Previously: Modeling Identity Types.
On first viewing, the identity type seems odd. Does it make sense to replace the traditional yes/no equality predicate with an elaborate type of equality proofs? In fact the father or modern type theory Martin Löf had his doubts, and initially tried to reflect all identity proofs into more basic judgmental or definitional equalities. This turned out to be too restrictive for many applications.
Still, some modern theorem provers like Lean impose the uniqueness of identity proofs (UIP) condition as an axiom. This so called axiom K states that reflexivity:

is the only possible proof of equality. Two things are equal if they are the same thing, otherwise they’re not. This works for most common data types.
Universes
There is, however, a much more interesting use case for non-trivial identity types. This happens when we apply equality to types themselves.
Since type theory is all about types, the question naturally arises, what is a type of a type? In Haskell, we call it a kind and denote as Type (or *, in legacy code).
In type theory we say that types form a universe. In Agda, the lowest such universe, 
Type l-zero (level zero), often abbreviated to Type. Of course, this begs the next question, what is the type of Type? Well, Type is a member of the next universe 
But if Type is a type then, like all types, it must be equipped with its own identity type. In other words, we should be albe to compare types for equality. The most obvious choice would be to say that two types are equal if they are isomorphic. We define an isomorphism as a pair of functions that are the inverse of each other. This makes perfect sense for sets, but we don’t want to treat types as sets. Types have more structure: every type comes equipped with its own identity type.
Equivalences
We’ve seen before that to model identity types we may look at homotopy theory. We model types as topological spaces and equality as continuous paths between points. The notion of isomorphism is too strong for comparing such spaces. What we need is an equivalence, which is an isomorphism modulo equality.
Indeed, we don’t need the round trip to land us exactly where we started — it’s enough that we land at a point that is equal to the original point. Here, equal means: there is a path that connects these two points. And once we have loosened the definition of what an inverse is, there is no reason to insist that the right inverse be the same as the left inverse. We can as well use two different functions, 

Thus a function 
- there exists a function
such that the composite
, that is
- there exists a function
such that the composite
, that is
.

If such functions exist, we say that 



Univalence
Equivalence is the only relation between types that behaves exactly like equality. Can we use it to define equality of types? This is what Vladimir Voevodsky postulated as the axiom of univalence.
For any 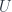

in other words, equality is equivalent to equivalence.
Equivalences are much easier to prove than equalities. However, without univalence, they don’t satisfy the rule of substitution of equals for equals. This rule formulated by Leibniz reads: “Two terms are the same if one can be substituted for the other without altering the truth of any statement.”
In Martin Löf type theory it’s impossible to define a predicate that would distinguish between equivalent types. This is why imposing the axiom of univalence to extend type theory makes perfect sense.
Mathematician often apply the substitution rule to terms that are isomorphic rather than equal, essentially leaving the proof of the validity of a substitution as an “exercise to the reader.” Univalence legitimizes this practice and leads to substantial simplification of many mathematical proofs.
However, just like with isomorphisms, there may be several equivalences between two types. In fact, a type can be equivalent to itself in more than one way. For instance, not is a non-trivial equivalence for Bool — it’s clearly different from id. By univalence, such different equivalences introduce different equalities. Uniqueness of identity proofs is thus incompatible with univalence.
Higher Inductive Types
If identity is a type like any other, then we may use it to define types that contain their own proofs of identity. Such types are called higher inductive types. The simplest example is the circle, which you may think of as a singleton 

data S¹ : Type where base : S¹ loop : base ≡ baseHere, base ≡ base denotes the type 

