The main idea of functional programming is to treat functions like any other data types. In particular, we want to be able to pass functions as arguments to other functions, return them as values, and store them in data structures. But what kind of data type is a function? It’s a type that, when paired with another piece of data called the argument, can be passed to a function called apply to produce the result.
apply :: (a -> d, a) -> d
In practice, function application is implicit in the syntax of the language. But, as we will see, even if your language doesn’t support higher-order functions, all you need is to roll out your own apply.
But where do these function objects, arguments to apply, come from; and how does the built-in apply know what to do with them?
When you’re implementing a function, you are, in a sense, telling apply what to do with it–what code to execute. You’re implementing individual chunks of apply. These chunks are usually scattered all over your program, sometimes anonymously in the form of lambdas.
We’ll talk about program transformations that introduce more functions, replace anonymous functions with named ones, or turn some functions into data types, without changing program semantics. The main advantage of such transformations is that they may improve performance, sometimes drastically so; or support distributed computing.
Function Objects
As usual, we look to category theory to provide theoretical foundation for defining function objects. It turns out that we are able to do functional programming because the category of types and functions is cartesian closed. The first part, cartesian, means that we can define product types. In Haskell, we have the pair type (a, b) built into the language. Categorically, we would write it as 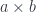
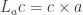
It’s really a family of functors that it parameterized by 
The right adjoint to this functor
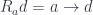
defines the function type 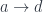

An adjunction is defined as a (natural) isomorphism of hom-sets:
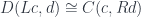
or, in our case of two endofunctors, for some fixed
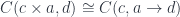
In Haskell, this is just the definition of currying:
curry :: ((c, a) -> d) -> (c -> (a -> d)) uncurry :: (c -> (a -> d)) -> ((c, a) -> d)
You may recognize the counit of this adjunction
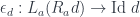
as our apply function
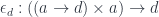
Adjoint Functor Theorem
In my previous blog post I discussed the Freyd’s Adjoint Functor theorem from the categorical perspective. Here, I’m going to try to give it a programming interpretation. Also, the original theorem was formulated in terms of finding the left adjoint to a given functor. Here, we are interested in finding the right adjoint to the product functor. This is not a problem, since every construction in category theory can be dualized by reversing the arrows. So instead of considering the comma category 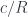
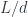
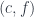

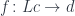

This is the general picture but, in our case, we are dealing with a single category, and 
data Comma a d c = Comma c ((c, a) -> d)
The type a is just a parameter, it parameterizes the (left) functor
and d is the target object of the comma category.
We are trying to construct a function object representing functions a->d, so what role does c play in all of this? To understand that, you have to take into account that a function object can be used to describe closures: functions that capture values from their environment. The type c represents those captured values. We’ll see this more explicitly later, when we talk about defunctionalizing closures.
Our comma category is a category of all closures that go from 
The morphisms of the comma category are morphisms 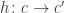
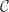
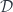

Unfortunately, commuting diagrams cannot be expressed in Haskell. The closest we can get is to say that a morphism from
c1 :: Comma a d c
to
c2 :: Comma a d c'
is a function h :: c -> c' such that, if
c1 = Comma c f f :: (c, a) -> d c2 = Comma c' g g :: (c', a) -> d
then
f = g . bimap h id
Here, bimap h id is the lifting of h to the functor 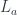
f (c, x) = g (h c, x)
As we are interpreting c as the environment in which the closure is defined, the question is: does f use all of the information encoded in c or just a part of it? If it’s just a part, then we can factor it out. For instance, consider a lambda that captures an integer, but it’s only interested in whether the integer is even or odd. We can replace this lambda with one that captures a Boolean, and use the function even to transform the environment.
The next step in the construction is to define the projection functor from the comma category

We use this functor to define a diagram in 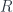
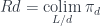
In our case, the forgetful functor discards the function part of Comma a d c, keeping only the environment 
d is not Void, we are dealing with a gigantic diagram that encompasses all objects in our category of types. The colimit of this diagram is a gigantic coproduct of everything, modulo identifications introduced by morphisms of the comma category. But these identifications are crucial in pruning out redundant closures. Every lambda that uses only part of the information from the captured environment can be identified with a simpler lambda that uses a simplified environment.
For illustration, consider a somewhat extreme case of constructing the function object 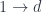



so the comma category 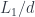
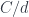
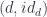
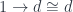
Intuitively, given a lambda that captures a value of type
It’s instructive to run a few more examples to get the hang of it. For instance, the function object Bool->d can be constructed by considering closures of the type
f :: (c, Bool) -> d
Any such closure can be factorized by the following transformation of the environment
h :: c -> (d, d) h c = (f (c, True), f (c, False))
followed by
g :: ((d, d), Bool) -> d g ((d1, d2), b) = if b then d1 else d2
Indeed:
f (c, b) = g (h c, b)
In other words
where 
Bool type.
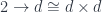
Counit
We are particularly interested in the counit of the adjunction. Its component at
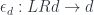
It also happens to be an object in the comma category, namely
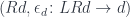
In fact, it is the terminal object in that category. You can see that because for any other object 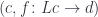


This morphisms 
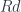


To get some insight into the construction of the function object, imagine that you can enumerate the set of all possible environments 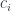
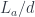
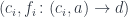

I used the distributive law:
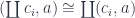
and the fact that the mapping out of a sum is the product of mappings. The right hand side can be constructed from the morphisms of the comma category.
So the object 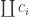
apply for it. It is highly redundant, though. This is why, instead of the coproduct, we used the colimit in our construction of the function object. Also, we ignored the size issues.
Size Issues
As we discussed before, this construction doesn’t work in general because of size issues: the comma category is not necessarily small, and the colimit might not exist.
To address this problems, we have previously defined small solution sets. In the case of the right adjoint, a solution set is a family of objects that is weakly terminal in 

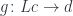
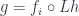
It means that we can always find an index 


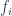

Once we have a complete solution set, the right adjoint
What is really interesting is that, in some cases, we can just use the coproduct of the solution set, 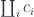

The idea is that, in a particular program, we don’t need to represent all possible function types, just a (small) subset of those. We are also not particularly worried about uniqueness: it’s no problem if the same function ends up with multiple syntactic representations.
Let’s reformulate Freyd’s construction of the function object in programming terms. The solution set is the set of types
such that, for any function
that is of interest in our program (for instance, used as an argument to another function) there exists an
such that
In other words, every function of interest can be replaced by one of the solution-set functions. The environment for this standard function can be always extracted from the environment of the more general function.
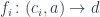
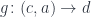
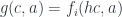
CPS Transformation
A particular application of higher order functions shows up in the context of continuation passing transformation. Let’s look at a simple example. We are going to implement a function that traverses a binary tree containing strings, and concatenates them all into one string. Here’s the tree
data Tree = Leaf String
| Node Tree String Tree
Recursive traversal is pretty straightforward
show1 :: Tree -> String show1 (Leaf s) = s show1 (Node l s r) = show1 l ++ s ++ show1 r
We can test it on a small tree:
tree :: Tree
tree = Node (Node (Leaf "1 ") "2 " (Leaf "3 "))
"4 "
(Leaf "5 ")
test = show1 tree
There is just one problem: recursion consumes the runtime stack, which is usually a limited resource. Your program may run out of stack space resulting in the “stack overflow” runtime error. This is why the compiler will turn recursion into iteration, whenever possible. And it is always possible if the function is tail recursive, that is, the recursive call is the last call in the function. No operation on the result of the recursive call is permitted in a tail recursive function.
This is clearly not happening in our implementation of show1: After the recursive call is made to traverse the left subtree, we still have to make another call to traverse the right tree, and the two results must be concatenated with the contents of the node.
Notice that this is not just a functional programming problem. In an imperative language, where iteration is the rule, tree traversal is still implemented using recursion. That’s because the data structure itself is recursive. It used to be a common interview question to implement non-recursive tree traversal, but the solution is always to explicitly implement your own stack (we’ll see how it’s done at the end of this post).
There is a standard procedure to make functions tail recursive using continuation passing style (CPS). The idea is simple: if there is stuff to do with the result of a function call, let the function we’re calling do it instead. This “stuff to do” is called a continuation. The function we are calling takes the continuation as an argument and, when it finishes its job, it calls it with the result. A continuation is a function, so CPS-transformed functions have to be higher-order: they must accept functions as arguments. Often, the continuations are defined on the spot using lambdas.
