Persistent trees are more interesting than persistent lists, which were the topic of my previous blog. In this installment I will concentrate on binary search trees. Such trees store values that can be compared to each other (they support total ordering). Such trees may be used to implement sets, multisets, or associated arrays. Here I will focus on the simplest of those, the set — the others are an easy extensions of the same scheme.
A set must support insertion, and membership test (I’ll leave deletion as an exercise). These operations should be doable, on average, in logarithmic time, O(log(N)). Only balanced trees, however, can guarantee logarithmic time even in the worst case. A simple tree may sometimes degenerate to a singly-linked list, with performance dropping to O(N). I will start with a simple persistent tree and then proceed with a balanced red-black tree.
Persistent Binary Search Tree
As with lists, we will start with an abstract definition:
A tree is either empty or contains a left tree, a value, and a right tree.
This definition translates into a data structure with two constructors:
template<class T>
class Tree {
public:
Tree(); // empty tree
Tree(Tree const & lft, T val, Tree const & rgt)
};
Just as we did with persistent lists, we’ll encode the empty/non-empty tree using null/non-null (shared) pointer to a node. A Node represents a non-empty tree:
struct Node
{
Node(std::shared_ptr<const Node> const & lft
, T val
, std::shared_ptr<const Node> const & rgt)
: _lft(lft), _val(val), _rgt(rgt)
{}
std::shared_ptr<const Node> _lft;
T _val;
std::shared_ptr<const Node> _rgt;
};
Here’s the complete construction/deconstruction part of the tree. Notice how similar it is to the list from my previous post. All these methods are const O(1) time, as expected. As before, the trick is to construct a new object (Tree) from big immutable chunks (lft and rgt), which can be safely put inside shared pointers without the need for deep copying.
template<class T>
class Tree
{
struct Node;
explicit Tree(std::shared_ptr<const Node> const & node)
: _root(node) {}
public:
Tree() {}
Tree(Tree const & lft, T val, Tree const & rgt)
: _root(std::make_shared<const Node>(lft._root, val, rgt._root))
{
assert(lft.isEmpty() || lft.root() < val);
assert(rgt.isEmpty() || val < rgt.root());
}
bool isEmpty() const { return !_root; }
T root() const {
assert(!isEmpty());
return _root->_val;
}
Tree left() const {
assert(!isEmpty());
return Tree(_root->_lft);
}
Tree right() const {
assert(!isEmpty());
return Tree(_root->_rgt);
}
private:
std::shared_ptr<const Node> _root;
};
Insert
The persistent nature of the tree manifests itself in the implementation of insert. Instead of modifying the existing tree, insert creates a new tree with the new element inserted in the right place. The implementation is recursive, so imagine that you are at a subtree of a larger tree. This subtree might be empty. Inserting an element into an empty tree means creating a single-node tree with the value being inserted, x, and two empty children.
On the other hand, if you’re not in an empty tree, you can retrieve the root value y and compare it with x. If x is less then y, it has to be inserted into the left child. If it’s greater, it must go into the right child. In both cases we make recursive calls to insert. If x is neither less nor greater than y, we assume it’s equal (that’s why we need total order) and ignore it. Remember, we are implementing a set, which does not store duplicates.
Tree insert(T x) const {
if (isEmpty())
return Tree(Tree(), x, Tree());
T y = root();
if (x < y)
return Tree(left().insert(x), y, right());
else if (y < x)
return Tree(left(), y, right().insert(x));
else
return *this; // no duplicates
}
Now consider how many new nodes are created during an insertion. A new node is only created in the constructor of a tree (in the code: std::make_shared<const Node>(lft._root, val, rgt._root)). The left and right children are not copied, they are stored by reference. At every level of insert, a tree constructor is called at most once. So in the worst case, when we recurse all the way to the leaves of the tree, we only create h nodes, where h is the height of the tree. If the tree is not too much out of balance its height scales like a logarithm of the number of nodes. To give you some perspective, if you store a billion values in a tree, an insertion will cost you 30 copies on average. If you need a logarithmic bound on the worst case, you’d have to use balanced trees (see later).
If you study the algorithm more closely, you’ll notice that only the nodes that are on the path from the root to the point of insertion are modified.
