cylinder  into the quotient
into the quotient  , such that
, such that  . The latter condition can be written as:
. The latter condition can be written as:
 before embedding it in
before embedding it in 
 will shrink
will shrink  , and inject it into
, and inject it into 
 is injective (
is injective (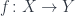 and
and  , such that their compositions are identity maps,
, such that their compositions are identity maps,  and
and  , respectively.
, respectively. 
 and a point. The point is a trivial topological space where only the whole space (here, the singleton
and a point. The point is a trivial topological space where only the whole space (here, the singleton  ) and the empty set are open.
) and the empty set are open.  and
and  (the origin of
(the origin of  is the whole real line, which is open. The pre-image
is the whole real line, which is open. The pre-image  of any open set in
of any open set in 
 is equal to the identity on
is equal to the identity on  , which is emphatically not equal to identity on
, which is emphatically not equal to identity on 


![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=29303b&s=0&c=20201002) .) Such a function exists:
.) Such a function exists:

 , as well as n-dimensional balls are all contractible. A circle, however, is not contractible, because it has a hole.
, as well as n-dimensional balls are all contractible. A circle, however, is not contractible, because it has a hole.  , sharing the same endpoints are in the same class if there is a homotopy between them:
, sharing the same endpoints are in the same class if there is a homotopy between them:





 in
in  .
.  , the fundamental groups at both points are isomorphic. This is because every loop
, the fundamental groups at both points are isomorphic. This is because every loop  at
at  .
.
 with addition. All loops that wind n-times around the circle in one direction correspond to the integer n.
with addition. All loops that wind n-times around the circle in one direction correspond to the integer n. 


 , the set of natural numbers in which every number is considered an open set. Take
, the set of natural numbers in which every number is considered an open set. Take  with the topology inherited from the real line.
with the topology inherited from the real line. 
 in
in 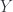 is the obstacle to constructing a homeomorphism or a homotopy equivalence between
is the obstacle to constructing a homeomorphism or a homotopy equivalence between 



