Functors from a monoidal category C to Set form a monoidal category with Day convolution as product. A monoid in this category is a lax monoidal functor. We define an initial algebra using a higher order functor and show that it corresponds to a free lax monoidal functor.
Recently I’ve been obsessing over monoidal functors. I have already written two blog posts, one about free monoidal functors and one about free monoidal profunctors. I followed some ideas from category theory but, being a programmer, I leaned more towards writing code than being preoccupied with mathematical rigor. That left me longing for more elegant proofs of the kind I’ve seen in mathematical literature.
I believe that there isn’t that much difference between programming and math. There is a whole spectrum of abstractions ranging from assembly language, weakly typed languages, strongly typed languages, functional programming, set theory, type theory, category theory, and homotopy type theory. Each language comes with its own bag of tricks. Even within one language one starts with some relatively low level encodings and, with experience, progresses towards higher abstractions. I’ve seen it in Haskell, where I started by hand coding recursive functions, only to realize that I can be more productive using bulk operations on types, then building recursive data structures and applying recursive schemes, eventually diving into categories of functors and profunctors.
I’ve been collecting my own bag of mathematical tricks, mostly by reading papers and, more recently, talking to mathematicians. I’ve found that mathematicians are happy to share their knowledge even with outsiders like me. So when I got stuck trying to clean up my monoidal functor code, I reached out to Emily Riehl, who forwarded my query to Alexander Campbell from the Centre for Australian Category Theory. Alex’s answer was a very elegant proof of what I was clumsily trying to show in my previous posts. In this blog post I will explain his approach. I should also mention that most of the results presented in this post have already been covered in a comprehensive paper by Rivas and Jaskelioff, Notions of Computation as Monoids.
Lax Monoidal Functors
To properly state the problem, I’ll have to start with a lot of preliminaries. This will require some prior knowledge of category theory, all within the scope of my blog/book.
We start with a monoidal category 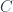


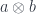




These isomorphisms are called, respectively, the left and right unitors, and the associator.
The most familiar example of a monoidal category is the category of types and functions, in which the tensor product is the cartesian product (pair type) and the unit is the unit type ().
Let’s now consider functors from 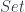
![[C, Set]](https://s0.wp.com/latex.php?latex=%5BC%2C+Set%5D&bg=ffffff&fg=29303b&s=0&c=20201002)
In Haskell, a natural transformation is approximated by a polymorphic function:
type f ~> g = forall x. f x -> g x
The category 

We are interested in functors in 

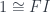
We are interested in a weaker version of a monoidal functor called lax monoidal functor, which is equipped with a one-way natural transformation:
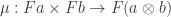
and a one-way morphism:

A lax monoidal functor must also preserve unit and associativity laws.

Associativity law: 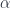


In Haskell, a lax monoidal functor can be defined as:
class Monoidal f where eta :: () -> f () mu :: (f a, f b) -> f (a, b)
It’s also known as the applicative functor.
Day Convolution and Monoidal Functors
It turns out that our category of functors 

Here, 


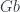
In Haskell, a coend corresponds to an existential type, so the Day convolution can be defined as:
data Day f g c where Day :: ((a, b) -> c, f a, g b) -> Day f g c
(The actual definition uses currying.)
The unit with respect to Day convolution is the hom-functor:
which assigns to every object 
The proof that this is the unit is instructive, as it uses the standard trick: the co-Yoneda lemma. In the coend form, the co-Yoneda lemma reads, for a covariant functor

and for a contravariant functor 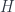

(The mnemonics is that the integration variable must appear twice, once in the negative, and once in the positive position. An argument to a contravariant functor is in a negative position.)
Indeed, substituting 

which can be “integrated” over

and, since 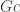
To summarize, we are dealing with three monoidal categories:
A Monoid in [C, Set]
A monoidal category can be used to define monoids. A monoid is an object 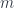



These morphisms must satisfy unit and associativity conditions, which are best illustrated using commuting diagrams.

Unit laws. λ and ρ are the unitors.

Associativity law: α is the associator.
This definition of a monoid can be translated directly to Haskell:
class Monoid m where eta :: () -> m mu :: (m, m) -> m
It so happens that a lax monoidal functor is exactly a monoid in our functor category


At first sight, these don’t look like the morphisms in the definition of a lax monoidal functor. We need some new tricks to show the equivalence.
Let’s start with the unit. The first trick is to consider not one natural transformation but the whole hom-set:
, F)](https://s0.wp.com/latex.php?latex=%5BC%2C+Set%5D%28C%28I%2C+-%29%2C+F%29&bg=ffffff&fg=29303b&s=0&c=20201002)
The set of natural transformations can be represented as an end (which, incidentally, corresponds to the forall quantifier in the Haskell definition of natural transformations):

The next trick is to use the Yoneda lemma which, in the end form reads:

In more familiar terms, this formula asserts that the set of natural transformations from the hom-functor 
There is also a version of the Yoneda lemma for contravariant functors:

The application of Yoneda to our formula produces 

We can use the same trick of bundling up natural transformations that define multiplication 
](https://s0.wp.com/latex.php?latex=%5BC%2C+Set%5D%28F+%5Cstar+F%2C+F%29&bg=ffffff&fg=29303b&s=0&c=20201002)
and representing this set as an end over the hom-functor:

Expanding the definition of Day convolution, we get:
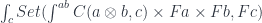
The next trick is to pull the coend out of the hom-set. This trick relies on the co-continuity of the hom-functor in the first argument: a hom-functor from a colimit is isomorphic to a limit of hom-functors. In programmer-speak: a function from a sum type is equivalent to a product of functions (we call it case analysis). A coend is a generalized colimit, so when we pull it out of a hom-functor, it turns into a limit, or an end. Here’s the general formula, in which 

Let’s apply it to our formula:

We can combine the ends under one integral sign (it’s allowed by the Fubini theorem) and move to the next trick: hom-set adjunction:

In programming this is known as currying. This adjunction exists because 
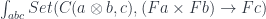
Using the Yoneda lemma we can “perform the integration” over

This is exactly the set of natural transformations used in the definition of a lax monoidal functor. We have established one-to-one correspondence between monoidal multiplication and lax monoidal mapping.
Of course, a complete proof would require translating monoid laws to their lax monoidal counterparts. You can find more details in Rivas and Jaskelioff, Notions of Computation as Monoids.
We’ll use the fact that a monoid in the category
Alternative Derivation
Incidentally, there are shorter derivations of these formulas that use the trick borrowed from the proof of the Yoneda lemma, namely, evaluating things at the identity morphism. (Whenever mathematicians speak of Yoneda-like arguments, this is what they mean.)
Starting from 

There is a component of this natural transformation at 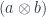
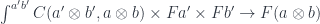
This morphism must be defined for all possible values of the coend. In particular, it must be defined for the triple 
There is also an alternative derivation for the unit: Take the component of the natural transformation 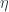


Free Monoid
Given a monoidal category 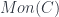
Consider, for instance, two monoids 



and similarly for multiplication:

Remember, we assumed that the tensor product is functorial in both arguments, so it can be used to lift a pair of morphisms.

There is an obvious forgetful functor 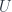
The left adjoint to this functor, if it exists, will map an object 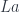
The intuition is that a free monoid
In Haskell, a list is defined recursively:
data List a = Nil | Cons a (List a)
Such a recursive definition can be formalized as a fixed point of a functor. For a list of a, this functor is:
data ListF a x = NilF | ConsF a x
Notice the peculiar structure of this functor. It’s a sum type: The first part is a singleton, which is isomorphic to the unit type (). The second part is a product of a and x. Since the unit type is the unit of the product in our monoidal category of types, we can rewrite this functor symbolically as:
It turns out that this formula works in any monoidal category that has finite coproducts (sums) that are preserved by the tensor product. The fixed point of this functor is the free functor that generates free monoids.
I’ll define what is meant by the fixed point and prove that it defines a monoid. The proof that it’s the result of a free/forgetful adjunction is a bit involved, so I’ll leave it for a future blog post.
Algebras
Let’s consider algebras for the functor 

called the structure map or the evaluator.
In Haskell, an algebra is defined as:
type Algebra f x = f x -> x
There may be a lot of algebras for a given functor. In fact there is a whole category of them. We define an algebra morphism between two algebras 

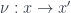
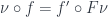

The initial object in the category of algebras is called the initial algebra, or the fixed point of the functor that generates these algebras. As the initial object, it has a unique algebra morphism to any other algebra. This unique morphism is called a catamorphism.
In Haskell, the fixed point of a functor f is defined recursively:
newtype Fix f = In { out :: f (Fix f) }
with, for instance:
type List a = Fix (ListF a)
A catamorphism is defined as:
cata :: Functor f => Algebra f a -> Fix f -> a cata alg = alg . fmap (cata alg) . out
A list catamorphism is called foldr.
We want to show that the initial algebra
is a free monoid. Let’s see under what conditions it is a monoid.
Initial Algebra is a Monoid
In this section I will show you how to concatenate lists the hard way.
We know that function type 
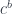
The function type is also called the internal hom.
In a monoidal category it’s sometimes possible to define an internal hom-object, denoted ![[b, c]](https://s0.wp.com/latex.php?latex=%5Bb%2C+c%5D&bg=ffffff&fg=29303b&s=0&c=20201002)
![curry : C(a \otimes b, c) \cong C(a, [b, c])](https://s0.wp.com/latex.php?latex=curry+%3A+C%28a+%5Cotimes+b%2C+c%29+%5Ccong+C%28a%2C+%5Bb%2C+c%5D%29&bg=ffffff&fg=29303b&s=0&c=20201002)
If this adjoint exists, the category is called closed monoidal.
In a closed monoidal category, the initial algebra 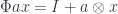
a, which is a fixed point of ListF a, is a monoid.)
To show that, we have to construct two morphisms corresponding to unit and multiplication (in Haskell, empty list and concatenation):

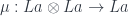
What we know is that 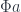
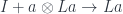
which is equivalent to a pair of morphisms:

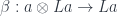
Notice that, in Haskell, these correspond the two list constructors: Nil and Cons or, in terms of the fixed point:
nil :: () -> List a nil () = In NilF cons :: a -> List a -> List a cons a as = In (ConsF a as)
We can immediately use
The second one, 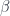

Notice that, if we could prove that ![[L a, L a]](https://s0.wp.com/latex.php?latex=%5BL+a%2C+L+a%5D&bg=ffffff&fg=29303b&s=0&c=20201002)
![\kappa_{[L a, L a]} : L a \to [L a, L a]](https://s0.wp.com/latex.php?latex=%5Ckappa_%7B%5BL+a%2C+L+a%5D%7D+%3A+L+a+%5Cto+%5BL+a%2C+L+a%5D&bg=ffffff&fg=29303b&s=0&c=20201002)
which, by the hom adjunction, would give us the desired multiplication:
Let’s establish some useful lemmas first.
Lemma 1: For any object ![[x, x]](https://s0.wp.com/latex.php?latex=%5Bx%2C+x%5D&bg=ffffff&fg=29303b&s=0&c=20201002)
This is a generalization of the idea that endomorphisms form a monoid, in which identity morphism is the unit and composition is multiplication. Here, the internal hom-object
Proof: The unit:
![\eta : I \to [x, x]](https://s0.wp.com/latex.php?latex=%5Ceta+%3A+I+%5Cto+%5Bx%2C+x%5D&bg=ffffff&fg=29303b&s=0&c=20201002)
follows, through adjunction, from the unit law in the monoidal category:

(In Haskell, this is a fancy way of writing mempty = id.)
Multiplication takes the form:
![\mu : [x, x] \otimes [x, x] \to [x, x]](https://s0.wp.com/latex.php?latex=%5Cmu+%3A+%5Bx%2C+x%5D+%5Cotimes+%5Bx%2C+x%5D+%5Cto+%5Bx%2C+x%5D&bg=ffffff&fg=29303b&s=0&c=20201002)
which is reminiscent of composition of edomorphisms. In Haskell we would say:
mappend = (.)
By adjunction, we get:
![curry^{-1} \, \mu : [x, x] \otimes [x, x] \otimes x \to x](https://s0.wp.com/latex.php?latex=curry%5E%7B-1%7D+%5C%2C+%5Cmu+%3A+%5Bx%2C+x%5D+%5Cotimes+%5Bx%2C+x%5D+%5Cotimes+x+%5Cto+x&bg=ffffff&fg=29303b&s=0&c=20201002)
We have at our disposal the counit 
![eval : [x, x] \otimes x \cong x](https://s0.wp.com/latex.php?latex=eval+%3A+%5Bx%2C+x%5D+%5Cotimes+x+%5Ccong+x&bg=ffffff&fg=29303b&s=0&c=20201002)
We can apply it twice to get:
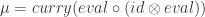
In Haskell, we could express this as:
mu :: ((x -> x), (x -> x)) -> (x -> x) mu (f, g) = \x -> f (g x)
Here, the counit of the adjunction turns into simple function application.

Lemma 2: For every morphism 
Proof: Since
To show that
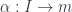
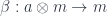
The first one is the same as
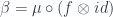
In Haskell, we would do case analysis:
mapAlg :: Monoid m => ListF a m -> m mapAlg NilF = mempty mapAlg (ConsF a m) = f a `mappend` m
We can now build a larger proof. By lemma 1,
We also have a morphism ![\bar{\beta} : a \to [L a, L a]](https://s0.wp.com/latex.php?latex=%5Cbar%7B%5Cbeta%7D+%3A+a+%5Cto+%5BL+a%2C+L+a%5D&bg=ffffff&fg=29303b&s=0&c=20201002)


It follows that there is a unique catamorphism ![\kappa_{[L a, L a]}](https://s0.wp.com/latex.php?latex=%5Ckappa_%7B%5BL+a%2C+L+a%5D%7D&bg=ffffff&fg=29303b&s=0&c=20201002)
Translating this to Haskell, 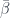
Cons and what we have shown is that concatenation (multiplication of lists) can be implemented as a catamorphism:
concat :: List a -> List a -> List a
conc x y = cata alg x y
where alg NilF = id
alg (ConsF a t) = (cons a) . t
The type:
List a -> (List a -> List a)
(parentheses added for emphasis) corresponds to ![L a \to [L a, L a]](https://s0.wp.com/latex.php?latex=L+a+%5Cto+%5BL+a%2C+L+a%5D&bg=ffffff&fg=29303b&s=0&c=20201002)
It’s interesting that concatenation can be described in terms of the monoid of list endomorphisms. Think of turning an element a of the list into a transformation, which prepends this element to its argument (that’s what 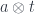
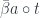
Incidentally, lemma 2 also works in reverse: If a monoid
Proof: if 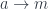
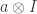

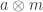

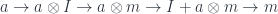

In Haskell, this corresponds to a construction and evaluation of:
ConsF a mempty
Free Monoidal Functor
Let’s go back to our functor category. We started with a monoidal category
The next step is to build a free monoid in
Our construction relied on defining an initial algebra for the functor:

Straightforward translation of this formula to the functor category

It defines, for any functor 
We can now use 
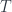
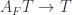
The initial algebra for this higher-order endofunctor defines a monoid, and therefore a lax monoidal functor. We have shown it for an arbitrary closed monoidal category. So the only question is whether our functor category with Day convolution is closed.
We want to define the internal hom-object in
 \cong [C, Set](F, [G, H])](https://s0.wp.com/latex.php?latex=%5BC%2C+Set%5D%28F+%5Cstar+G%2C+H%29+%5Ccong+%5BC%2C+Set%5D%28F%2C+%5BG%2C+H%5D%29&bg=ffffff&fg=29303b&s=0&c=20201002)
We start with the set of natural transformations — the hom-set in
](https://s0.wp.com/latex.php?latex=%5BC%2C+Set%5D%28F+%5Cstar+G%2C+H%29&bg=ffffff&fg=29303b&s=0&c=20201002)
We rewrite it as an end over

We use the co-continuity trick to pull the coend out of the hom-set and turn it into an end:

Keeping in mind that our goal is to end up with

The hom-functor is continuous in the second argument, so we can sneak the end over 

