What does Gödel’s incompletness theorem, Russell’s paradox, Turing’s halting problem, and Cantor’s diagonal argument have to do with the fact that negation has no fixed point? The surprising answer is that they are all related through
Lawvere’s fixed point theorem.
Before we dive deep into category theory, let’s unwrap this statement from the point of view of a (Haskell) programmer. Let’s start with some basics. Negation is a function that flips between True and False:
not :: Bool -> Bool not True = False not False = True
A fixed point is a value that doesn’t change under the action of a function. Obviously, negation has no fixed point. There are other functions with the same signature that have fixed points. For instance, the constant function:
true True = True true False = True
has True as a fixed point.
All the theorems I listed in the preamble (and a few more) are based on a simple but extremely powerful proof technique invented by Georg Cantor called the diagonal argument. I’ll illustrate this technique first by showing that the set of binary sequences is not countable.
Cantor’s job interview question
A binary sequence is an infinite stream of zeros and ones, which we can represent as Booleans. Here’s the definition of a sequence (it’s just like a list, but without the nil constructor), together with two helper functions:
data Seq a = Cons a (Seq a)
deriving Functor
head :: Seq a -> a
head (Cons a as) = a
tail :: Seq a -> Seq a
tail (Cons a as) = as
And here’s the definition of a binary sequence:
type BinSeq = Seq Bool
If such sequences were countable, it would mean that you could organize them all into one big (infinite) list. In other words we could implement a sequence generator that generates every possible binary sequence:
allBinSeq :: Seq BinSeq
Suppose that you gave this problem as a job interview question, and the job candidate came up with an implementation. How would you test it? I’m assuming that you have at your disposal a procedure that can (presumably in infinite time) search and compare infinite sequences. You could throw at it some obvious sequences, like all True, all False, alternating True and False, and a few others that came to your mind.
What Cantor did is to use the candidate’s own contraption to produce a counter-example. First, he extracted the diagonal from the sequence of sequences. This is the code he wrote:
diag :: Seq (Seq a) -> Seq a diag seqs = Cons (head (head seqs)) (diag (trim seqs)) trim :: Seq (Seq a) -> Seq (Seq a) trim seqs = fmap tail (tail seqs)
You can visualize the sequence of sequences as a two-dimensional table that extends to infinity towards the right and towards the bottom.
T F F T ... T F F T ... F F T T ... F F F T ... ...
Its diagonal is the sequence that starts with the fist element of the first sequence, followed by the second element of the second sequence, third element of the third sequence, and so on. In our case, it would be a sequence T F T T ....
It’s possible that the sequence, diag allBinSeq has already been listed in allBinSeq. But Cantor came up with a devilish trick: he negated the whole diagonal sequence:
tricky = fmap not (diag allBinSeq)
and ran his test on the candidate’s solution. In our case, we would get F T F F ... The tricky sequence was obviously not equal to the first sequence because it differed from it in the first position. It was not the second, because it differed (at least) in the second position. Not the third either, because it was different in the third position. You get the gist…
Power sets are big
In reality, Cantor did not screen job applicants and he didn’t even program in Haskell. He used his argument to prove that real numbers cannot be enumerated.
But first let’s see how one could use Cantor’s diagonal argument to show that the set of subsets of natural numbers is not enumerable. Any subset of natural numbers can be represented by a sequence of Booleans, where True means a given number is in the subset, and False that it isn’t. Alternatively, you can think of such a sequence as a function:
type Chi = Nat -> Bool
called a characteristic function. In fact characteristic functions can be used to define subsets of any set:
type Chi a = a -> Bool
In particular, we could have defined binary sequences as characteristic functions on naturals:
type BinSeq = Chi Nat
As programmers we often use this kind of equivalence between functions and data, especially in lazy languages.
The set of all subsets of a given set is called a power set. We have already shown that the power set of natural numbers is not enumerable, that is, there is no function:
enumerate :: Nat -> Chi Nat
that would cover all characteristic functions. A function that covers its codomain is called surjective. So there is no surjection from natural numbers to all sequences of natural numbers.
In fact Cantor was able to prove a more general theorem: for any set, the power set is always larger than the original set. Let’s reformulate this. There is no surjection from the set 

