Previously we were exploring universal constructions for products, coproducts, and exponentials. In particular, we were able to prove the distributive law:

The power of this law is that it relates the mapping-in universal construction (product on the left) with the mapping-out one (coproduct on the right). If you take into account that products and coproducts are just special cases of limits and colimits, you may ask a more general question: under what conditions limits commute with colimits. In a cartesian closed category a product of sums is not equal to the sum of products:
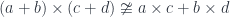
So, in general, products don’t commute with coproducts. But if you replace coproducts with a special kind of colimits, then it can be shown that:
Theorem.
In 
In this post I’ll try to explain these terms and provide some intuition why it works and how filtered colimits are related to the more traditional notion of limits that we know from calculus.
Limits
Let’s start with limits. They are like products, except that, instead of just two objects at the bottom, you have any number of objects plus a bunch of morphisms between them. That’s called a diagram. Then you have an apex with arrows going down to all the objects in the diagram; and you get what is called a cone. If you have morphisms in your diagram, they form triangles. These triangles must commute. For instance, in Fig 1, we have:

Fig. 1. A cone
This means that not all projections are independent–that you may obtain one projection from another by post-composing it with a morphism from the diagram. In Fig 1, for instance, you may extract a value of 


A limit is defined as the universal cone with the apex 


and so on. We’ve seen similar commuting conditions in the definition of the product.

Fig. 2. A universal cone
If you think of 




But because of the commuting conditions, the three values stored in
A limit, just like a product, is defined by a mapping-in property. If you want to define a morphism from some 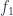



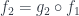

Fig. 3. A simplified universal cone
Notice that the diagram essentially forms a subcategory inside the category 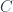




The properties of the diagram category determine the nature of cones and the nature of the limits. For instance, functors from a finite category will produce finite limits.

Fig. 4. Diagram category
The diagram category
The intuition is that cofiltered categories exhibit some kind of ordering. You may think of

That’s where these ideas originally came from.
Limits in the category of sets have a particularly simple interpretation. In

Fig. 5. Elements of the limit
For every selection in Fig 5. of 
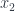



Colimits
Colimits are dual to limits–you get them by inverting all the arrows. So, instead of projections, you get injections, and the universal condition defines a mapping out of a colimit (see Fig 6).

Fig. 6. A universal cocone
If you look at the colimit as a data structure, it is similar to a coproduct, except that not all the injections are independent. In the example in Fig 6, 
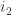
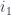
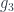

data Colim a1 a2 a3 (g2 :: a2 -> a1) (g3 :: a3 -> a1) =
= A1 a1 | A2 a2 | A3 a3
To deconstruct this colimit, you only need to provide one function 
h :: (a1 -> c) -> Colim a1 a2 a3 g2 g3 -> c h f1 (A1 a1) = f1 a1 h f1 (A2 a2) = f1 (g2 a2) h f1 (A3 a3) = f1 (g3 a3)
Granted, in a lazy language like Haskell, this would be an overkill way to store essentially just one value.
A colimit in the category of sets simplifies to a disjoint union of sets, in which some elements are identified. Suppose that the colimit 

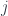


Fig. 7. Colimit in Set. On the left, the diagram category
The disjoint union of all these sets is a set whose elements are the pairs 
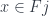

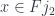





must be identified. This is not an equivalence relation, but it can be extended to one (by first symmetrizing it, and then making it transitive again). A colimit is then a quotient of the disjoint union by this equivalence.
As before, I chose this example to illustrate a special type of a diagram. This is a diagram that can be obtained using a functor from a filtered category. A filtered category has this property that for any finite subdiagram, there is a cocone under it. Here, for instance, the subdiagram formed by
Commuting Limits and Colimits
What does it mean for a limit to commute with a colimit? A single colimit is generated by a functor from some index category 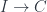
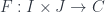
It follows that, for any given 
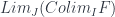
Alternatively, when we fix some 



Fig. 8. Commuting limits (red diagram of shape
It’s not difficult to construct the mapping:
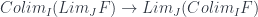
using the universal property, since the colimit has the mapping-out property. It’s the other way around that’s tricky. But it always works in the special case when
Here’s the sketch of this amazing proof, which you can find in Saunders Mac Lane’s Categories for the Working Mathematician.
Since the target of the functor is Set, it might help to visualize its image as a rectangular array of sets. A fixed

pointwise. Let’s pick an element of the limit on the left. As we’ve established earlier, a limit in Set is a set of apex-1 cones. So let’s pick one such cone. It’s just a selection of elements from a bunch of colimits.
As we’ve seen before, a colimit in Set is a discriminated union with some identifications. So our apex-1 cone will pick a set of representatives, one per colimit, say 


If 


Fig. 9. A single cone after shifting representatives from all colimits to a common column
But that’s just a cone over 

Conclusion
If you didn’t get the proof the first time, don’t get discouraged. Take a break, sleep over it, and then read it slowly again. Make sure you have internalized all the definitions. Draw your own pictures. The two major tricks are: (1) visualizing an element of a limit as a cone originating from the singleton set, and (2) the idea of sliding the elements of multiple colimits to a common column.
The importance of this theorem is that it tells you when and how you can define mappings out of limits. For instance, how to define functions from a product or from an end.
Acknowledgment
I’m grateful to Derek Elkins for correcting mistakes in the original version of this post.
December 10, 2019 at 7:58 am
[…] Перевод статьи Бартоша Милевски «Filtered Colimits» (исходный текст расположен по адресу — Текст оригинальной статьи). […]