Previously: Identity Types.
Let me first explain why the naive categorical model of dependent types doesn’t work very well for identity types. The problem is that, in such a model, any arrow can be considered a fibration, and therefore interpreted as a dependent type. In our definition of path induction, with an arrow 
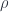

So we are free to substitute 

We are guaranteed that there is a unique 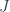



This is not satisfactory from the point of homotopy type theory, since the existence of non-trivial paths is necessary to make sense of things like higher inductive types (HITs) or univalence. If we want to model dependent types as fibrations, we cannot allow
The solution is to apply the lessons from topology, in particular homotopy. Recall that maps between topological spaces can be characterized as fibrations, cofibrations, and homotopy equivalences. There usually are overlaps between these three categories.
A fibration that is also an equivalence is called a trivial fibration or an acyclic fibration. Similarly, we have trivial (acyclic) cofibrations. We’ve also seen that, roughly speaking, cofibrations generalize injections. So, if we want a non-trivial model of identity types, it makes sense to model 

We know what a path is in a topological space 




In a category that supports a factorization system, we can tighten this definition by requiring that 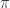
The intuition behind this diagram is that
Compare this with the diagram that illustrates the introduction rule for the identity type:

We want
Thus the existence of very good path objects takes care of the introduction rule for identity types.
The elimination rule is harder to wrap our minds around. How is it possible that any mapping that is defined on trivial paths, which are given by 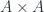
We might take a hint from complex analysis, where we can uniquely define analytic continuations of real function.
In topology, our continuations are restricted by continuity. When you are lifting a path in 
You can visualize building 




A more abstract way of putting it is that identity types are path spaces in some factorization system, and dependent types over them are fibrations that satisfy the lifting property. Any path from 
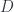

This is exactly the property illustrated by the lifting diaram, in which paths are elements of the identity type
This time
The general framework, in which to build models of homotopy type theory is called a Quillen model category, which was originally used to model homotopies in topological spaces. It can be described as a weak factorization system, in which any morphism can be written as a trivial cofibration followed by a fibration. It must satisfy the unique lifting property for any square in which 

The full definition of a model category has more moving parts, but this is the gist of it.
We model dependent types as fibrations in a model category. We construct path objects as factorizations of the diagonal, and this lets us define non-trivial identity types.
One of the consequences of the fact that there could be multiple identity paths between two points is that we can, in turn, compare these paths for equality. There is, for instance, an identity type of identity types 
 is equal to
is equal to  . This is called definitional equality, since it’s just part of the definition. However, if we reverse the order of the addends and try to prove
. This is called definitional equality, since it’s just part of the definition. However, if we reverse the order of the addends and try to prove  , there is no obvious shortcut. We have to prove it the hard way! This second type of equality is called propositional.
, there is no obvious shortcut. We have to prove it the hard way! This second type of equality is called propositional.
 written as
written as  , or even
, or even  , if the type
, if the type 
 . Here,
. Here,  (type of equality of proofs of equality), and so on, ad infinitum. This used to be a bane of Martin Löf type theory, but it became a bounty for Homotopy Type Theory. So let’s imagine that the identity type may have non-trivial inhabitants. We’ll call these inhabitants paths. The trivial paths generated by
(type of equality of proofs of equality), and so on, ad infinitum. This used to be a bane of Martin Löf type theory, but it became a bounty for Homotopy Type Theory. So let’s imagine that the identity type may have non-trivial inhabitants. We’ll call these inhabitants paths. The trivial paths generated by  to some type
to some type  and
and 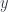 :
:

 , so it’s enough to specify how
, so it’s enough to specify how 
 and
and  . Except that here we have a whole family of constructors
. Except that here we have a whole family of constructors 

 . When projected down to
. When projected down to  , so we have:
, so we have:

 that maps
that maps  . So, when projected back to
. So, when projected back to 


 . The section condition is:
. The section condition is:


