Category theory extracts the essence of structure and composition. At its foundation it deals with the composition of arrows. Building on composition of arrows it then goes on describing the ways objects can be composed: we have products, coproducts and, at a higher level, tensor products. They all describe various modes of composing objects. In monoidal categories any two objects can be composed.
Unlike composition, which can be described uniformly, decomposition requires case-by-case treatment. It’s easy to decompose a cartesian product using projections. A coproduct (sum) can be decomposed using pattern matching. A generic tensor product, on the other hand, has no standard means of decompositon.
Optics is the essence of decomposition. It answers the question of what it means to decompose a composite.
We consider an object decomposable when:
- We can split it into the focus and the complement,
- We can replace the focus with something else, without changing the complement, to get a new composite object,
- We can zoom in; that is, if the focus is decomposable, we can compose the two decompositions,
- It’s possible for the whole object to be the focus.
Let’s translate these requirements into the language of category theory. We’ll start with the standard example: the lens, which is the optic for decomposing cartesian products.
The splitting means that there is a morphism from the composite object 
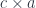



To replace the focus we need another morphism that takes the same complement 
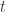

Here’s the important observation: We don’t care what the complement is. We are “focusing” on the focus. We carry the complement over to combine it with the new focus, but we don’t use it for anything else. It’s a featureless black box.
To erase the identity of the complement, we hide it inside a coend. A coend is a generalization of a sum, so it is written using the integral sign (see the Appendix for details). Programmers know it as an existential type, logicians call it an existential quantifier. We say that there exists a complement
Here’s the existential definition of the lens:
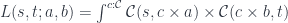
Just like we construct a coproduct using one of the injections, so the coend is constructed using one of (possibly infinite number of) injections. In our case we construct a lens 
It’s not immediately obvious that this representation of the lens reproduces the standard setter/getter form. However, in a cartesian closed category, we can use the currying adjunction to transform the second hom-set:
![\mathcal{C}(c \times b, t) \cong \mathcal{C}(c, [b, t])](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BC%7D%28c+%5Ctimes+b%2C+t%29+%5Ccong+%5Cmathcal%7BC%7D%28c%2C+%5Bb%2C+t%5D%29&bg=ffffff&fg=29303b&s=0&c=20201002)
Here, ![[b, t]](https://s0.wp.com/latex.php?latex=%5Bb%2C+t%5D&bg=ffffff&fg=29303b&s=0&c=20201002)
![\int^{c : \mathcal{C}} \mathcal{C}(s, c \times a) \times \mathcal{C}(c, [b, t]) \cong \mathcal{C}(s, [b, t] \times a) \cong \mathcal{C}(s \times b, t) \times \mathcal{C}(s, a)](https://s0.wp.com/latex.php?latex=%5Cint%5E%7Bc+%3A+%5Cmathcal%7BC%7D%7D+%5Cmathcal%7BC%7D%28s%2C+c+%5Ctimes+a%29+%5Ctimes+%5Cmathcal%7BC%7D%28c%2C+%5Bb%2C+t%5D%29+%5Ccong+%5Cmathcal%7BC%7D%28s%2C+%5Bb%2C+t%5D+%5Ctimes+a%29+%5Ccong+%5Cmathcal%7BC%7D%28s+%5Ctimes+b%2C+t%29+%5Ctimes+%5Cmathcal%7BC%7D%28s%2C+a%29&bg=ffffff&fg=29303b&s=0&c=20201002)
The first part of this product is the setter: it takes the source object
Even though all optics have similar form, each of them reduces differently.
Here’s another example: the prism. We just replace the product with the coproduct (sum).

This time the reduction goes through the universal property of the coproduct: a mapping out of a sum is a product of mappings:
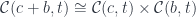
Again, we use the co-Yoneda to reduce the coend:
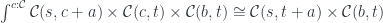
The first one extracts the focus
We can easily generalize existential optics to an arbitrary tensor product in a monoidal category:

In general, though, this form cannot be further reduced using the co-Yoneda trick.
But what about the third requirement: the zooming-in property of optics? In the case of the lens and the prism it works because of associativity of the product and the sum. In fact it works for any tensor product. If you can decompose 


Focusing on the whole object plays the role of the unit of zooming.
These two properties are used in the definition of the category of optics. The objects in this category are pairs of object in 

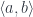

But this is still not the most general setting. The useful insight is that the multiplication (product) in a lens, and addition (coproduct) in a prism, look like examples of linear transformations, with the residue
The idea is that you define a family of endofunctors 

The zooming principles are satisfied if the action respects the tensor product in
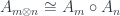

(Here, 
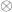

The actegorical version of the optic doesn’t deal directly with the residue. It tells us that the “unimportant” part of the composite object can be parameterized by some 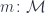
This additional abstraction allows us to transport the residue between categories. It’s enough that we have one action 


The separation of the focus from the complement using monoidal actions is reminiscent of what physicists call the distinction between “physical” and “gauge” degrees of freedom.
An in-depth presentation of optics, including their profunctor representation, is available in this paper.
Appendix: Coends and the Co-Yoneda Lemma
A coend is defined for a profunctor, that is a functor of two variables, one contravariant and one covariant, 

Co-Yoneda lemma is the identity that works for any covariant functor (copresheaf) 
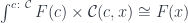
September 9, 2021 at 5:53 am
Bartosz, your articles are damn-difficult to read (:->), but I always learn something (although usually less than you expect/intend).
My request is that you relate your examples to some more conventional structures.
One we use, because it is widely used, is the JSON-LD notation and registration of ‘categories’ using different ontologies.
The most widely used ontology (although most users do not think of it as an ‘ontology’) is schema.org.
The core datatypes are immutable categories. We can translate your concepts to a combination of JSON-LD and schema.org (sprinkled with the addition of other RDF datasets like US NIH PubChem and EMBL ChEBI).
We can build complex expressions by linking categories (won’t go further on this point because I’m not trying to sell you an alternative).
Just a suggestion from a less sophisticated student who tries to apply your ideas about category theory to real-world applications.
September 9, 2021 at 11:36 am
This particular article was written specifically for category theorists. I have several earlier posts explaining these thing for programmers. As far as databases are concerned, I know too little about it. You might want to look at the work of David Spivak and Brendan Fong.
September 15, 2021 at 6:03 am
Bartosz, I am curious about your physics analogy. If I understand you correctly, you are comparing the monoidal action parametrized by m to gauge transformations parametrized by some spacetime point x. And that we then “sum” over m just like we integrate over x in the action?
Are you suggesting gauge theory can be thought of as an optic? Or vice-versa? Or both? 🙂
Anyway I would be glad to hear you elaborate on the subject.
September 15, 2021 at 10:09 am
I’m comparing monoidal action to gauge transformation, say U(1) for electromagnetic field, or SU(3) color for strong interactions. A field is a section of a bundle whose base is the spacetime, and the fiber carries a representation of this group.