Testing for membership in a persistent tree is no different than in a non-persistent one. Here’s the recursive algorithm:
bool member(T x) const {
if (isEmpty())
return false;
T y = root();
if (x < y)
return left().member(x);
else if (y < x)
return right().member(x);
else
return true;
}
When using C++11, you might take advantage of the initializer list constructor to initialize a tree in one big swoop like this:
Tree t{ 50, 40, 30, 10, 20, 30, 100, 0, 45, 55, 25, 15 };
.
Here’s the implementation of such constructor, which works in O(N*log(N)) average time (notice that it effectively sorts the elements, and O(N*log(N)) is the expected asymptotic behavior for sort):
Tree(std::initializer_list<T> init) {
Tree t;
for (T v: init) {
t = t.insert(v);
}
_root = t._root;
}
Persistent Red-Black Tree
If you want to keep your tree reasonably balanced — that is guarantee that its height is on the order of log(N) — you must do some rebalancing after inserts (or deletes). Care has to be taken to make sure that rebalancing doesn’t change the logarithmic behavior of those operations. The balance is often expressed using some invariants. You can’t just require that every path from root to leaf be of equal length, because that would constrain the number of elements to be always a power of two. So you must give it some slack.
In the case of a red-black tree, the invariants are formulated in terms of colors. Every node in the tree is marked as either red or black. These are the two invariants that have to be preserved by every operation:
- Red invariant: No red node can have a red child
- Black invariant: Every path from root to an empty leaf node must contain the same number of black nodes — the black height of the tree.
This way, if the shortest path in a tree is all black, the longest path could only be twice as long, containing one red node between each pair of black nodes. The height of such a tree could only vary between (all black) log(N) and (maximum red) 2*log(N).
With these constraints in mind, the re-balancing can be done in log(N) time by localizing the modifications to the nearest vicinity of the path from the root to the point of insertion or deletion.
Let’s start with basic definitions. The node of the tree will now store its color:
enum Color { R, B };
Otherwise, it’s the same as before:
struct Node
{
Node(Color c,
std::shared_ptr const & lft,
T val,
std::shared_ptr const & rgt)
: _c(c), _lft(lft), _val(val), _rgt(rgt)
{}
Color _c;
std::shared_ptr _lft;
T _val;
std::shared_ptr _rgt;
};
An empty tree will be considered black by convention.
The membership test ignores colors so we don’t have to re-implement it. In fact the search performance of a persistent RB Tree is exactly the same as that of an imperative RB Tree. You pay no penalty for persistence in search.
With insertion, you pay the penalty of having to copy the path from root to the insertion point, which doesn’t change its O(log(N)) asymptotic behavior. As I explained before, what you get in exchange is immutability of every copy of your data structure.
The Balancing
Let’s have a look at the previous version of insert and figure out how to modify it so the result preserves the RB Tree invariants.
Tree insert(T x) const {
if (isEmpty())
return Tree(Tree(), x, Tree());
T y = root();
if (x < y)
return Tree(left().insert(x), y, right());
else if (y < x)
return Tree(left(), y, right().insert(x));
else
return *this; // no duplicates
}
Let’s first consider the most difficult scenario: the insertion into a maximum capacity tree for a given black height. Such a tree has alternating levels of all black and all red nodes. The only way to increase its capacity is to increase its black height. The cheapest way to add one more black level to all paths (thus preserving the black invariant) is to do it at the root (for instance, lengthening all the path at the leaves would require O(N) red-to-black re-paintings).
So here’s the plan: We’ll insert a new node at the leaf level and make it red. This won’t break the black invariant, but may break the red invariant (if the parent node was red). We’ll then retrace our steps back to the root, percolating any red violation up. Then, at the top level, we’ll paint the resulting root black, thus killing two birds with one stone: If we ended up with a red violation at the top, this will fix it and, at the same time, increase the black height of the whole tree.
It’s important that during percolation we never break the black invariant.