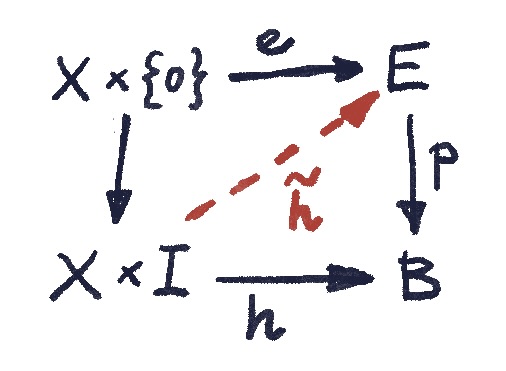




 ; and coverages, which are special kinds of sieves.
; and coverages, which are special kinds of sieves. is a subfunctor of another presheaf
is a subfunctor of another presheaf  if it satisfies two conditions.
if it satisfies two conditions.  ,
, , the function
, the function  is a restriction of the function
is a restriction of the function  . In other words,
. In other words,  and
and  must agree on the subset
must agree on the subset  .
.
 that satisfies the condition that, for any presheaf
that satisfies the condition that, for any presheaf  , there is a unique natural transformation
, there is a unique natural transformation  . This will work if every component
. This will work if every component  of this natural transformation is unique, which is true if we choose
of this natural transformation is unique, which is true if we choose  to be the terminal singleton set
to be the terminal singleton set  . Thus the terminal presheaf maps all objects to the terminal set, and all morphisms to the identity on
. Thus the terminal presheaf maps all objects to the terminal set, and all morphisms to the identity on 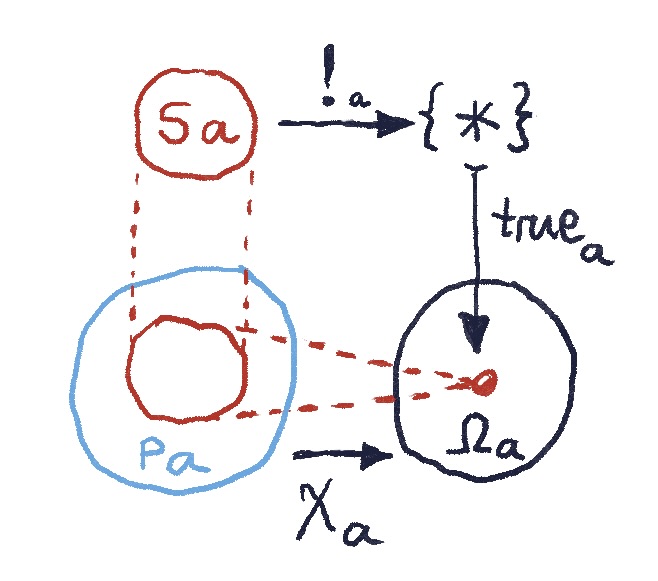
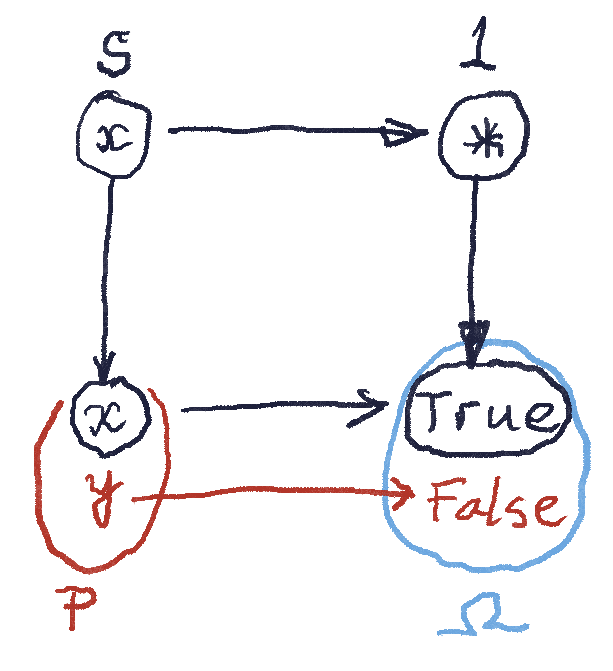
 picks a special “True” element in the set
picks a special “True” element in the set  . If the presheaf
. If the presheaf  . The function
. The function  must therefore map the whole subset
must therefore map the whole subset 
 , then both
, then both  . In fact, when defining a subobject, we only care if the embedding of
. In fact, when defining a subobject, we only care if the embedding of  is injective (monomorphic). It’s okay if it permutes the elements of
is injective (monomorphic). It’s okay if it permutes the elements of 

 (not necessarily an element of
(not necessarily an element of 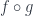 also satisfies the subset-mapping condition:
also satisfies the subset-mapping condition:

 can be made into a presheaf by defining its action on morphisms. The lifting of
can be made into a presheaf by defining its action on morphisms. The lifting of  to a sieve
to a sieve  , defined as a set of arrows
, defined as a set of arrows  , such that
, such that  .
.
 is maximal if and only if
is maximal if and only if  . (Hint: If a sieve is maximal, then it contains identity.)
. (Hint: If a sieve is maximal, then it contains identity.) .
.  is a unique such natural transformation that completes the pullback:
is a unique such natural transformation that completes the pullback: making this diagram into a pullback. Let’s redraw the subfunctor condition for arrows, replacing
making this diagram into a pullback. Let’s redraw the subfunctor condition for arrows, replacing 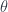 :
:
 . We’ll follow a set of equivalences.
. We’ll follow a set of equivalences. 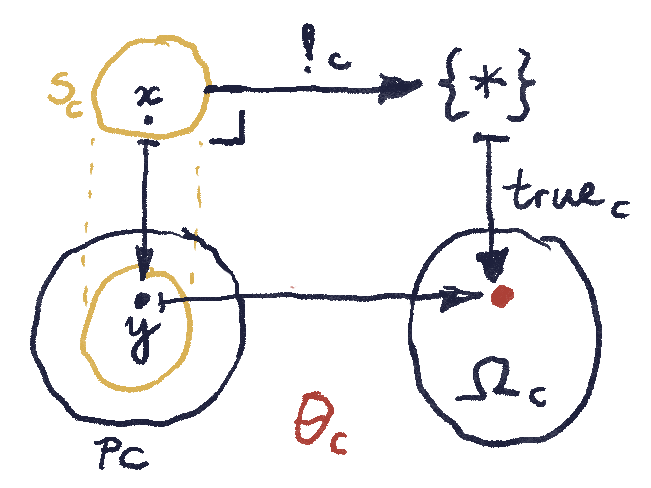
 is equivalent to
is equivalent to  . In other words:
. In other words:
 .
.  , acting on
, acting on  is a sieve defined by the following set of arrows:
is a sieve defined by the following set of arrows:
 is a maximal sieve, it must be that
is a maximal sieve, it must be that  .
. . Therefore
. Therefore  that maps objects to sieves, together with the natural transformation
that maps objects to sieves, together with the natural transformation  that picks maximal sieves.
that picks maximal sieves. , etc. The network of “happy” morphisms keeps growing outward. By contrast, the “unhappy” elements of
, etc. The network of “happy” morphisms keeps growing outward. By contrast, the “unhappy” elements of  is the terminal object (here, a singleton set). In principle we should insist that
is the terminal object (here, a singleton set). In principle we should insist that  is to provide an injective function
is to provide an injective function  that embeds
that embeds  then defines the subset of
then defines the subset of 
 . We do it by means of a universal construction. We postulate that: For every monic
. We do it by means of a universal construction. We postulate that: For every monic  between two arbitrary objects there exist a unique arrow
between two arbitrary objects there exist a unique arrow  ) we first create a set of pairs
) we first create a set of pairs  where
where  and
and  (the only element of the singleton set). But not all
(the only element of the singleton set). But not all  , where
, where  is the element of
is the element of  . This tells us that
. This tells us that 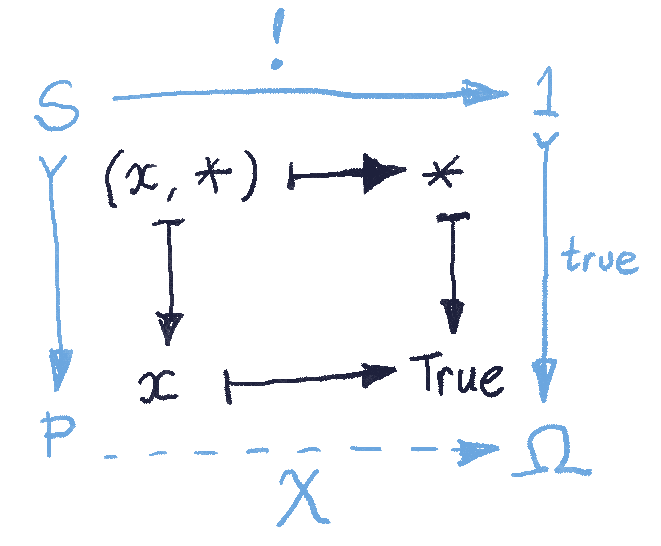
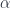 between two virtual objects corresponding to two presheaves
between two virtual objects corresponding to two presheaves  , seen as an arrow
, seen as an arrow  , we get an arrow
, we get an arrow  simply by composition
simply by composition  . Notice that we are thus defining the composition with
. Notice that we are thus defining the composition with  of a natural transformation is a mapping between two arrows.
of a natural transformation is a mapping between two arrows.
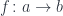 , consider a zigzag path from
, consider a zigzag path from  . The two ways of associating this composition give us
. The two ways of associating this composition give us  .
.
 is a bunch of arrows converging on
is a bunch of arrows converging on  , if we pick a compatible family of
, if we pick a compatible family of  that agrees on all overlaps, then this uniquely determines the element (virtual arrow)
that agrees on all overlaps, then this uniquely determines the element (virtual arrow)  .
.
 and all its open subsets (that is objects that have arrows pointing to
and all its open subsets (that is objects that have arrows pointing to  , even if they are not present in the original cover.
, even if they are not present in the original cover. . Indeed,
. Indeed,  maps all objects either to singletons or to empty sets. In terms of virtual arrows, there is at most one arrow going to
maps all objects either to singletons or to empty sets. In terms of virtual arrows, there is at most one arrow going to  .
.
 is automatically a compatible family. Therefore, if
is automatically a compatible family. Therefore, if  and the set
and the set  .
. and
and  .
.
 is a member of the hom-set
is a member of the hom-set  . Now consider the fact that
. Now consider the fact that  is a presheaf,
is a presheaf,  , and ask the question: Is a cover a “subfunctor” of
, and ask the question: Is a cover a “subfunctor” of  ,
,  is a subset of
is a subset of  and, for each arrow
and, for each arrow  , the function
, the function  is a restriction of
is a restriction of 
 is non-empty for any object
is non-empty for any object  ‘s.
‘s.
 connecting it to some element
connecting it to some element  of the cover. Functoriality requires the (virtual) composition
of the cover. Functoriality requires the (virtual) composition  to exist.
to exist.
 . A coverage assigns a collection of covers to every object, satisfying the sub-coverage conditions described in the previous post. A category with coverage is called a site.
. A coverage assigns a collection of covers to every object, satisfying the sub-coverage conditions described in the previous post. A category with coverage is called a site. , to our category. The set
, to our category. The set  .
.
 . The presheaf lifts it to a function between sets:
. The presheaf lifts it to a function between sets:  (contravariance means that the arrow is reversed). For any
(contravariance means that the arrow is reversed). For any  we can define the composition
we can define the composition 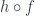 to be
to be  .
.
 that are in the cover of
that are in the cover of 
 . It’s as if the objects
. It’s as if the objects  a matching family, if this new covering respects the existing intersections. If
a matching family, if this new covering respects the existing intersections. If 
 ‘s intersect as covers of
‘s intersect as covers of  and every matching family
and every matching family 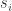 there exists a unique
there exists a unique  that factorizes those
that factorizes those 

 . If the family
. If the family  should form a cover of
should form a cover of 
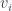 ‘s are automatically open. And if no part of
‘s are automatically open. And if no part of 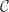 assigns to each object
assigns to each object 
 , and every object
, and every object  , there exist a covering family
, there exist a covering family  that is a sub-family of
that is a sub-family of 
 we can find its “parent”
we can find its “parent”  can be factored through some
can be factored through some 

 as explained in detail in the previous post:
as explained in detail in the previous post: , abstracting the idea of assigning a set of functions to every open set (an object of
, abstracting the idea of assigning a set of functions to every open set (an object of  , such that for every
, such that for every  and
and  , such that
, such that  , we have:
, we have:

 such that
such that  for all
for all 
 but a category with some additional structure. This makes sense, because the set of functions defined over an open set has usually more structure. It’s the structure induced by the target of these functions. For instance real- or complex-valued functions can be added, subtracted, and multiplied–point-wise. Division of functions is not well defined because of zeros, so they only form a ring.
but a category with some additional structure. This makes sense, because the set of functions defined over an open set has usually more structure. It’s the structure induced by the target of these functions. For instance real- or complex-valued functions can be added, subtracted, and multiplied–point-wise. Division of functions is not well defined because of zeros, so they only form a ring.
