In category theory, as in life, you spend half of your time trying to forget things, and half of the time trying to recover them. A morphism, the basic building block of every category, is like a defective isomorphism. It maps the initial state to the final state, but it provides no guarantees that you can recover the original. But it seems like this lossiness is what makes morphisms useful.
There are people who can memorize mathematical formulas perfectly but have no idea what they mean. And there are those who get just the gist of it, but can derive the rest when needed. Somehow understanding is related to lossy compression.
We can’t recover lost information. Once it’s gone, it’s gone. All we can do is to try to figure out what the original might have been like. In fact, knowing how the information was lost, we might be able to generate all possible inputs that could have led to a given output. It’s the closest we can get to inverting the uninvertible. This is the main idea behind fibrations.
Let me illustrate this concept with an example. Consider the function isEven:
isEven :: Integer -> Bool isEven n = n `mod` 2 == 0
This function is definitely not invertible. If I only told you that the output was True, you couldn’t tell me what the input was. You could, however, give me the set of all inputs that could have produced this output: it’s the set of even numbers. We often call this set, which is the inverse image of True, a fiber over True. Similarly, the fiber over False is the set of odd numbers. In this case we only have only two fibers and they happen to be isomorphic.
Here’s a more interesting example. Consider a set of all lists of integers and a function that returns the length of a list: a natural number:
length :: [Integer] -> Nat
This function is not invertible, but it defines fibers over natural numbers. The fiber over zero is a one-element set that contains only the empty list. The fiber over 1 is the set of lists of length one (which is isomorphic to the set of integers). The fiber over 2 is a set of 2-element lists, or pairs of integers, and so on. You may recognize these fibers as length-indexed lists, or vectors. You can find them, for instance, in the Haskell Vec library or as Vect in Idris. These are not your typical data types, though. They are examples of dependent types–types that depend on values (here, natural numbers).
Notice that the name “length-indexed lists” suggests a slightly different interpretation of these types. You may think of them as families of types parameterized by natural numbers. This would suggest a mapping from elements of a set (natural numbers) to types. These two views are equivalent, but in category theory we try to avoid, if possible, talking about sets (and set elements in particular). The interpretation of dependent types as fibrations is more general, so let’s dig into fibrations.
As a generalization of functions like isEven or length, we’ll consider a morphism 



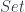
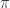




Fig. 1.
(The exclamation mark stands for the unique morphism to the terminal object.) Incidentally, this is why a pullback is sometimes called a fiber product.
If fibers over all elements 
Anything you can do with functions, you can do with functors, only better. So we can have a category 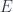

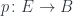

Here’s the idea: We would like each fiber to form a subcategory of 
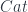
The starting point of Grothendieck fibration is the recipe for lifting morphisms from the base category
Let’s start with a morphism 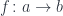


The opcartesian morphism over 



Fig. 2.
It must satisfy a universal property that I’m about to describe.
First, we pick an arbitrary object 

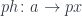

Fig. 3.
We are interested in the case when 



Fig. 4.
In other words, there exists a unique 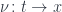

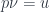
If you find this definition a little confusing, you’re in good company. So let’s try a slightly different imagery that has more to do with the original ideas from algebraic topology. Think of objects as shapes. A morphism 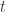

Now suppose that this shadow falls inside the smaller

Fig. 5.
Normally, this would not imply that
Now that we know what an opcartesian morphism is, we might ask the question, does it always exist? Given an arbitrary morphism 
Here’s an interesting observation. You might wonder whether the definition of an opcartesian morphism isn’t overly complicated. Wouldn’t it be enough to restrict the pool of possible candidates to those morphisms whose target, the
Given an opfibration, we now face the opposite problem: there may be too many opcartesian morphisms. Remember, we wanted to (a) make fibers into subcategories of 


But in general we have more than one opcartesian morphism between a source object in one fiber and candidate target objects in the other fiber. But we can design a procedure to pick one (if you’re into set theory, you’ll notice that we have to use the Axiom of Choice). Such choice is called an opcleavage, and the resulting construction is called cloven opfibration.
Formally, an opcleavage is described by a function