We end up with a set of natural transformations from the functor
![[G, H] = \int_{b c} (C(- \otimes b, c) \times G b \to H c)](https://s0.wp.com/latex.php?latex=%5BG%2C+H%5D+%3D+%5Cint_%7Bb+c%7D+%28C%28-+%5Cotimes+b%2C+c%29+%5Ctimes+G+b+%5Cto+H+c%29&bg=ffffff&fg=29303b&s=0&c=20201002)
We therefore identify this functor as the right adjoint (internal hom-object) for Day convolution. We can further simplify it by using the hom-set adjunction:

and applying the Yoneda lemma to get:
![[G, H] = \int_{b} (G b \to H (- \otimes b))](https://s0.wp.com/latex.php?latex=%5BG%2C+H%5D+%3D+%5Cint_%7Bb%7D+%28G+b+%5Cto+H+%28-+%5Cotimes+b%29%29&bg=ffffff&fg=29303b&s=0&c=20201002)
In Haskell, we would write it as:
newtype DayHom f g a = DayHom (forall b . f b -> g (a, b))
Since Day convolution has a right adjoint, we conclude that the fixed point of our higher order functor defines a free lax monoidal functor. We can write it in a recursive form as:

or, in Haskell:
data FreeMonR f t =
Done t
| More (Day f (FreeMonR f) t)
Free Monad
This blog post wouldn’t be complete without mentioning that the same construction works for monads. Famously, a monad is a monoid in the category of endofunctors. Endofunctors form a monoidal category with functor composition as tensor product and the identity functor as unit. The fact that we can construct a free monad using the formula:
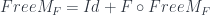
is due to the observation that functor composition has a right adjoint, which is the right Kan extension. Unfortunately, due to size issues, this Kan extension doesn’t always exist. I’ll quote Alex Campbell here: “By making suitable size restrictions, we can give conditions for free monads to exist: for example, free monads exist for accessible endofunctors on locally presentable categories; a special case is that free monads exist for finitary endofunctors on 
Conclusion
As we acquire experience in programming, we learn more tricks of trade. A seasoned programmer knows how to read a file, parse its contents, or sort an array. In category theory we use a different bag of tricks. We bunch morphisms into hom-sets, move ends and coends, use Yoneda to “integrate,” use adjunctions to shuffle things around, and use initial algebras to define recursive types.
Results derived in category theory can be translated to definitions of functions or data structures in programming languages. A lax monoidal functor becomes an Applicative. Free monoidal functor becomes:
data FreeMonR f t =
Done t
| More (Day f (FreeMonR f) t)
What’s more, since the derivation made very few assumptions about the category 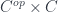
data FreeMon p s t where
DoneFM :: t -> FreeMon p s t
MoreFM :: p a b -> FreeMon p c d ->
(b -> d -> t) ->
(s -> (a, c)) -> FreeMon p s t
Replacing Day convolution with endofunctor composition gives us a free monad:
data FreeMonadF f g a =
DoneFM a
| MoreFM (Compose f g a)
Category theory is also the source of laws (commuting diagrams) that can be used in equational reasoning to verify the correctness of programming constructs.
Writing this post has been a great learning experience. Every time I got stuck, I would ask Alex for help, and he would immediately come up with yet another algebra and yet another catamorphism. This was so different from the approach I would normally take, which would be to get bogged down in inductive proofs over recursive data structures.
May 18, 2018 at 12:34 am
In the associativity law diagram:
But in the diagram \alpha is associating Fa x (Fb x Fc) with (Fa x Fb) x Fc so it is the associativity of the cartesian product of Sets, isn’t it? So the top arrow associator (which is in Set) cannot be \alpha.
Well, or I can be completely wrong 😀
Juan Manuel
May 18, 2018 at 10:26 am
What I meant was that these are two different alphas. In programming, we are used to overloading names.
May 18, 2018 at 11:52 am
Thank you! While reading it, I figured you can as well draw images on my presheaf:
May 18, 2018 at 3:07 pm
Sorry, not sure if my previous comment got through.
I see you draw diagrams with your hand; but you can use my presheaf.com, like this:
May 18, 2018 at 3:09 pm
(wordpress problems) I mean, http://presheaf.com/?d=d5z5zq1731w475o691s194s6s4t4s
May 18, 2018 at 5:21 pm
@Vlad: For some reason, whatever you’re trying to embed, doesn’t pass through wordpress. I had a look at your website and the documentation. It is a little intimidating. It would be nice to have a wysiwyg application.
May 22, 2018 at 10:02 pm
Hi Bartosz, I like the conclusion. How the same construction can produce a monad helped to complete the picture. I’m a little unclear of the significance of Lax (Applicative) being a one-way arrow because it only needs to consider
the monoidal structure (I’m assuming you’re referring to the Functor layer in