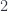
To prove this, let’s be contrarian and assume that there is a surjection:
enumP :: A -> Chi A
Since we are going to use the diagonal argument, it makes sense to uncurry this function, so it looks more like a table:
g :: (A, A) -> Bool g = uncurry enumP
Diagonal entries in the table are indexed using the following function:
delta :: a -> (a, a) delta x = (x, x)
We can now define our custom characteristic function by picking diagonal elements and negating them, as we did in the case of natural numbers:
tricky :: Chi A tricky = not . g . delta
If enumP is indeed a surjection, then it must produce our function tricky for some value of x :: A. In other words, there exists an x such that tricky is equal to enumP x.
This is an equality of functions, so let’s evaluate both functions at x (which will evaluate g at the diagonal).
tricky x == (enumP x) x
The left hand side is equal to:
tricky x = {- definition of tricky -}
not (g (delta x)) = {- definition of g -}
not (uncurry enumP (delta x)) = {- uncurry and delta -}
not ((enumP x) x)
So our assumption that there exists a surjection A -> Chi A led to a contradition!
not ((enumP x) x) == (enumP x) x
Real numbers are uncountable
You can kind of see how the diagonal argument could be used to show that real numbers are uncountable. Let’s just concentrate on reals that are greater than zero but less than one. Those numbers can be represented as sequences of decimal digits (the digits following the decimal point). If these reals were countable, we could list them one after another, just like we attempted to list all streams of Booleans. We would get some kind of a table infinitely extending to the right and towards the bottom. There is one small complication though. Some numbers have two equivalent decimal representations. For instance 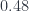
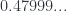
3 5 0 5 ... 9 9 0 8 ... 4 0 2 3 ... 0 0 9 9 ... ...
We can now apply our diagonal argument by picking one digit from every row. These digits form our diagonal number. In our example, it would be 3 9 2 9.
In the previous proof, we negated each element of the sequence to get a new sequence. Here we have to come up with some mapping that changes each digit to something else. For instance, we could add one to it, modulo nine. Except that, again, we don’t want to produce nines, because we could end up with a number that ends in an infinity of nines. But something like this will work just fine:
h n = if n == 8
then 3
else (n + 1) `mod` 9
The important part is that our function h replaces every digit with a different digit. In other words, h doesn’t have a fixed point.
Lawvere’s fixed point theorem
And this is what Lawvere realized: The diagonal argument establishes the relationship between the existence of a surjection on the one hand, and the existence of a no-fix-point mapping on the other hand. So far it’s been easy to find a no-fix-point functions. But let’s reverse the argument: If there is a surjection 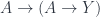

But wait a moment. Except for the trivial case of a function on a one-element set, it’s always possible to find a function that has no fixed point. Just return something else than the argument you’re called with. This is definitely true in 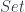
As usual, translating from the language of sets and functions to the language of category theory takes some work. The tricky part is to generalize the definition of a fixed point and surjection.
Points and string diagrams
First, to define a fixed point, we need to be able to define a point. This is normally done by defining a morphism from the terminal object 
Since things will soon get complicated, I’d like to introduce string diagrams to better visualise things in a cartesian category. In string diagrams lines correspond to objects and dots correspond to morphisms. You read such diagrams bottom up. So a morphism
can be drawn as:

I will use dotted letters to denote “points” or morphisms originating in the unit. It is also customary to omit the unit from the picture. It turns out that everything works just fine with implicit units.

A fixed point of a morphism 



And here’s the corresponding string diagram that encodes the commuting condition.

In string diagrams, morphisms are composed by stringing them along lines in the bottom up direction.
Surjections can be generalized in many ways. The one that works here is called surjection on points. A morphism 



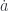

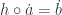

Or string-diagrammatically, for every

Currying and uncurrying
To formulate Lawvere’s theorem, we’ll replace 
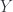
generates these rows. I will use barred symbols, like 
This is best seen after uncurrying 
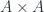
The currying relationship between these two is given by the universal construction:

with the following commuting condition:
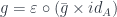
Here, 
This commuting condition can be visualized as a string diagram. Notice that products of objects correspond to parallel lines going up. Morphisms that operate on products, like 

