This is part 13 of Categories for Programmers. Previously: Limits and Colimits. See the Table of Contents.
Monoids are an important concept in both category theory and in programming. Categories correspond to strongly typed languages, monoids to untyped languages. That’s because in a monoid you can compose any two arrows, just as in an untyped language you can compose any two functions (of course, you may end up with a runtime error when you execute your program).
We’ve seen that a monoid may be described as a category with a single object, where all logic is encoded in the rules of morphism composition. This categorical model is fully equivalent to the more traditional set-theoretical definition of a monoid, where we “multiply” two elements of a set to get a third element. This process of “multiplication” can be further dissected into first forming a pair of elements and then identifying this pair with an existing element — their “product.”
What happens when we forgo the second part of multiplication — the identification of pairs with existing elements? We can, for instance, start with an arbitrary set, form all possible pairs of elements, and call them new elements. Then we’ll pair these new elements with all possible elements, and so on. This is a chain reaction — we’ll keep adding new elements forever. The result, an infinite set, will be almost a monoid. But a monoid also needs a unit element and the law of associativity. No problem, we can add a special unit element and identify some of the pairs — just enough to support the unit and associativity laws.
Let’s see how this works in a simple example. Let’s start with a set of two elements, {a, b}. We’ll call them the generators of the free monoid. First, we’ll add a special element e to serve as the unit. Next we’ll add all the pairs of elements and call them “products”. The product of a and b will be the pair (a, b). The product of b and a will be the pair (b, a), the product of a with a will be (a, a), the product of b with b will be (b, b). We can also form pairs with e, like (a, e), (e, b), etc., but we’ll identify them with a, b, etc. So in this round we’ll only add (a, a), (a, b) and (b, a) and (b, b), and end up with the set {e, a, b, (a, a), (a, b), (b, a), (b, b)}.

In the next round we’ll keep adding elements like: (a, (a, b)), ((a, b), a), etc. At this point we’ll have to make sure that associativity holds, so we’ll identify (a, (b, a)) with ((a, b), a), etc. In other words, we won’t be needing internal parentheses.
You can guess what the final result of this process will be: we’ll create all possible lists of as and bs. In fact, if we represent e as an empty list, we can see that our “multiplication” is nothing but list concatenation.
This kind of construction, in which you keep generating all possible combinations of elements, and perform the minimum number of identifications — just enough to uphold the laws — is called a free construction. What we have just done is to construct a free monoid from the set of generators {a, b}.
Free Monoid in Haskell
A two-element set in Haskell is equivalent to the type Bool, and the free monoid generated by this set is equivalent to the type [Bool] (list of Bool). (I am deliberately ignoring problems with infinite lists.)
A monoid in Haskell is defined by the type class:
class Monoid m where
mempty :: m
mappend :: m -> m -> m
This just says that every Monoid must have a neutral element, which is called mempty, and a binary function (multiplication) called mappend. The unit and associativity laws cannot be expressed in Haskell and must be verified by the programmer every time a monoid is instantiated.
The fact that a list of any type forms a monoid is described by this instance definition:
instance Monoid [a] where
mempty = []
mappend = (++)
It states that an empty list [] is the unit element, and list concatenation (++) is the binary operation.
As we have seen, a list of type a corresponds to a free monoid with the set a serving as generators. The set of natural numbers with multiplication is not a free monoid, because we identify lots of products. Compare for instance:
2 * 3 = 6 [2] ++ [3] = [2, 3] // not the same as [6]
That was easy, but the question is, can we perform this free construction in category theory, where we are not allowed to look inside objects? We’ll use our workhorse: the universal construction.
The second interesting question is, can any monoid be obtained from some free monoid by identifying more than the minimum number of elements required by the laws? I’ll show you that this follows directly from the universal construction.
Free Monoid Universal Construction
If you recall our previous experiences with universal constructions, you might notice that it’s not so much about constructing something as about selecting an object that best fits a given pattern. So if we want to use the universal construction to “construct” a free monoid, we have to consider a whole bunch of monoids from which to pick one. We need a whole category of monoids to chose from. But do monoids form a category?