So here’s how we execute this plan: insert will call the recursive insertion/re-balancing method ins, which might return a red-topped tree. We’ll paint that root black (if it’s already black, it won’t change anything) and return it to the caller:
RBTree insert(T x) const {
RBTree t = ins(x);
return RBTree(B, t.left(), t.root(), t.right());
}
In the implementation of ins, the first case deals with an empty tree. This situation happens when it’s the first insertion into an empty tree or when, during the recursive process, we’ve reached the insertion point at the bottom of the tree. We create a red node and return it to the caller:
if (isEmpty())
return RBTree(R, RBTree(), x, RBTree());
Notice that, if this new node was inserted below another red node, we are creating a red violation. If that node was the root of the whole tree, insert will repaint it immediately. If it weren’t, and we pop one level up from recursion, we’ll see that violation. We can’t fix it at that point — for that we’ll have to pop one more level, up to the black parent, where we have more nodes to work with.
Here are the details of ins: We’ll follow the same logic as in the non-balanced tree, thus preserving the ordering of values; but instead of reconstructing the result tree on the spot we’ll call a function balance, which will do that for us in a semi-balanced way (that is, with a possibility of a red violation, but only at the very top).
RBTree ins(T x) const
{
if (isEmpty())
return RBTree(R, RBTree(), x, RBTree());
T y = root();
Color c = rootColor();
if (x < y)
return balance(c, left().ins(x), y, right());
else if (y < x)
return balance(c, left(), y, right().ins(x));
else
return *this; // no duplicates
}
Just like the constructor of the red-black tree, balance takes the following arguments: color, left subtree, value, and right subtree. Depending on the result of the comparison, the new element is inserted either into the left or the right subtree.
As I explained, balance, and consequently ins, cannot fix the red violation when they are sitting on it. All they can do is to make sure that the violation is at the very top of the tree they return. So when we call balance with the result of ins, as in:
balance(c, left().ins(x), y, right())
or:
balance(c, left(), y, right().ins(x))
the left or the right subtree, respectively, may be semi-balanced. This is fine because balance can then rotate this violation away.
So the interesting cases for balance are the ones that rebuild a black node with either the left or the right subtree having a red violation at the top.
There are four possible cases depending on the position of the violation. In each case we can rearrange the nodes in such a way that the violation disappears and the ordering is preserved. In the pictures below I have numbered the nodes and subtrees according to the order of the values stored in them. Remember that all values in the left subtree are less than the value stored in the node, which in turn is less than all the values in the right subtree.

Rotating lft.doubledLeft()
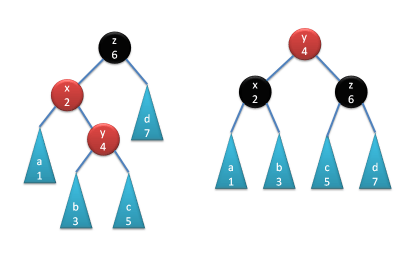
Rotating lft.doubledRight()()

Rotating rgt.doubledLeft()

Rotating rgt.doubledRight()()
Each rotation creates a tree that preserves both invariants. Notice, however, that the result of the rotation is always red-tipped, even though we were rebuilding a node that was originally black. So if the parent of that node was red, our caller will produce a red violation (it will call balance with red color as its argument, which will fall through to the default case). This violation will be then dealt with at the parent’s parent level.
static RBTree balance(Color c
, RBTree const & lft
, T x
, RBTree const & rgt)
{
if (c == B && lft.doubledLeft())
return RBTree(R
, lft.left().paint(B)
, lft.root()
, RBTree(B, lft.right(), x, rgt));
else if (c == B && lft.doubledRight())
return RBTree(R
, RBTree(B, lft.left(), lft.root(), lft.right().left())
, lft.right().root()
, RBTree(B, lft.right().right(), x, rgt));
else if (c == B && rgt.doubledLeft())
return RBTree(R
, RBTree(B, lft, x, rgt.left().left())
, rgt.left().root()
, RBTree(B, rgt.left().right(), rgt.root(), rgt.right()));
else if (c == B && rgt.doubledRight())
return RBTree(R
, RBTree(B, lft, x, rgt.left())
, rgt.root()
, rgt.right().paint(B));
else
return RBTree(c, lft, x, rgt);
}
For completeness, here are the auxiliary methods used in the implementation of balance:
bool doubledLeft() const {
return !isEmpty()
&& rootColor() == R
&& !left().isEmpty()
&& left().rootColor() == R;
}
bool doubledRight() const {
return !isEmpty()
&& rootColor() == R
&& !right().isEmpty()
&& right().rootColor() == R;
}
RBTree paint(Color c) const {
assert(!isEmpty());
return RBTree(c, left(), root(), right());
}
Conclusion
Our implementation of the persistent red-black tree follows the Chris Okasaki’s book. As Chris asserts, this is one of the fastest implementations there is, and he offers hints to make it even faster. Of course there are many imperative implementations of red-black trees, including STL’s std::set and std::map. Persistent RB-trees match their performance perfectly when it comes to searching. Insertion and deletion, which are O(log(N)) for either implementation, are slower by a constant factor because of the need to copy the path from root to leaf. On the other hand, the persistent implementation is thread-safe and synchronization-free (except for reference counting in shared_ptr — see discussion in my previous blog).
Complete code is available at GitHub.
Acknowledgment
I’d like to thank Eric Niebler for reading the draft and telling me which of my explanations were more abstruse than usual.
Haskell Code
For comparison, here’s the original Haskell code. You can see that the C++ implementation preserves its structure pretty well. With proper optimization tricks (unboxing and eager evaluation) the Haskell code should perform as well as its C++ translation.
Regular (unbalanced) binary search tree:
data Tree a = Empty | Node (Tree a) a (Tree a)
member x Empty = False
member x (Node lft y rgt) =
if x < y then member x lft
else if y < x then member x rgt
else True
insert x Empty = Node Empty x Empty
insert x t@(Node lft y rgt) =
if x < y then Node (insert x lft) y rgt
else if y < x then Node lft y (insert x rgt)
else t
Balanced Red-Black tree:
data Color = R | B
data Tree a = Empty | Node Color (Tree a) a (Tree a)
member x Empty = False
member x (Node _ lft y rgt) =
if x < y then member x lft
else if y < x then member x rgt
else True
insert x tree = Node B left val right
where
ins Empty = Node R Empty x Empty
ins t@(Node c lft y rgt) =
if (x < y) then balance c (ins lft) y rgt
else if (y < x) then balance c lft y (ins rgt)
else t
Node _ left val right = ins tree -- pattern match result of ins
balance B (Node R (Node R a x b) y c) z d =
Node R (Node B a x b) y (Node B c z d)
balance B (Node R a x (Node R b y c)) z d =
Node R (Node B a x b) y (Node B c z d)
balance B a x (Node R (Node R b y c) z d) =
Node R (Node B a x b) y (Node B c z d)
balance B a x (Node R b y (Node R c z d)) =
Node R (Node B a x b) y (Node B c z d)
balance color a x b = Node color a x b
November 25, 2013 at 1:36 pm
Nice use of the Haskell @ operator. Never knew about it before!
November 25, 2013 at 2:02 pm
“@” is not a Haskell operator, it’s part of the pattern syntax. “+”, “*”, and “>=>” are Haskell operators, and are defined like other binary functions.
November 25, 2013 at 5:52 pm
To compile on OS X Mavericks, I needed to add
to RBTree.h and change void main() to int main() in TreeTest.cpp.
To compile use:
clang++ -std=c++11 -stdlib=libc++ TreeTest.cpp
Thanks!
November 25, 2013 at 8:21 pm
To compile on OS X Mavericks, I needed to add #include to RBTree.h and change void main() to int main() in TreeTest.cpp.
To compile use:
clang++ -std=c++11 -stdlib=libc++ TreeTest.cpp
—
The inclusion of algorithm was not in earlier comment.
November 26, 2013 at 9:29 am
Excellent! BTW, How did you produce the graphics?
November 26, 2013 at 11:47 am
@Kip: I used Power Point.
December 4, 2013 at 7:17 pm
Gasp! Power Point! Not diagrams?
December 10, 2013 at 8:18 am
After haven given it some thought, it seems that in the persistent design, the double-Black removal can be reduced to just two cases, the black-sibling and red-sibling case because one has to traverse all the way to the root anyway?