We are interested in mappings that are point-surjective. In this case, we would like to demand that for every point 

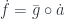
or, diagrammatically, for every 

Conceptually, 
This is a very general way of expressing what, in Haskell, would amount to: Every function f :: A -> Y can be obtained by partially applying our g_bar :: X -> A -> Y to some x :: X.
The diagonal
The way to index the diagonal of our table is to use the diagonal morphism 

By combining this diagram with the diagram that defines the lifting of a pair of points

where 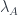


Here’s the string diagram representation of this identity:

In string diagrams we ignore unitors (as well as associators). Now you see why I like string diagrams. They make things much simpler.
Lawvere’s fixed point theorem
Theorem. (Lawvere) In a cartesian closed category, if there exists a point-surjective morphism 
Note: Lawvere actually used a weaker definition of point surjectivity.
The proof is just a generalization of the diagonal argument.
Suppose that there is an endomorphims 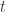
The table is described by (uncurried) 

or, in diagramatic form:

![]()
Since we were guaranteed that our table 
There is a one-to-one correspondence between points 

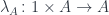

In other words, 

Since 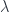

In the corresponding string diagram we omit the unitor altogether.

Now we can use our assumption that 
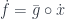

So 
Let’s work out the details.
First, let’s apply the function we’ve found in the table at row

Plugging into it the entry

Here’s the corresponding string diagram:

We can now uncurry

And replace a pair of 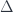

Compare this with the defining equation for


In other words, the morphism 
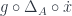
is a fixed point of
Conclusion
When I started writing this blog post I though it would be a quick and easy job. After all, the proof of Lawvere’s theorem takes just a few lines both in the original paper and in all other sources I looked at. But then the details started piling up. The hardest part was convincing myself that it’s okay to disregard all the unitors. It’s not an easy thing for a programmer, because without unitors the formulas don’t “type check.” The left hand side may be a morphism from 
One of the things I wasn’t sure about was if it was okay to slide unitors around, as in this diagram:

It turns out this is just naturality condition for
Acknowledgments
I’m grateful to Derek Elkins for reading the draft of this post.
Literature
- F. William Lawvere, Diagonal arguments and cartesian closed categories
- Noson S. Yanofsky, A Universal Approach to Self-Referential Paradoxes, Incompleteness and Fixed Points
- Qiaochu Yuan, Cartesian closed categories and the Lawvere fixed point theorem
November 7, 2019 at 8:53 pm
In fact you don’t even need the projections for the diagonal argument, merely the magmatic structure and the diagonals (which should be natural map). If currying is desired, then one can ask for (one-sided) closedness.
November 22, 2019 at 7:15 am
Hi, Bartosz,
Thank you for such a great post.
I am only half way through it and I have two questions:
I stuck at the characteristic function definition, I consider type Chi = Nat -> Bool as a homset between Nat and Bool, so there is a family of functions, which is reasonable: there is one for each subset. But I don’t quite understand why there’s no function of the type enumerate :: Nat -> Chi Nat, I can easily define it as
enumerate _ _ = True
or
enumerate a b = a == b
What is wrong with my reasoning?
Why do you unify 0.48 and 0.47999…? Is it because computers have finite precision?
November 22, 2019 at 9:18 am
The point is, there is no surjective enumeration.
The unification of the two numbers has nothing to do with computers. Decimal representation is just not unique. Think of 0.9999… It’s a limit of 0.9, 0.99, 0.999, etc. Each one is closer to 1. The first differs from 1 by 0.1, the second by 0.01, the third by 0.001, etc. In the limit the distance to 1 vanishes. So 0.999… is the same as 1.
December 23, 2019 at 12:30 am
[…] Перевод статьи Бартоша Милевски «Fixed Points and Diagonal Arguments» (исходный текст расположен по адресу — Текст оригинальной статьи). […]
January 7, 2020 at 3:33 am
“The hardest part was convincing myself that it’s okay to disregard all the unitors. It’s not an easy thing for a programmer, because without unitors the formulas don’t “type check.””
I’d be surprised if there isn’t a slick, generic, category-theoretic way* of defining a type converter in Haskell that achieves exactly this.
(waves hands furiously)