Let’s first look at monoids as sets equipped with additional structure defined by unit and multiplication. We’ll pick as morphisms those functions that preserve the monoidal structure. Such structure-preserving functions are called homomorphisms. A monoid homomorphism must map the product of two elements to the product of the mapping of the two elements:
h (a * b) = h a * h b
and it must map unit to unit.
For instance, consider a homomorphism from lists of integers to integers. If we map [2] to 2 and [3] to 3, we have to map [2, 3] to 6, because concatenation
[2] ++ [3] = [2, 3]
becomes multiplication
2 * 3 = 6
Now let’s forget about the internal structure of individual monoids, and only look at them as objects with corresponding morphisms. You get a category Mon of monoids.
Okay, maybe before we forget about internal structure, let us notice an important property. Every object of Mon can be trivially mapped to a set. It’s just the set of its elements. This set is called the underlying set. In fact, not only can we map objects of Mon to sets, but we can also map morphisms of Mon (homomorphisms) to functions. Again, this seems sort of trivial, but it will become useful soon. This mapping of objects and morphisms from Mon to Set is in fact a functor. Since this functor “forgets” the monoidal structure — once we are inside a plain set, we no longer distinguish the unit element or care about multiplication — it’s called a forgetful functor. Forgetful functors come up regularly in category theory.
We now have two different views of Mon. We can treat it just like any other category with objects and morphisms. In that view, we don’t see the internal structure of monoids. All we can say about a particular object in Mon is that it connects to itself and to other objects through morphisms. The “multiplication” table of morphisms — the composition rules — are derived from the other view: monoids-as-sets. By going to category theory we haven’t lost this view completely — we can still access it through our forgetful functor.
To apply the universal construction, we need to define a special property that would let us search through the category of monoids and pick the best candidate for a free monoid. But a free monoid is defined by its generators. Different choices of generators produce different free monoids (a list of Bool is not the same as a list of Int). Our construction must start with a set of generators. So we’re back to sets!
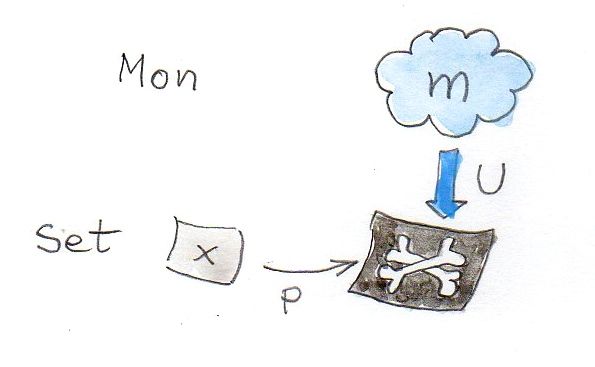
That’s where the forgetful functor comes into play. We can use it to X-ray our monoids. We can identify the generators in the X-ray images of those blobs. Here’s how it works:
We start with a set of generators, x. That’s a set in Set.
The pattern we are going to match consists of a monoid m — an object of Mon — and a function p in Set:
p :: x -> U m
where U is our forgetful functor from Mon to Set. This is a weird heterogeneous pattern — half in Mon and half in Set.
The idea is that the function p will identify the set of generators inside the X-ray image of m. It doesn’t matter that functions may be lousy at identifying points inside sets (they may collapse them). It will all be sorted out by the universal construction, which will pick the best representative of this pattern.
We also have to define the ranking among candidates. Suppose we have another candidate: a monoid n and a function that identifies the generators in its X-ray image:
q :: x -> U n
We’ll say that m is better than n if there is a morphism of monoids (that’s a structure-preserving homomorphism):
h :: m -> n
whose image under U (remember, U is a functor, so it maps morphisms to functions) factorizes through p:
q = U h . p
If you think of p as selecting the generators in m; and q as selecting “the same” generators in n; then you can think of h as mapping these generators between the two monoids. Remember that h, by definition, preserves the monoidal structure. It means that a product of two generators in one monoid will be mapped to a product of the corresponding two generators in the second monoid, and so on.

This ranking may be used to find the best candidate — the free monoid. Here’s the definition:
We’ll say that m (together with the function p) is the free monoid with the generators x if and only if there is a unique morphism h from m to any other monoid n (together with the function q) that satisfies the above factorization property.
Incidentally, this answers our second question. The function U h is the one that has the power to collapse multiple elements of U m to a single element of U n. This collapse corresponds to identifying some elements of the free monoid. Therefore any monoid with generators x can be obtained from the free monoid based on x by identifying some of the elements. The free monoid is the one where only the bare minimum of identifications have been made.
We’ll come back to free monoids when we talk about adjunctions.
Challenges
- You might think (as I did, originally) that the requirement that a homomorphism of monoids preserve the unit is redundant. After all, we know that for all
ah a * h e = h (a * e) = h a
So
h eacts like a right unit (and, by analogy, as a left unit). The problem is thath a, for allamight only cover a sub-monoid of the target monoid. There may be a “true” unit outside of the image ofh. Show that an isomorphism between monoids that preserves multiplication must automatically preserve unit. - Consider a monoid homomorphism from lists of integers with concatenation to integers with multiplication. What is the image of the empty list
[]? Assume that all singleton lists are mapped to the integers they contain, that is[3]is mapped to 3, etc. What’s the image of[1, 2, 3, 4]? How many different lists map to the integer 12? Is there any other homomorphism between the two monoids? - What is the free monoid generated by a one-element set? Can you see what it’s isomorphic to?
Next: Representable Functors.
Acknowledgments
I’d like to thank Gershom Bazerman for checking my math and logic, and André van Meulebrouck, who has been volunteering his editing help throughout this series of posts.
Follow @BartoszMilewski

July 23, 2015 at 9:00 am
I do not see which freemon rule is broken in 2*3=6, why should [2,3] equal [6]? Is it the problem that mapping is not one-to-one?
It is left unclear which morphims are meant in
let's look at individual monoids as objects with corresponding morphisms. Are you talking about relations within objects or between objects?and
Do you mean that we can come up with composition rules that are Set-based rather than monoid-based, and, thus, do not care about preserving monoid structures? My initial impression was that morhpisms in Mon need to be homomprphic, preserving the structure of the source monoids and composability you are talking about must comply this. Whereas this seems difficult if forgetful functors cannot recover the structure.
The intro explaining that Monoids stand for single untyped type in type system is brilliant.
The catch in challenge seems to be that [] = [1], which fails the isomorphism.
July 23, 2015 at 1:01 pm
@Valentin: I rewrote some paragraphs. Does it make it clearer?
I’m not sure what catch you’re talking about.
September 4, 2015 at 6:56 pm
This should be named “Part 13”, not “Part 12”.
September 5, 2015 at 12:53 am
Fixed!
September 8, 2015 at 2:54 pm
There is no link to “Representable Functors” yet
September 9, 2015 at 6:28 am
This confused me as well. The natural numbers do form a monoid under multiplication (right?). I think the point is it’s not a free monoid as you can’t choose a finite set of generators, though couldn’t you choose the primes as an infinite set of generators and under multiplication and end up with a free monoid of naturals that way?
September 13, 2015 at 8:08 pm
@Sam: The simplest counterexample is that in the monoid of natural numbers with multiplication you identify 23 with 32. This identification does not follow from monoid laws, so it’s not a free monoid.
October 4, 2015 at 4:17 pm
I find the first challenge confusing: it’s too trivial! In this section you say that a monoid homomorphism “must map unit to unit”. In the challenge you define a monoid isomorphism as a certain type of monoid homomorphism. Therefore, it “must map unit to unit”. What is there to prove? Am I missing something?
October 4, 2015 at 4:57 pm
Thinking about your last reply to Sam, it occurs to me that there are least two quite different ways in which “freedom” is lost in going from the monoid of lists of integers (LoI) to the monoid of integer multiplication (IM). The first one comes from forgetting the ordering of entries in the lists of integers (which, BTW, is not specific to integers at all), the second one comes from applying integer multiplication to the elements of the list. This suggests that the mapping from LoI to IM factors through a mapping from LoI to a third monoid X, for which I don’t have a good name. X is the monoid one gets from LoI by identifying all lists of integers that “hold the same elements” (i.e. disregarding order, but preserving repetitions; e.g. the lists [1, 2, 1] and [2, 1, 1] are treated as equivalent, but the lists [1, 2, 1] and [1, 2] are still considered distinct). The “multiplication” for this X monoid could still be ++, but it could be something more elaborate, like ++ followed by sorting.