December 10, 2013 at 10:36 am
[…] I described C++ implementations of two basic functional data structures: a persistent list and a persistent red-black tree. I made an argument that persistent data structures are good for concurrency because of their […]
December 10, 2013 at 11:06 am
[…] thread safety […]? Is that supposed to answer my question? I was kind of asking whether the persistent implementation can ignore more complex local cases that avoid propagation of double-Blackness to the parent because we have to stack-unwind back to the root anyway. So in the persistent case avoiding double-Black propagation to the parent doesn’t really buy us anything and we can avoid looking at the color of nephews, nieces, uncles and aunts.
December 10, 2013 at 11:28 am
Thomas: I’m not following. What is your question? (Comment 9 is just a pingback from my next post and has nothing to do with it.)
December 10, 2013 at 12:26 pm
Sorry for misinterpreting #9 as a response to my post #8. I’ve been playing around with writing a delete/remove function for the ‘RBTree’ class. I googled up some papers and basically all the solutions are rather complex because they want to solve the problem as locally as possible. So they numersous cases depending on the color of numerous nodes. The solutions also did not translate well into the persistent version, and I was getting a bit a bit frustrated. Then, after having a closer look at your ‘ins’, it seemed to me that there is a simple solution that only checks the color of the sibling node (in the function that corresponds to ‘balance’ in your code). As I haven’t implemented it yet, I was kind of asking whether I was on the right track (and confirmation that it actually is a solution), but maybe I’m just too wrapped up in my thoughts to make much sense to anyone else.
Anyway: thanks for a great post. I had fun playing with the code.
December 11, 2013 at 9:20 am
@Thomas, we have a persistent RBT implementation here that a colleague and I wrote a couple of years ago. The code is proprietary so I can’t share it – but I can confirm that deletion is *much* more involved than insert! IIRC there are a few possible approaches. We went the route of introducing transient “negative black” nodes that then need to be eliminated. This requires four or five (depending how you count them) extra operations – each at least as complex as the re-balance required on the insert (a couple about twice as complex!).
So, yeah, “left as an exercise”, is a bit of a cop out 😉
We also made the additional optimisation of using intrusively counted nodes (tracking internal an external counts independently) where we check the sharedness on the descent, and on branches that are wholly unshared we can do the rotations in-place. It’s a bit more risky because you have to be sure to get it right. But it does give us a noticeable performance boost (especially for initial load, which is usually wholly unshared). And we’re performance sensitive.
However we’ve since moved on to using a persistent hash-trie instead as this performs nearly an order of magnitude better still! Again the code we have is proprietary but I’ve got my own open-source version I’ve been ticking over on the side for a while that I’ll finish and write up at some point. In the meantime there are some other references around if you search for them.
December 11, 2013 at 1:23 pm
Well, its hard to talk about code. I’ve managed to get my idea coded. It runs the a few simple removes, where I checked the result in the degugger, but it is not tested.
http://coliru.stacked-crooked.com/a/233ea4078dfc6767
As Alexandrescu would say: Destroy!
December 11, 2013 at 4:25 pm
Please ignore the previous code. A refactoring broke it. The code that was working was this:
http://coliru.stacked-crooked.com/a/8f72b314dbbbdf4d
June 9, 2014 at 10:36 am
[…] list. There are also many tree-like data structures that are logarithmically cheap to clone-mutate (red-black trees, leftist heaps). Parallel algorithms are easy to implement with functional data structures, since […]
February 11, 2016 at 7:27 am
How hard would it be to extend this to allow modifications to be grouped?That is, instead of every insert producing a new tree, a new tree is produced after applying N number of inserts, or other mutations.
February 11, 2016 at 4:17 pm
@Noah: The whole idea is to avoid mutation, especially if you do parallel processing. Also, the logic in RBtrees is already quite complex, so adding more complexity would be quite tricky. But you can try. Just find a good use scenario and do profiling before and after.
July 10, 2016 at 6:11 pm
@Bartosz I didn’t intend to imply I was interested in partial persistence (grouped mutations) as a performance optimization (which seems to be the case given your profiling suggestion). Partial persistence is a useful property outside the functional language domain in certain algorithms. Since this construction of the persistent tree is simple in comparison to other techniques, it seemed like a good place to start.