Here’s the CPS transformed tree traversal. Instead of returning a string, it accepts a continuation k, a function that takes a string and produces the final result of type a.
show2 :: Tree -> (String -> a) -> a
show2 (Leaf s) k = k s
show2 (Node lft s rgt) k =
show2 lft (\ls ->
show2 rgt (\rs ->
k (ls ++ s ++ rs)))
If the tree is just a leaf, show2 calls the continuation with the string that’s stored in the leaf.
If the tree is a node, show2 calls itself recursively to convert the left child lft. This is a tail call, nothing more is done with its result. Instead, the rest of the work is packaged into a lambda and passed as a continuation to show2. This is the lambda
\ls ->
show2 rgt (\rs ->
k (ls ++ s ++ rs))
This lambda will be called with the result of traversing the left child. It will then call show2 with the right child and another lambda
\rs ->
k (ls ++ s ++ rs)
Again, this is a tail call. This lambda expects the string that is the result of traversing the right child. It concatenates the left string, the string from the current node, and the right string, and calls the original continuation k with it.
Finally, to convert the whole tree t, we call show2 with a trivial continuation that accepts the final result and immediately returns it.
show t = show2 t (\x -> x)
There is nothing special about lambdas as continuations. It’s possible to replace them with named functions. The difference is that a lambda can implicitly capture values from its environment. A named function must capture them explicitly. The three lambdas we used in our CPS-transformed traversal can be replaced with three named functions, each taking an additional argument representing the values captured from the environment:
done s = s next (s, rgt, k) ls = show3 rgt (conc (ls, s, k)) conc (ls, s, k) rs = k (ls ++ s ++ rs)
The first function done is an identity function, it forces the generic type a to be narrowed down to String.
Here’s the modified traversal using named functions and explicit captures.
show3 :: Tree -> (String -> a) -> a show3 (Leaf s) k = k s show3 (Node lft s rgt) k = show3 lft (next (s, rgt, k)) show t = show3 t done
We can now start making the connection with the earlier discussion of the adjoint theorem. The three functions we have just defined, done, next, and conc, form the family
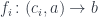
They are functions of two arguments, or a pair of arguments. The first argument represents the object
() (String, Tree, String -> String) (String, String, String->String)
(Notice the empty environment of done, here represented as the unit type ().)
The second argument of all three functions is of the type String, and the return type is also String so, according to Freyd’s theorem, we are in the process of defining the function object 
String and 
String.
Defunctionalization
Here’s the interesting part: instead of defining the general function type String->String, we can approximate it with the coproduct of the elements of the solution set. Here, the three components of the sum type correspond to the environments captured by our three functions.
data Kont = Done
| Next String Tree Kont
| Conc String String Kont
The counit of the adjunction is approximated by a function from this sum type paired with a String, returning a String
apply :: Kont -> String -> String apply Done s = s apply (Next s rgt k) ls = show4 rgt (Conc ls s k) apply (Conc ls s k) rs = apply k (ls ++ s ++ rs)
Rather than passing one of the three functions to our higher-order CPS traversal, we can pass this sum type
show4 :: Tree -> Kont -> String show4 (Leaf s) k = apply k s show4 (Node lft s rgt) k = show4 lft (Next s rgt k)
This is how we execute it
show t = show4 t Done
We have gotten rid of all higher-order functions by replacing their function arguments with a data type equipped with the apply function. There are several situations when this is advantageous. In procedural languages, defunctionalization may be used to replace recursion with loops. In fact, the Kont data structure can be seen as a user-defined stack, especially if it’s rewritten as a list.
type Kont = [(String, Either Tree String)]
Here, Done was replaced with an empty list and Next and Conc together correspond to pushing a value on the stack.
In Haskell, the compiler performs tail recursion optimization, but defunctionalization may still be useful in implementing distributed systems, or web servers. Any time we need to pass a function between a client and a server, we can replace it by a data type that can be easily serialized.
Bibliography
- John C. Reynolds, Definitional Interpreters for Higher-Order Programming Languages
- James Koppel, The Best Refactoring You’ve Never Heard Of.
August 4, 2020 at 1:11 am
(In C++) you can look at a function as being a transient class instance – a class with one method. Calling a function is then much the same as doing a class instantiation and calling the method.
August 4, 2020 at 8:29 am
In fact, in C++ you can have function objects with data: these are closures I’m talking about.
August 5, 2020 at 1:15 am
“An adjunction is defined as a (natural) isomorphism of hom-sets:” and then it should be “D(Lc, d) ~= C(c, Rd)”
and lower: “D(c x a, d) ~= C(c, a -> d)”
August 5, 2020 at 2:03 am
I would also add explicit “I” (identity functor) in counit definition, so “e d :: La (Ra d) -> I d” and then we substitute L, R, I functors from our case and get “apply :: ((a->d), a) -> d”
August 5, 2020 at 3:11 am
[…] 函数式编程的主要思想是将函数像其他任何数据类型一样对待。特别是,我们希望能够将函数作为参数传递给其他函数,将它们作为值返回,并将其存储在数据结构中。但是函数是哪种数据类型?这种类型可以与另一个称为参数的数据配对,然后传递给名为apply的函数以产生结果。 应用::(a-> d,a)-> d 在实践中,函数应用程序隐含在语言的语法中。但是,正如我们将看到的那样,即使您的语言不支持高阶功能,您所要做的就是推出自己的应用程序。 但是这些函数对象,应用的参数从哪里来?内置应用程序如何知道如何处理它们? 从某种意义上说,当您实现一个函数时,您在告诉应用与之相关的事情-执行什么代码。您正在实现单个的应用块。这些块通常散布在您的程序中,有时以lambda形式匿名散布。 我们将讨论在不改变程序语义的情况下,引入更多功能,用命名功能替换匿名功能或将某些功能转换为数据类型的程序转换。这种转换的主要优点是它们可以提高性能,有时甚至可以极大地提高性能。或支持分布式计算。 功能对象 像往常一样,我们希望通过分类理论为定义功能对象提供理论基础。事实证明,我们能够进行函数式编程,因为类型和函数的类别是笛卡尔封闭的。第一部分,笛卡尔,意味着我们可以定义产品类型。在Haskell中,我们在语言中内置了配对类型(a,b)。分类地,我们将其写为。产品在两个参数中都是函子的,因此,特别地,我们可以定义一个函子 它实际上是由设置的函子族。 该函子的正确伴随物 定义函数类型(也就是指数对象)。此附加条件的存在是导致类别关闭的原因。您可能会将这两个函子分别视为作者函子和读者函子。当参数限制为monoid时,编写器函子将变为monad(阅读器已为monad)。 附加定义为hom集的(自然)同构: 或者,就我们而言,对于某些固定的 在Haskell中,这只是currying的定义: 咖喱::(((c,a)-> d)->(c->(a-> d)) 非curry ::(c->(a-> d))->(((c,a)-> d) 您可能会认识到此附加功能的共同之处 作为我们的应用功能 伴随函子定理 在我以前的博客文章中,我从分类的角度讨论了弗雷德的伴随函子定理。在这里,我将尝试对其进行编程解释。同样,原始定理是根据找到给定函子的左伴随而制定的。在这里,我们有兴趣找到产品函子的正确伴侣。这不是问题,因为类别理论中的每个构造都可以通过反转箭头来双重化。因此,我们不考虑逗号类别,而是使用逗号类别。它的对象是成对的,在其中是射态 。 这是一般情况,但在我们的情况下,我们只处理一个类别,并且是一个终结者。我们可以在Haskell中实现逗号类别的对象 数据逗号a d c=逗号c((c,a)-> d) 类型a只是一个参数,它对(左)函子进行参数化 d是逗号类别的目标对象。 我们正在尝试构造一个表示a-> d函数的函数对象,那么c在所有这一切中起什么作用?要了解这一点,您必须考虑到可以使用函数对象来描述闭包:从其环境捕获值的函数。类型c表示那些捕获的值。稍后我们在讨论关闭闭包功能时,将更清楚地看到这一点。 我们的逗号类别是捕获所有可能环境时从到的所有闭包的类别。我们正在构造的函数对象本质上是所有这些闭包的总和,除了其中一些闭包是多次计数的,因此我们需要执行一些标识。这就是射影的目的。 逗号类别的词素是使下面的三角形成为通勤的词素。 不幸的是,通勤图不能用Haskell表示。我们能得到的最接近的说法是 c1 ::逗号和c 至 c2 ::逗号和c’ 是一个函数h :: c-> c’,如果 c1=逗号c f f ::(c,a)-> d c2=逗号c’g g ::(c’,a)-> d 然后 f=g双图隐藏 在这里,bimap h id是h向函子的提升。更明确地 f(c,x)=g(h c,x) 当我们将c解释为定义闭包的环境时,问题是:f使用c编码的所有信息还是仅使用c的一部分?如果只是一部分,我们可以将其排除在外。例如,考虑一个可以捕获整数的lambda,但它只对整数是偶数还是奇数感兴趣。我们可以用捕获布尔值的那个lambda代替它,甚至使用该函数来转换环境。 构造的下一步是定义投影函子,从逗号分类回到忘记零件而只保留对象的地方。 我们使用此函子在中定义图。现在,我们不再像上一部分中那样限制它,而是采用该图的限制。我们将使用此限制来定义上正确的伴随函子的作用。 在我们的例子中,健忘的函子放弃了逗号a d c的功能部分,只保留了环境。这意味着,只要d不是Void,我们就在处理一个巨大的图,该图包含了我们类型类别中的所有对象。该图的共极限是所有事物的巨大副产物,由逗号类别的态射引入了模识别。但是,这些标识对于删除多余的闭包至关重要。每个仅使用捕获的环境中的部分信息的lambda可以通过使用简化环境的简单lambda进行标识。 为了说明起见,请考虑构造函数对象或(根据终端对象的能力)的某种极端情况。该对象应与相同。让我们看看它是如何工作的:终端对象是产品的单位,因此 因此逗号类别只是箭头的切片类别。碰巧该类别具有终端对象。具有终端对象的图的限制是该终端对象。因此,实际上,在这种情况下,我们的构造产生了一个与相同的函数对象。 直观地讲,给定一个lambda可以从环境中捕获一个类型的值并返回a,我们可以将其微不足道地分解出来,使用该lambda将环境转换为,然后将其应用于。后者对应于逗号类别对象,健忘的仿函数将其映射到。 再举几个例子来掌握它是有启发性的。例如,可以通过考虑类型的闭包来构造函数对象Bool-> d f ::(c,布尔)-> d 任何此类关闭都可以通过以下环境转换来分解 h :: c->(d,d) h c=(f(c,True),f(c,False)) 其次是 g ::((d,d),布尔)-> d g((d1,d2),b)=如果b则d1否则d2 确实: f(c,b)=g(h c,b) 换一种说法 其中对应于布尔类型。 单位 我们对附加条件的共同单元特别感兴趣。它的成分是态射 它也恰好是逗号类别中的一个对象,即 。 实际上,它是该类别中的终端对象。您会看到,因为对于任何其他对象,都有一个使下面的三角形通勤的变态: 这个射影是定义在末端尾骨中的一条腿。我们肯定知道这是在那个concone的基础上,因为它是的投影。 为了深入了解功能对象的构造,请想象您可以枚举所有可能环境的集合。这样,逗号类别将由对组成。所有这些环境的副产品都是功能对象的理想选择。确实,让我们尝试为其定义一个联合单位: 我使用分配律: 并且总和中的映射是映射的结果。可以从逗号类别的词素构造右侧。 因此,该对象至少满足功能对象的一个要求:有一个apply的实现。但是,它是高度冗余的。这就是为什么在构造函数对象时使用colimit而不是coproduct的原因。此外,我们忽略了尺寸问题。 尺寸问题 正如我们之前所讨论的,由于大小问题,这种构造通常无法正常工作:逗号类别不一定很小,并且colimit可能不存在。 为了解决此问题,我们先前定义了小型解决方案集。在右伴随的情况下,解决方案集是一系列对象,它们在中弱端。这些对可以相互排除 这意味着我们总是可以找到一个索引和一个态射来满足该方程。每个人可能都需要一个不同的人,并且要通通考虑,但是对于任何一个人,我们都保证总是找到一对。 一旦有了完整的解决方案集,就可以通过首先形成所有的副产品,然后使用共均衡器构造一个终端对象来构造正确的伴随物。 真正有趣的是,在某些情况下,我们可以仅使用解集的协积来近似伴随(因此跳过均衡器部分)。 想法是,在特定程序中,我们不需要表示所有可能的函数类型,而仅表示其中的一小部分。我们也不会对唯一性感到特别担心:如果同一函数最终具有多个语法表示形式,那也没问题。 让我们用编程术语来重新表述Freyd对函数对象的构造。解决方案集是类型和功能的集合 这样,对于任何功能 在我们的程序中感兴趣的(例如,用作另一个函数的参数)存在一个和一个函数 这样可以重写为 换句话说,每个感兴趣的功能都可以由解决方案集功能之一代替。可以始终从更通用的功能的环境中提取此标准功能的环境。 CPS转换 在连续传递变换的上下文中显示了高阶函数的特定应用。让我们看一个简单的例子。我们将实现一个函数,该函数遍历包含字符串的二叉树,并将它们全部连接成一个字符串。这是树 数据树=叶子字符串 |节点树字符串树 递归遍历非常简单 show1 ::树->字符串 show1(叶s)=s show1(节点l s r)= show1 l s show1 r 我们可以在一棵小树上对其进行测试: 树::树 树=节点(节点(叶子“ 1”),“ 2”(叶子“ 3”)) “ 4” (叶子“ 5”) 测试=show1树 只有一个问题:递归消耗了运行时堆栈,该堆栈通常是有限的资源。您的程序可能耗尽堆栈空间,从而导致“堆栈溢出”运行时错误。这就是为什么编译器将递归转化为迭代的原因。而且,如果函数是尾部递归,则始终是可能的,也就是说,递归调用是函数中的最后一个调用。尾部递归函数中不允许对递归调用的结果进行任何操作。 在show1的实现中显然没有发生这种情况:在进行递归调用以遍历左侧子树之后,我们仍然必须再次调用以遍历右侧子树,并且两个结果必须与节点的内容串联在一起。 请注意,这不仅是功能编程问题。在命令式语言(以迭代为规则)中,仍然使用递归来实现树遍历。那是因为数据结构本身是递归的。过去,实现非递归树遍历是一个常见的访谈问题,但解决方案始终是显式实现自己的堆栈(我们将在本文结尾处看到它的完成方式)。 有一个标准过程可以使用连续传递样式(CPS)使函数尾部递归。这个想法很简单:如果与函数调用的结果有关,请让我们正在调用的函数代替。这种“要做的事情”被称为延续。我们正在调用的函数将延续作为参数,并且当它完成工作时,将其与结果一起调用。延续是一个函数,因此CPS转换的函数必须是高阶的:它们必须接受函数作为参数。通常,延续是在现场使用lambda定义的。 这是CPS转换后的树遍历。它不接受返回的字符串,而是接受连续符k,该函数接受字符串并产生类型a的最终结果。 show2 ::树->(字符串-> a)-> a show2(叶s)k=k s show2(节点lft s rgt)k= show2 lft( ls-> show2 rgt( rs-> k(ls s rs)) 如果树只是叶子,则show2会使用存储在叶子中的字符串来调用延续。 如果树是节点,则show2递归调用自身以转换左子项lft。