As I mentioned, this order-forgetting business is not specific to integers. In fact, one can envision a new type constructor, Multiset, that takes a type as an argument, and returns the type Multiset-of-a. (A multiset is like a list, except that equality of multisets disregards the ordering of elements.) With these definitions, Multiset is a functor analogous to the List functor, and the “forgetting-of-ordering” map described earlier is the integer component of a natural transformation from List to Multiset.
October 4, 2015 at 5:00 pm
This sentence I wrote is confusing:
I meant to write
Sorry for this ineptitude.
October 4, 2015 at 9:33 pm
Yes, challenge 1 was a result of editing the original one after an error was discovered and, as we all know, a quick bug fix usually results in a new bug. I hope the new version makes more sense.
October 4, 2015 at 9:51 pm
@weekendwarrior: What you are suggesting is based on the distinction between a non-Abelian monoid of lists (with concatenation) and the Abelian monoid of integers (with multiplication).” Abelian” just means commutative. The process of identifying lists that only differ by the order of elements is called “taking a quotient.”
November 27, 2015 at 8:01 pm
I’m learning category theory. Your explanation about the monoid is very intuitive and helpful. Thank you!
February 6, 2016 at 1:33 am
[…] You can read this very beautiful article of Bartosz Milewski: Free Monoids. […]
October 16, 2017 at 10:16 am
[…] В результате получается последовательность, содержащая оба числа. В данный момент, мы еще не потеряли никакой информации, поэтому как только будет понятен способ комбинирования этих чисел, нужно будет просто вычислить собранные ранее данные. Это называется свободным моноидом. […]
November 19, 2017 at 1:47 am
In Haskell, a list can be constructed with a recursive data structure like this:
data List a = List (List a) a | NilList
I have determined through experimentation that a similar but doubly recursive data structure will construct a rose tree:
data Tree a = Tree (Tree a) (Tree a) a | NilList
This is like saying, for each point in the data structure, there are two free monoids that are sitting side-by-side. In category theory, would a rose tree be considered the product of the free monoid with itself?
November 19, 2017 at 2:16 am
I realized after I wrote this that the tree data structure that I gave as an example is actually a binary tree. The data structure to build a rose tree looks like this:
data Tree a = Tree [Tree a] a | NilTree
So, for every point in the data structure, there is a variable number of branches.
The list could be thought of as a one-branch tree and also corresponds to the free monoid m. The binary tree could be considered the product of m with itself aka m^2. A tree with three branches at each node would be m^3. A rose tree has a variable branches at each node corresponding to (m^0 + m^1 + m^2 + m^3 + …). Something tells me that a rose tree is a free monoid in a 2-category.
Am I on the right track? Can you shed any light on all of this?
November 19, 2017 at 4:14 am
Actually, a binary tree is a free magma. See https://www.schoolofhaskell.com/user/bss/magma-tree .
November 22, 2017 at 6:54 pm
Reading your book often results in eureka moments for me.
Here is one I would like to share
(I am even using q to match your notation):
foldMap :: Monoid m => (a -> m) -> [a] -> m
foldMap q = foldr mappend mempty . map q
Read this as: given monoid ‘m’, set of generators ‘a’,
function ‘q’ that selects generators in ‘m’, I can compute a homomorphism
‘[a] -> m’ that factorizes q.
I did not look at foldMap from that angle before!
https://github.com/rpeszek/notes-milewski-ctfp-hs/wiki/N_P2Ch03_FreeMonoidFoldMap
(computed morphism is a homomorphism by construction/implementation, but it looks like something forced by parametricity – theorem for free)
April 16, 2018 at 4:18 pm
Thank you for your work! This is priceless!
Would it be correct to say that a free monoid on integers under addition (maybe even multiplication) has a set of prime numbers as an underlying set?
Thank you!
April 16, 2018 at 4:35 pm
A free monoid whose generators are prime numbers consists of lists of such numbers. You could try to say it’s isomorphic to natural numbers (without zero) but you’d have to identify all lists that are permutations of each other (e.g., [2, 3] with [3, 2]).