Fig. 6.
It takes a morphism 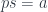

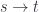
The universal construction of opcartesian morphisms can then be used to define the mapping of vertical morphisms thus completing the definition of a functor between fibers.
A geometric intuition is that an opcleavage provides a way of transporting objects in the horizontal direction. Vertical morphisms transport objects vertically, and the functors defined by the opcleavage transport them horizontally, in such a way that their shadows follow the arrows in the base. The origin of this intuition goes back to differential geometry, where one is able to define continuous paths in the base manifold and use them to transport objects, such as vectors, between fibers. Category theory lets us abstract away continuity (and differentiability) from this picture. You might also see transport used in homotopy type theory, with paths standing for equality proofs.
Now, remember what I said about the composition of opcartesian morphisms resulting in an opcartesian morphism? Unfortunately, once we start picking individual morphisms to construct an opcleavage, this compositionality might be lost. The composition of any two morphisms from the selected pool is still opcartesian, but it’s not necessarily part of the opcleveage. This is why we might have to relax compositionality and embrace pseudofunctors.
But sometimes an opcleavage preserves compositionality. We call this situation split opfibration. It must satisfy these two conditions:
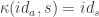

for any 
A split opfibration defines a functor 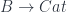
If the splitting conditions are satisfied only up to isomorphism, we get a pseudofunctor
Interestingly, this procedure of generating split opfibrations has its inverse. Given a functor
Since our new slogan is “lenses are everywhere,” it should come as no big surprise that a split opfibration may be seen as a type of a lens. The projection corresponds to view or get. It extracts 
Acknowledment
I’m grateful to Bryce Clarke for reading the draft and helpful comments.
Papers to read
- Johnson, Rosebrugh, and Wood, Lenses, fibrations and universal translations
- Johnson and Rosebrugh, Delta lenses and opfibrations
November 27, 2019 at 2:38 pm
Hi Bartosz,
I’ve been looking for your email but found this blog and decided that I could say Hi here equally well :). And now it’s difficult to resist to write a couple of comments on the subject.
Fibrartions. I am also in the club of those who find the usual definition of fibration not easy to follow (unfortunately, your piggy picture that explains the idea pretty well didn’t exist when I first tried to understand fibrations, pity..:). For me, an equivalent def. via weak Cartesian lifting turned out much easier: we first require universality of the lifting amongst those morphisms that are projected to f, and then require such lifts to be compositional up to natural iso: lift(f1;f2) ~ lift(f1);lift(f2). The equivalence is straightforward to see (it’s Exercise 1.1.6 in Categorical Logic and Type Theory by Bart Jacobs — a good source on fibrations).
Lenses (which are everywhere, you’re right). Let me talk about delta lenses only (I know them better), and so interpret you phrase “… \put takes s and f and produces a new object t” as “….. and produces a new arrow \put(s,f)”. Opfibrations are very special lenses as universal solutions rarely exist in many applications where we want to invert a functor. Or, we can have weak universality, but compositionality (Putput) fails. More interesting, perhaps, is that even if a universal solution exists, the lens may want not to use it for inverting the get.
Finally, an interesting player here is uncertainty. Suppose that we have a set of lifts (h_i, i in I) such that get(h_i)=f, but we cannot decide which of them we want as the inverse of f. If we have a mechanism for decoding sets of arrows by an arrow, that is, assume that an arrow (from the same source s) denoted by h_? somehow encodes the set (h_i, i in I), then we can define \put(s,f)=h_? and we are done (in the sense that the actual choice of h_i in the set h_? can be done later when we will have more information). The cases when a set h_? is uniquely defined by some universal properties are clearly easier to find than cases with universality of a single h_i. So, having an encoding mechanism as above may help to restore universality and make more lenses opfibrational. Various mechanisms of encoding a set by an element were developed under the umbrella of uncertainty, the most famous is probably the labelled nulls mechanism in databases.
December 19, 2019 at 7:54 am
[…] Перевод статьи Бартоша Милевски «Fibrations, Cleavages and Lenses» (исходный текст расположен по адресу — Текст оригинальной статьи). […]