这是一个尾声,其结果仅需完成。而是将其余工作打包到lambda中,并作为续集传递给show2。这是lambda ls-> show2 rgt( rs-> k(ls s rs)) 遍历左孩子的结果将调用此lambda。然后它将使用合适的孩子和另一个lambda调用show2 rs-> k(ls s rs) 同样,这是一个尾声。此lambda期望使用遍历正确子级的结果的字符串。它连接左字符串,当前节点中的字符串和右字符串,并用其调用原始延续k。 最后,要转换整个树t,我们用一个琐碎的延续调用show2,它接受最终结果并立即返回它。 show t=show2 t( x-> x) 关于lambda作为延续没有什么特别的。可以将它们替换为命名函数。区别在于,lambda可以从其环境隐式捕获值。命名函数必须明确捕获它们。我们在CPS转换遍历中使用的三个lambda可以替换为三个命名函数,每个命名函数都带有一个附加参数,表示从环境中捕获的值: 完成s=s next(s,rgt,k)ls=show3 rgt(conc(ls,s,k)) 浓度(ls,s,k)rs=k(ls s rs) 完成的第一个功能是身份功能,它强制将通用类型a缩小为String。 这是使用命名函数和显式捕获的修改后的遍历。 show3 ::树->(字符串-> a)-> a show3(叶s)k=k s show3(节点lft s rgt)k= show3 lft(下一个(s,rgt,k)) show t=show3 t完成 现在,我们可以开始与伴随定理的先前讨论建立联系。我们刚刚定义,完成,下一步和一致的三个功能构成了这个家族 。 它们是两个自变量或一对自变量的函数。第一个参数表示object,是解决方案集的一部分。它对应于闭包捕获的环境。这三个分别是 () (字符串,树,字符串->字符串) (字符串,字符串,字符串->字符串) (注意完成的空环境,这里表示为单元类型()。) 这三个函数的第二个参数的类型都是String,返回类型也是String,因此根据弗雷德定理,我们正在定义函数对象,其中String是String。 去功能化 这是有趣的部分:我们可以使用解决方案集元素的协积来近似定义通用函数类型,而不是定义String-> String。在这里,sum类型的三个组成部分对应于我们的三个函数所捕获的环境。 数据Kont=完成 |下一串树Kont | Conc String String Kont 从此求和类型与字符串配对的函数近似得出附加的余数,并返回一个字符串 apply :: Kont->字符串->字符串 应用完成s=s Apply(下一个s rgt k)ls=show4 rgt(Conc ls s k) apply(Cons ls s k)rs=Apply k(ls s rs) 与其传递三个函数之一到高阶CPS遍历,不如传递这个和类型 show4 ::树-> Kont->字符串 show4(Leaf s)k=应用k s show4(节点lft s rgt)k= show4 lft(下一个s rgt k) 这就是我们执行它的方式 show t=show4 t完成 通过使用配备了apply函数的数据类型替换它们的函数参数,我们摆脱了所有高阶函数。在几种情况下这是有利的。在过程语言中,可以使用去功能化以循环代替递归。实际上,Kont数据结构可以看作是用户定义的堆栈,特别是如果将其重写为列表。 输入Kont=[(String, Either Tree String)] 在这里,将Done替换为空列表,并且Next和Conc一起对应于将值压入堆栈。 在Haskell中,编译器执行尾部递归优化,但是去功能化在实现分布式系统或Web服务器中仍然有用。每当我们需要在客户端和服务器之间传递函数时,我们都可以用易于序列化的数据类型替换它。 参考书目 John C. Reynolds,高阶编程语言的定义解释器 James Koppel,您从未听说过的最佳重构。 Read More […]
August 5, 2020 at 7:07 am
I’m glad somebody is paying attention :-). Fixed the first one, but the second one is actually an adjunction between endofunctors, so there’s only one category there.
August 22, 2020 at 5:31 am
[…] Перевод статьи Бартоша Милевски «Defunctionalization and Freyd Theorem» (исходный текст расположен по адресу — Текст оригинальной статьи). […]
September 25, 2020 at 10:21 pm
That‘s very fascinating stuff. The sentence „You can‘t serialize functions“ is still resonating in my head, because it defines the border between logistics and informatics at the transport level. In logistics you are able to transport functionality, in informatics you aren‘t. Serialization has this strange triple face of making „things“ transportable a n d storable a n d the potential to elicit effects at a remote target (when there‘s a translation mechanism over there). RNA and DNA for instance can easily be seen as sum types: Guanin or Adenin or Cytosin or Uracil(Thymin). They build up a series. But in this chain there are hidden product types (triples), that now can be translated into functional objects: proteins. So „defunctionalization“ must have been also a biological process a long time ago, that lead to life in its known form. There is a necessity to introduce Category Theory into Biology.
September 26, 2020 at 9:14 pm
Functions are just a way to describe common/repeated code. In many ISAs there is no function-call operation, just jumps and stack push/pop type operations. Once you link the code in order to run it the call boundaries can be hard to see.