October 18, 2018 at 7:10 am
I have a question to be sure I understood correctly. Is x the generator set for the monoid m, like {a, b} and Um the set of elements of m like {e, a, b, (a, a), (a, b), (b, a), (b, b), … }? And Uh a function that potentially further identifies some elements from Um, creating a Un set for a non-free monoid? Ty
October 20, 2018 at 10:33 pm
Sorry if I don’t make any sense… Could you please give a simple example of your choosing for the “actors” involved in the best candidate diagram for a free monoid? My problem is that I think I understand all, but it’s quite possible that I did not get it at all 🙂 Thank you
October 21, 2018 at 9:07 am
@Bogdan: I’m sorry, I don’t understand your question.
October 22, 2018 at 12:25 am
Let me try to give an example to be sure I understood correctly
x = {a, b}
Um = {e, a, b, (a, a), (a, b), (b, a), (b, b), … }
m = free monoid together with p : x -> Um
Un = {e, a, b, (a, a), (a, b), (b, b), … } // we have commutativity also, and
// further identify (a,b) with (b, a)
n = a non free monoid
Is Uh : Um -> Un kind of a co-limit, and the free monoid m is kind of like an initial object for the monoids generated from x, where m has the minimum number of identifications?
October 22, 2018 at 10:22 am
Let’s rewrite your Un as {1, 2, 3, 4 (=2 * 2), 6 (=2 * 3), 9 (=3 * 3), … } . Notice that 2 * 3 is the same as 3 * 2. The mapping Uh maps e->1, a->2, b->3, (a, a)->4, etc. The identification I’m talking about is, for instance, in (a, b)->6 and (b, a)->6. These are two different elements in Um mapped to the same element in Un.
October 23, 2018 at 1:04 am
Great! Thank you for not giving up on me 🙂
October 19, 2019 at 9:17 am
Bartosz, is the goal of free monoid universal construction to find the free monoid with the least baggage “m”, given the specific set of generators x?
Thanks in advance.
October 25, 2019 at 1:52 pm
I’m having trouble with this excerpt:
“Remember that h, by definition, preserves the monoidal structure. It means that a product of two generators in one monoid will be mapped to a product of the corresponding two generators in the second monoid, and so on.”
I can’t find any source about monoids online that says that for a given homomorphism h from m to n, that if a is a generator of m that h(a) is a generator of n. In this case, why would there necessarily be a “corresponding two generators?”
October 25, 2019 at 10:36 pm
Maybe you’re reading too much into it. I’m just calling the image of the elements of the set x “generators”. They do generate the whole free monoid, but not necessarily everything in the other monoids we’re comparing with. There they just generate sub-monoids.
December 19, 2019 at 12:57 am
The universal construction of free monoid seems like a colimit.
I try to reinterpret free monoid by colimit as follow:
I define a new category C, there are two parts in this category C.
The first part is the image of forgetful functor U : Mon -> Set. It means that the objects are all and only underlying sets of monoids, the morphisms are all and only homomorphisms (no other weird functions)
The second part is the generators set x equipped with all functions from x to those underlying sets.
In this category C, I can find a “colimit” of x. (The diagram of this “colimit” is the generators set x.)
This “colimit” is the free monoid of generators set x.
The problem is that it is not actually colimit, because the actually colimit of x in C is the generators set x itself. (It seems like “the next colimit of x in C” or “need to exclude x” or “need to exclude identity function at x”)
The question is:
Is there any strict categorical language that can explain free monoid using colimit?
Thanks.
December 21, 2019 at 5:11 pm
When you say “no other weird functions” you are really defining the category of monoids. From the categorical point of view, it doesn’t matter if you call your objects monoids or sets, they are atoms with no structure. The difference between a monoid and a set is in the morphisms to and from it. It’s the choice of morphisms that is the essence of objects.
December 23, 2019 at 9:13 am
Yes, as you said that I are really defining the category of monoids ….
But what I really want to do is to define a special category, and use limit to define a free monoid in that category.
For example, the category C which I defined above is very much like the category Set, except I manually removed the “weird functions”. This is why I tell them functions instead of morphisms or arrows.
Yes, it is very like traditional mathematics using set theory: We define a collection of all monoids, every monoid is a set, we define binary operation on it, functions between two monoids are homomorphisms… In this category or collection, I want to use “limit” mechanism to define free monoid.
I may have mixed set theory and category theory, it seems to be a wrong approach, so I’m sorry…(Don’t see it again).