m aorf a). The reason I’m unclear is because I’m having a tough time imagining any meaningful monoidal computation where we don’t loose information once we combine the two Functor values to produce the single result value (3 + 1 -> 4, but I can’t map a 1:1 solution of 1 and 3 from 4). So I get that we don’t have an isomorphism because we cannot define a valid reverse function. Can I say the same thing for monoidal computation embedded in the monad? I’m getting the impression from the blog the answer is, no. That would mean that everym bin the range of thek :: a -> m bhas the information required to reproduce them avalue in the domain. There seems to be something missing in the constraints for that to be true. I assume that has to do with what Alex described.But more concretely, take for example a
kthat generatesNothingin one of two situations, in one of 2 values ofa(say 0 and 1 wherea :: Int). If the value ofm bends up beingNothingI can’t say which of the two possibleavalues, 0 or 1, produced theNothingresult. Does what Alex describe explain/constrain for this possibility? Furthermore, I can’t even determine if theNothingwas produced by themvalue in them aor was it from the return value ofkin thebindoperation. Categorically the monad could be behaving like Applicative in that it is propagatingNothing, not actually runningkbecause there is noa. Alternatively, it could behave like a monad where theNothingwas the result of the new, dominantmvalue generated byk, distinctively monadic. But even then, it’s not isomorphic in the example I gave. Applicative generates the same monoidal result except will apply thef acomputations regardless, and wherefcannot change value. But similarly, once I perform the monoidal join of the multiplefvalues there is no way to reproduce, or map back to the inputs.There is only one scenario I can imagine where the monad is isomorphic: If the interaction or the product of
m bis unique for every combination ofmanda. That is a pretty high bar to have to meet. In other words, rare. In statistics there is a precise understanding of the term interaction. If present, the model cannot predict the change in the value ofywithout knowing the absolute values of both factors where an interaction was demonstrated.For instance is we wanted to know, on average, did the medication improve the health of the patients? If you can answer “yes”, and be correct the same “number of times” whether you are describing old versus young, big versus small, male versus female, married versus single etc., then there is no interaction. On the other hand, if you have to answer the question with “it depends on what patient group”, then you have an interaction; e.g., patients with long curly hair had improved health, but those with short blonde hair did not experience a change in the course of the disease compared to controls, then we have an interaction
treatment success * hair colorthat explains the range of responses to treatment. When there is an interaction, the only way to predict the average treatment response (the delta) is if we know both which patients were treated And their hair style; only with that additional information will we know the effectiveness of the treatment. That’s bad news for marketing being able to tell a simple story, but good news for evidence of an isomorphism; I can tell you who was treated and their hairstyle based on the response to treatment.In statistics a group of individuals is a single value in our set; a collection of people becomes a distinct data point, a distinct group when the average of that group is statistically different than the average of some other collection of people. In the interaction scenario I described, I need 2 arrows to represent the two functions that once composed, encode the findings (one to represent the treatment effect, the other to encode the interaction). What is special about an interaction, is that if we only applied one of the functions, we end up in a place that does not actually exist, was never demonstrated statistically. If on the other hand, on average everyone responded the same, positive way to the medication, I would only need 1 arrow to connect the untreated and treated patients; the transformation encoded in the body of the arrow is the treatment effect. But if all I knew is that the patient responded well to the medication, I cannot tell you anything about the person’s hair; that encoding is lost where the interaction does not exist.
All this to say,
k :: a -> m bis required in our programming designs when we cannot express, when there is literally no way of representingbwithoutmto represent anything that is useful. If this is the case, there is an interaction betweenmandbthat is encoded, informed in the body ofkgiven the values ofmandainm a. The body := the biology of the medication that for some crazy reason cares about hair style, themandaencode whether the person was treated, and the style of the patient’s hair.I have not read a better explanation of the relationships you described in your blog post. This said, as close as you have gotten, the Categorical explanations of Applicative compared to Monad for instance, should somehow be able to capture this concept of interaction; how dependent is our abstraction on the simultaneous expression of
manda. FP and Haskell in particular, delivers on the capacity of computing with limited reliance on state. Managing state is expensive but mentally easy.One last area where Category seems to fall short: the type signatures are sometimes a by-product of a technicality as opposed to reflecting a Categorical intent (e.g.,
fmapforF f,returnas a natural transformation). It just so happens that withbindwe see how we cannot start computingkuntil we have completedm a(often, but by no means a requirement, the result of the previousk0; it could have been produce using unit/return); as such, one could argue, by happenstance, this monadic feature is represented in our Categorical drawings. But, this often sited monadic quality, is similar in many regards tof agiven how we rarely operate onf abut rather require that we first extractafromf abefore delegating the application of a lifted function to fmap (we are not required to delegation application in Applicative tofmap, it just clarifies the “one in the same” tasks shared betweenfmapand(<*>).When I first heard you lecture on YouTube about five years ago now, I was truly impressed with your imagination and capacity to tie together what seemed like disparate concepts. Category still has gaps for how we need this tool in computing. Are there new rules and encodings that you can conceive of and can start using? I’m talking about Categorical tools not bound by the limits of the original intent to solving problems in Physics and Calculus? A Categorical approach that captures what we experience and know to be foundational in how we imagine, conceive and deploy our ideas and intellect in Haskell? Can we build a Categorical approach that will facilitate getting us to a place where for instance, Ed Kmett got to when he conceived and implemented the elegance and power of Lenses? If it’s possible, Bartosz, you are on your way to doing it. Keep pushing!
- E
June 18, 2018 at 9:14 am
is there a categorical construction to generalize arrow composition,
by allowing domain and codomain to be refined (or changed) by the
composition ?
this construction would be useful for
forming theoretical background of dependent type system.
for example, compose two functions
f : (A x -> B y)
g : (B n -> C z)
will give us a function of type (A n -> C z)
another example would be the following generalized composition in cartesian closed category :
and
xieyuheng
June 18, 2018 at 12:57 pm
The standard categorical interpretation of dependent type systems is done using fibrations. There is also a generalization of a category that involves morphisms that have multiple sources (multiple targets are easy to encode using products). It’s called an operad.
July 10, 2018 at 12:12 am
[…] Free monoidal functors, categorically! ~ Bartosz Milewski (@BartoszMilewski) #haskell #CategoryTheory […]
July 17, 2018 at 1:35 am
Thank you professor, Thanks for your reply.
I apologize to post offtopic comments here,
because I read your book and wish to learn more from you,
but I do not know how to contact you otherwise.
I am trying to provide a categorical model of dependent type systems,
by using what I learned from “What is Unification?” — a paper by Joseph A. Goguen,
i.e. to use equalizer to define unification,
and when
Bis unified withCin(A -> B) and (C -> D),using pullback and pushout to apply the equalizer to
AandD.Also I have a project proposal here :: https://xieyuheng.github.io/cicada
July 17, 2018 at 11:16 am
Have you looked at the Idris language? Also, Agda and Coq are two very mathematical languages worth studying.
July 17, 2018 at 11:46 am
Yes, I have.
In Idris and Agda, to model category theory,
record-type is needed (for its first-class-ness),
but record-type in them are not inheritable, and not easy to use.
I tried myself
https://github.com/xieyuheng/pure/blob/master/category.agda
https://github.com/xieyuheng/idris-category/blob/master/Category.idr
And I read a lot (all that i can find) about how other people formalize category theory in Idris, Agda and Coq.
I am not satisfied with those languages, for very concrete reasons.
July 17, 2018 at 1:30 pm
I am using partly inhabited typed record as type,
and fully inhabited typed record inhabits such type.
Let’s call it fulfilling type system.
This allows types to be used in a more flexible way,
and makes sub-type relation easily expressed.