This definition is somewhat similar to, say, the definition of a boolean type:
data Bool : Type where true : Bool false : Boolexcept that, in the definition of the circle, the type of the second component depends on the value of the first component. This definition introduces explicitly an element of the identity type, 
Higher inductive types can be used to prove theorems in topological homotopy. Such proofs would normally involve topology, but in HoTT they are just statements about types. They can be formalized using theorem provers, like Agda.
I’m grateful to Thorsten Altenkirch for valuable comments on the draft of this post.
 that makes the outer square commute, there are no additional constraints on
that makes the outer square commute, there are no additional constraints on 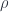 :
:
 for
for 
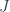 that makes the two triangles commute. But these commutation conditions tell us that
that makes the two triangles commute. But these commutation conditions tell us that  is isomorphic to
is isomorphic to  to be mapped to different “paths”
to be mapped to different “paths”  , and we’d also like to have some non-trivial paths left over to play with.
, and we’d also like to have some non-trivial paths left over to play with. . In a cartesian category with weak equivalences, we can use an abstract definition of the object representing the space of all paths in
. In a cartesian category with weak equivalences, we can use an abstract definition of the object representing the space of all paths in  is an object that factorizes the diagonal morphism
is an object that factorizes the diagonal morphism  , such that
, such that  is a weak equivalence.
is a weak equivalence.
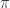 be a fibration, defining a good path object; and
be a fibration, defining a good path object; and 
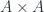 , can be uniquely extended to all paths?
, can be uniquely extended to all paths? to pick next. In fact, there might be only one value available to you — the “closest one” in the direction you’re going. To choose any other value, you’d have to “jump,” which would break continuity.
to pick next. In fact, there might be only one value available to you — the “closest one” in the direction you’re going. To choose any other value, you’d have to “jump,” which would break continuity. by growing it from its initial value
by growing it from its initial value  . You gradually extend it above the path
. You gradually extend it above the path  until you reach the point directly above
until you reach the point directly above  . (In fact, this is the rough idea behind cubical type theory.)
. (In fact, this is the rough idea behind cubical type theory.)
 to
to 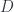 that starts at
that starts at  .
. is a cofibration,
is a cofibration, 
 . Such iterated types correspond to higher homotopies: paths between paths, and so on, ad infinitum. The structure that arises is called a weak infinity groupoid. It’s a category in which every morphism has an inverse (just follow the same path backwards), and category laws (identity or associativity) are satisifed up to higher morphisms (higher homotopies).
. Such iterated types correspond to higher homotopies: paths between paths, and so on, ad infinitum. The structure that arises is called a weak infinity groupoid. It’s a category in which every morphism has an inverse (just follow the same path backwards), and category laws (identity or associativity) are satisifed up to higher morphisms (higher homotopies). is equal to
is equal to  . This is called definitional equality, since it’s just part of the definition. However, if we reverse the order of the addends and try to prove
. This is called definitional equality, since it’s just part of the definition. However, if we reverse the order of the addends and try to prove  , there is no obvious shortcut. We have to prove it the hard way! This second type of equality is called propositional.
, there is no obvious shortcut. We have to prove it the hard way! This second type of equality is called propositional.
 written as
written as  , or even
, or even  , if the type
, if the type 
 . Here,
. Here,  (type of equality of proofs of equality), and so on, ad infinitum. This used to be a bane of Martin Löf type theory, but it became a bounty for Homotopy Type Theory. So let’s imagine that the identity type may have non-trivial inhabitants. We’ll call these inhabitants paths. The trivial paths generated by
(type of equality of proofs of equality), and so on, ad infinitum. This used to be a bane of Martin Löf type theory, but it became a bounty for Homotopy Type Theory. So let’s imagine that the identity type may have non-trivial inhabitants. We’ll call these inhabitants paths. The trivial paths generated by  to some type
to some type  and
and 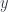 :
:

 , so it’s enough to specify how
, so it’s enough to specify how 
 and
and  . Except that here we have a whole family of constructors
. Except that here we have a whole family of constructors 

 . When projected down to
. When projected down to  , so we have:
, so we have:

 that maps
that maps  . So, when projected back to
. So, when projected back to 


 . The section condition is:
. The section condition is:

